なぜ今、階層的記憶の「統一ベンチマーク」が必要なのか
大規模言語モデル(LLM)の応用が進むにつれ、「どれだけ長い文章を読めるか」だけを測るベンチマークでは実務上の品質評価が追いつかなくなっています。個人アシスタント、企業向けRAGシステム、業務エージェントなど、現代のAIシステムには情報を複数のセッションにまたがって保存・更新・検索・要約し、必要に応じて棄却する能力が求められます。これがいわゆる「階層的記憶」の問題です。
本記事では、既存ベンチマークの現状と限界を整理したうえで、統一ベンチマークを設計するための三軸モデル・評価指標・データ設計・運用体制について実務的な観点から解説します。日本語対応の空白地帯についても触れており、研究者・エンジニア・評価基盤担当者にとって参考になる内容です。
階層的記憶とは何か:三軸で定義する
単なる「長文耐性」ではない
既存研究では、AIの記憶は「短期/長期」「個人記憶/システム記憶」「パラメトリック/非パラメトリック」など、さまざまな軸で整理されてきました。MemGPTはOSの仮想メモリになぞらえた高速・低速の階層を提案し、H-MEMは意味的抽象度に応じた4層構造を採用、MemoryOSはshort/mid/long-termの3層設計を実装しています。
これらを統合すると、階層的記憶とは次のように定義できます。
異なる粒度・時間幅・抽象度・アクセスコストを持つ複数層の記憶表現を、保存・更新・圧縮・検索・推論の規則とともに扱う能力、またはそのための機構。
重要なのは、「階層」が単なる保存先の段数を意味するのではなく、どの情報をどの層へ昇格・要約・保持・忘却するかという制御規則を含む点です。
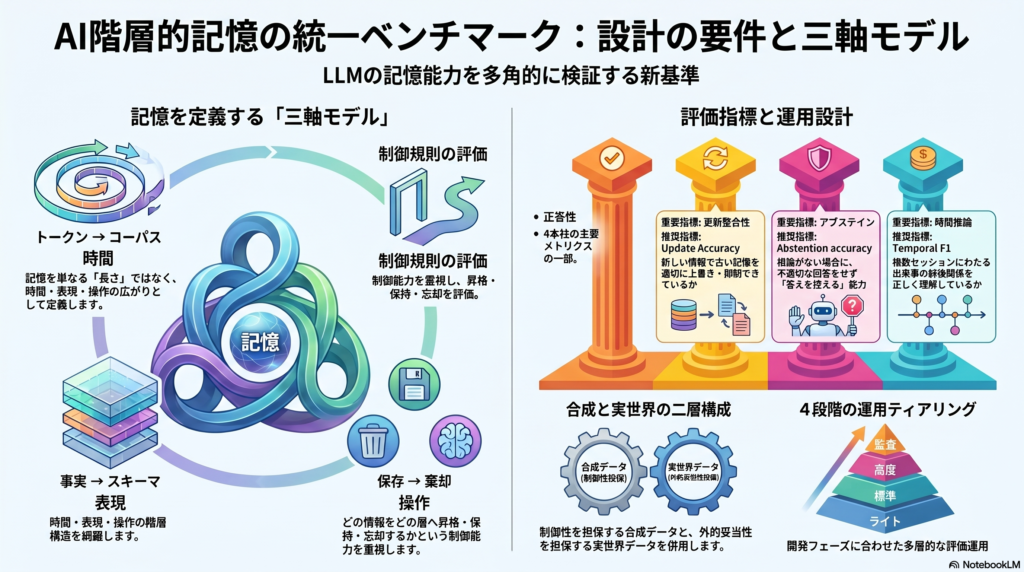
三軸モデルで整理する
統一ベンチマークの設計原則として、以下の三軸モデルが有効です。
- 時間階層:token → turn → session → trajectory → corpus
- 表現階層:span → fact → event → episode → schema / profile / workflow
- 操作階層:store → update → consolidate → retrieve → reason → abstain
この三軸で記憶を定義することで、「何を測るべきか」が具体的になります。たとえば「更新後に古い記憶を抑制できるか(操作:update / abstain)」「要約が事実を保っているか(表現:episode → schema)」「複数セッションをまたいで記憶を統合できるか(時間:session → trajectory)」といった問いが評価設計に直結します。
既存ベンチマークの現状と限界
三系統に分かれる既存研究
現状のベンチマーク群は大きく三つの系統に分かれています。
① 合成・長さストレス系: RULER、MRCR、Japanese HR NIAHなど。難易度やノイズ、針の数を制御できる反面、公式にも「realistic taskの代替にならない」と明記されており、persistent memoryは評価対象外です。
② 現実長文理解系: LongBench、LongBench v2、L-Eval、HELMET、ZeroSCROLLS、InfiniteBenchなど。実文書を用いたrealistic taskに強みがある一方、書き込み可能な記憶や長期更新は主対象ではありません。
③ 持続メモリ系: LoCoMo、LongMemEval、LongMemEval-V2など。複数セッションにまたがる会話や行動軌跡を扱い、階層的記憶の評価に最も近い系統です。
持続メモリ系の進化と残された課題
持続メモリ系の中でも特に注目されるのが、LongMemEvalからLongMemEval-V2への進化です。LongMemEvalがチャット履歴ベースの5能力(情報の記憶・更新・時系列理解・統合・棄却)を評価するのに対し、LongMemEval-V2はweb/enterprise agentの環境経験記憶を対象とし、accuracy(正確性)とquery latency(検索遅延)を同時に評価します。最大115Mトークンという規模は、評価実行コストの面でも新たな課題を提示しています。
一方、LoCoMoは高品質な長期会話データを10会話・各300ターンで提供していますが、商用利用制約があり、規模も限定的です。
日本語評価基盤の空白
日本語の文脈では、このギャップはさらに大きいと言えます。言語処理学会2026で発表された「日本語ロングコンテキスト処理能力評価ベンチマーク」は、JEMHopとNIILCをもとに初の日本語長文評価ベンチマークを構築したものですが、persistent memoryや更新評価は直接の対象ではありません。Japanese HR NIAHは人事労務ドメインに特化した完全合成データで3種のNIAH系タスクを設計していますが、統合や更新の評価には限界があります。llm-jp-evalは日本語評価の統一ツールとして重要ですが、階層的記憶そのものを対象とする枠組みではありません。
現時点では、日本語persistent-memory benchmarkは実質的に未着手に近い状態です。これは逆に言えば、設計自由度が高いという意味で標準化上の好機でもあります。
統一ベンチマークの設計要件
評価軸とメトリクス
単純な正答率だけでは、階層的記憶の能力を適切に評価できません。L-Evalはn-gram指標だけでは長文タスクの能力を反映しにくいと指摘し、HELMETはreference-basedなmodel evaluationを導入しています。以下が、統一ベンチマークに必要な最小評価セットです。
| 評価軸 | 推奨指標 | ポイント |
|---|---|---|
| 正答性 | Accuracy / EM / F1 | MC形式と自由生成を使い分ける |
| 階層再生 | Level-Conditioned Recall | どの階層で壊れているかを特定できる |
| 更新整合性 | Update Accuracy / Staleness Penalty | 古い記憶の残留を定量的に測る |
| 時間推論 | Temporal F1 / chronology accuracy | before-afterやsession orderの正答率 |
| 構造理解 | Event Graph F1 / relation consistency | event–cause–agent–timeの整合性 |
| アブステイン | Abstention accuracy / AUROC | 根拠不在時に答えを控えられるか |
| ロバストネス | Position sensitivity / distractor robustness | lost-in-the-middleや脆弱な検索を見抜く |
| スケーラビリティ | Effective Length / performance slope | context長増大時の劣化率 |
| 計算コスト | Query latency / token I/O | LongMemEval-V2の方針と整合 |
| 再現性 | seed variance / judge agreement | leaderboardの信頼性を担保 |
実運用では、公開leaderboardは「正答性・更新整合性・ロバストネス・コスト」の4本柱、研究用詳細レポートは全指標という二層構成が管理しやすいとされています。
データセット設計:合成と実世界の二層構成
データ設計において最も現実的とされるのが、合成データと実世界データの二層構成です。
- 合成データ(制御性の担保): RULER、MRCR、Japanese HR NIAH型。難易度・ノイズ・階層深さ・更新頻度を制御できる。smoke testやstress testに適する。
- 実世界データ(外的妥当性の担保): LoCoMo、LongMemEval、LongMemEval-V2型。長期会話や行動軌跡を用いた現実的なタスク。
実世界データを導入する際は、日本の個人情報保護法に沿った対応が不可欠です。具体的には、個人情報該当性の判断、仮名加工情報の削除情報等の安全管理、識別行為の禁止、利用目的の明示が求められます。また、研究データのオープン・アンド・クローズ戦略として、個人情報や競争優位に関わるデータは非公開管理が適切とされています。
タスク設計と難易度調整
タスク設計では、少なくとも以下の系統を揃えることが推奨されます。
- 生成タスク: 圧縮後も一貫した回答や要約ができるかを測る
- 検索タスク: 必要な記憶を正確に取り出せるかを測る
- 推論タスク: 複数階層の記憶を統合して回答できるかを測る
- 更新/忘却タスク: 新情報で旧情報を適切に抑制できるかを測る
- アブステインタスク: 根拠がない場合に回答を控えられるかを測る
難易度調整のノブとしては、distractor密度・needle数・hop数・跨session数・更新頻度などがあります。ベースラインは最低でも「no-memory長文モデル」「flat RAG」「summary-only」「hierarchical memory」「oracle retrieval」の5系統を揃えることが望ましいとされています。
実験プロトコルと運用設計
標準実験プロトコルの要点
統一ベンチマークが失敗しやすい最大要因は、評価仕様が曖昧で再現実行条件が固定されていないことです。実務的な標準プロトコルとして以下が推奨されます。
- Prompt固定: 各タスクでsystem/user promptをバージョン管理する
- Judge固定: judge modelの名前・バージョン・設定を固定し、更新時はbenchmarkバージョンを上げる
- Seed管理: 最低3回rerun、平均と標準偏差を報告する
- Artifact一式提出: prediction・retrieved evidence・logs・config・commit hashを同封する
- Split管理: public dev / semi-public validation / private testの三層化
特に重要なのが「retrieved evidenceの保存」です。答えが正しいかどうかだけでなく、どの層の記憶をどのように参照したかが追跡可能でなければ、改善サイクルが回りません。
多層運用tiering
実装コストの観点から、以下の4層運用が推奨されます。
- Lite tier: 合成retrieval+日本語基本タスク。開発初期のsmoke test向け。
- Standard tier: realistic long-doc+persistent chat memory。公開leaderboard向け。
- Stress tier: LongMemEval-V2類似の超長履歴・軌跡。非公開監査・論文比較向け。
- Audit tier: 人手精査subset・プライバシー監査。品質保証・ガバナンス向け。
継続的評価の仕組みとして、rotating hidden sliceの導入も有効です。公開devセットと固定public testだけでは最適化が進みすぎる問題を抑えるため、運営委員会が四半期ごとに隠しスライスを差し替える運用です。
ガバナンス原則と推奨ロードマップ
Living Documentとしての設計
日本のAI事業者ガイドラインはAIガバナンスをリスクベースアプローチで進め、Living Documentとしてマルチステークホルダーの関与のもとで継続更新する考え方を採っています。階層的記憶ベンチマークも同様に、固定規格ではなく更新可能な公共インフラとして設計すべきです。
主要なガバナンス原則は次の通りです。
- 透明性: データ出所・prompt・judge・更新履歴・既知のblind spotを公開
- アカウンタビリティ: 運営委員会・変更提案プロセス・COI申告の整備
- プライバシー保護: APPI審査・仮名加工フロー・識別禁止の制度化
- 再現性: artifact bundleとrerun仕様の義務化
- 多主体運営: 研究者・企業・法務・評価基盤チーム・日本語専門家の合同体制
三段階のロードマップ
- 短期: 共通定義・評価軸・提出仕様の凍結。合成セットv0.1と日本語セットv0.1の公開。国内外5以上のモデルで実行可能な状態を目指す。
- 中期: realistic memory タスクとprivate auditの追加。public leaderboardとartifact package標準の整備。ベンチマーク最適化耐性の確認。
- 長期: multilingual/agent memoryを含む標準基盤化。研究論文・企業評価・公共調達で参照される共通基盤の確立。
まとめ:統一ベンチマークが測るべき本質
本記事で整理したポイントは以下の通りです。
- 階層的記憶の統一ベンチマークは「長文耐性」の延長ではなく、保存・更新・圧縮・検索・推論・棄却を時間・表現・操作の三軸で測るものとして設計すべきです。
- 既存のRULER・HELMET・LongMemEval・LoCoMoはそれぞれ強みがある一方、「更新後の古い記憶の抑制」「階層的要約の事実保持」「会話と軌跡の統合評価」を同時に行う枠組みはまだ成熟していません。
- 日本語評価基盤は長文処理の整備が始まった段階であり、persistent-memory benchmarkは設計自由度の高い空白領域です。
- 評価指標はLevel-Conditioned Recall・Update Accuracy・Abstention accuracyなどを含む多軸設計が必要で、運用面ではpublic/private二層化とrotating hidden sliceが有効です。
統一ベンチマークの最終目的は「モデルがどれだけ長い入力を読めるか」ではなく、「システムがどれだけ多層的に記憶を保存・更新・要約・根拠提示しながら正しく使えるか」を測ることに置くべきです。
コメント