はじめに:なぜLLMにエピソード記憶が必要なのか
大規模言語モデル(LLM)が「賢い」と感じられる場面は増えた。しかし、「先週話した件を覚えていない」「古い情報のまま答えが返ってくる」「誰のことを言っているかを混同する」——こうした体験は、今もなお日常的に起きている。
その原因は、LLMが本質的にエピソード記憶を持たない点にある。人間の記憶には「いつ・どこで・誰と・何があったか」という文脈が伴うエピソード記憶と、知識として蓄積される意味記憶がある。現在のLLMは後者のシミュレーションには優れる一方、前者の再現には構造的な工夫が必要だ。
本記事では、エピソード記憶をLLMに統合するためのアーキテクチャ設計の原則、評価ベンチマークの読み方、そして実務で使える設計パターンを整理する。単純なRAGを超えた、時間・更新・棄権まで含む次世代メモリ設計の全体像を把握したい方に向けた内容だ。
LLMにおけるエピソード記憶とは何か
心理学的定義とLLM実装のギャップ
心理学において、エピソード記憶とは「個人が経験した出来事に関する記憶」であり、内容だけでなく時間・空間的文脈、主観的な状態と結びついて保持される。Tulvingが提唱した**autonoesis(記憶が自分のものであるという自覚)とchronesthesia(主観的な時間意識)**が本質的な要素とされる。
LLMにautonoesisをそのまま実装することはできない。しかし計算論的な近似は可能だ。操作的な定義として、LLMにおけるエピソード記憶を次のように捉えると整理しやすい:
出来事単位で切り出された記録に対して、who / what / when / where / state / source / validity / salience / access_scope を付与し、必要に応じて他エピソードと時間順序・更新関係・因果関係で結んだもの。
この定義は、EpBench・SORT・LongMemEvalといった最新の評価ベンチマークが測定対象としている要素と整合する。
単純RAGでは足りない理由
外部ベクトルDBに会話ログを保存してセマンティック検索する「単純RAG」は、一定の成果をあげている。しかし複数の評価研究が、その限界を繰り返し示している。
LoCoMoベンチマーク(平均約600ターン・16,600トークン・27.2セッション)では、単純な会話ログ検索よりも会話から抽出した「観測事実」を検索した方がQA全体F1が高く、GPT-4-turbo(128Kコンテキスト)でさえ全体F1が51.6にとどまるのに対し、adversarial質問では15.7まで落ちることが確認されている。
LongMemEvalでは、長文脈LLMが継続履歴で大きく性能低下し、時間推論・知識更新・棄権が特に難所であることが報告されている。
つまり問題は「記憶の保存量」ではなく、何の形式で書き込むかと検索後にどう読解するかの設計にある。
エピソード記憶の設計に必要な3つの柱
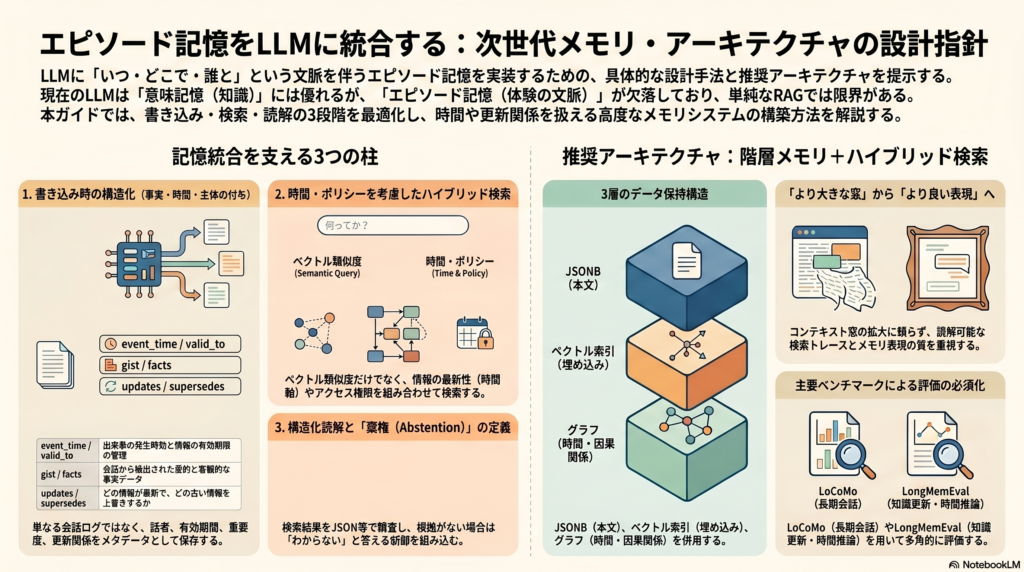
柱1:書き込み時の構造化(Write-Time Structuring)
「保存量」よりも「書き込み時の表現設計」と「検索後の読解設計」が性能を決める——これが複数の評価研究が示す中心的な結論だ。
エピソードを保存する際に最低限持たせるべきフィールドは以下のとおりだ:
| フィールド | 役割 |
|---|---|
event_time / valid_from / valid_to | いつの出来事か、有効期間はいつまでか |
participants / speaker | 誰に関する出来事か |
gist / facts | 何が起きたか(要約と抽出事実) |
updates / supersedes | どの事実が後から更新されたか |
access_scope / pii_level | 誰がアクセスしてよい情報か |
salience | どの程度重要か |
単なる会話ターンをベクトル化して保存するだけでは、出来事の順序・話者帰属・更新関係・アクセス制御という「エピソード性の中核」が崩れる。
PREMemの研究では、保存前に断片(fact / experiential / subjective)へ分解し更新・含意・変化関係を事前に張っておくことで、小型モデルでも大きなベースラインと競争的になり、トークン制約下で有効であることが示されている。
柱2:時間・更新・ポリシーを考慮した検索(Retrieval Design)
セマンティックスコアだけに頼る検索では、意味的に近いが時系列的には古いエピソードが優先されることがある。LongMemEvalの実験では:
- ラウンド粒度への変更で recall@k が向上
- **事実キー拡張(fact-augmented key expansion)**で精度が改善
- 時間aware検索で temporal recall が7〜11%改善
これらの結果は、検索クエリに対してsemantic score + recency weight + entity match + access_policyを組み合わせたハイブリッド検索の有効性を示す。
EM-LLMは、surprise(驚き度)ベースのイベント境界分割とグラフ精緻化による2段階検索で、LongBench・∞Benchにおいて従来のRAGを上回る性能を報告している。REMemは、gistとfactを併置したhybrid memory graphとagentic retrieverを組み合わせ、エピソード想起で+3.4%、推論で+13.4%の絶対的な改善を報告した。
柱3:構造化読解と棄権ポリシー(Reading & Abstention)
検索で正しいエピソードが取れたとしても、それを読解して正確に回答に反映できなければ意味がない。LongMemEvalでは、Chain-of-Note+JSON出力形式の構造化読解を導入することで、最大10ポイントの改善が確認されている。
さらに重要なのが**棄権(Abstention)**の設計だ。根拠となるエピソードが存在しない質問に対して、LLMが「わかりません」と答えられるかどうかは、幻覚(ハルシネーション)防止において決定的な意味を持つ。LongMemEvalの評価では、情報なし質問での棄権精度が設計の優劣を分ける指標の一つとされている。
3つのアーキテクチャ設計パターン
設計A:短期キャッシュ中心
現在セッションの履歴をFIFOまたはKVキャッシュで保持し、一定長を超えたら要約だけを長期ストアへ退避する最もシンプルな構成だ。
向いているシーン: ヘルプデスク、単発の業務対話、低レイテンシが求められる用途
弱点: 交差セッション推論、更新関係の追跡、時間推論には対応しにくい
Redis TTLによる自動削除との相性がよく、実装コストは低い。ただし、要約にPII(個人識別情報)が残った場合の情報漏えいリスクに注意が必要だ。
設計B:階層メモリ+ハイブリッド検索(推奨デフォルト)
各ラウンドまたはイベントをエピソード単位に抽出し、JSONB・ベクトル索引・時間関係グラフの3層で保持する構成だ。これが現時点での推奨デフォルトとなる。
構成要素:
- JSONB / オブジェクトストア: エピソード本文とメタデータ
- pgvector / Faiss / Milvus: 埋め込みベクトル索引
- グラフ(論理的): 時間順序・更新関係・因果関係
向いているシーン: パーソナルアシスタント、継続的なカスタマーサポート、個人化が求められるサービス
特長: 更新管理(bitemporal)、棄権ポリシー、アクセス制御(ABAC)との統合が自然にできる
LoCoMoの観測事実化、LongMemEvalのラウンド粒度・事実キー拡張・時間aware検索、EM-LLMのイベント区切り設計と整合する。
設計C:オンデマンド生成+圧縮保存
PREMemやRMMに近く、保存前に推論処理を行い、断片(fact / experiential / subjective)に分解して更新・含意・変化関係を明示的に構築する高機能案だ。通常は圧縮された断片だけを使い、必要時だけ元イベントを再構成して回答する。
向いているシーン: 長期個人化、継続的な支援サービス、精度最優先の用途
注意点: 保存時のトークンコストが高く、関係推定の誤りが後段に伝播しやすい。整合性管理の設計コストも大きい。
評価ベンチマークの読み方
エピソード記憶の能力を適切に測るためには、複数のベンチマークを組み合わせる必要がある。
LoCoMo は長期会話理解(平均約600ターン)を測り、「会話ログをどれだけ読めるか」ではなく「長期会話をどれだけ理解し続けられるか」を評価する。
LongMemEval はパーソナルアシスタントの運用評価に最も直結する。情報抽出・多セッション推論・知識更新・時間推論・棄権の5能力を分解して評価できる点が強みだ。LongMemEval_Sは約115,000トークン・30〜40セッション、LongMemEval_Mは約500セッション・約150万トークンと規模を選べる。
EpBench は、時間・空間・主体を持つエピソード再想起と推論に特化しており、「エピソード性」そのものの検証に向く。先端モデルでも10k〜100kの文脈で複数関連イベントや複雑な時空間関係に苦戦することが確認されている。
SORT / Book-SORT は順序記憶を測る。順序情報がベクトル類似だけでは保存しにくいという構造的な問題を示す点で重要だ。
セキュリティとプライバシーの設計原則
エピソード記憶システムでは、セキュリティは後付けにできない。OWASPはベクトル・埋め込みの設計不備が、情報漏えい・アクセス制御不一致・埋め込み反転・データ汚染の入口になると警告している。
主な失敗モードと対策を整理すると:
| 失敗モード | 原因 | 対策 |
|---|---|---|
| 時間逆転(古い情報で上書き) | 最新性管理なし | bitemporal管理、updatesエッジ |
| 話者混同 | 共参照・speaker管理不足 | 話者タグを必須フィールド化 |
| 近傍誤検索 | セマンティックのみの検索 | time+entity+policyで再ランキング |
| 情報漏えい | namespace・ABAC失敗 | namespace隔離、属性ベースアクセス制御 |
| プロンプトインジェクション | 外部文書経由の汚染 | ソース検証、不変ログ |
NIST SP 800-188 は、単なる匿名化や編集(redaction)だけでは差分プライバシーのような厳密保証にならないと明示している。差分プライバシーは監査用集計・評価ダッシュボード・ログ共有に活用し、一次の検索経路への直接適用は精度低下を招くため推奨されない。
実装ロードマップと実用化チェックリスト
推奨ロードマップ
短期(〜3ヶ月): LoCoMoとLongMemEvalの再現実験。滑り窓・単純RAG・構造化RAGを同一readerで比較し、retrieval traceを全保存する。
中期(3〜9ヶ月): 設計Bを実装。episodeスキーマ・bitemporal update・fact-key expansion・time-aware query・abstention policyを追加。日本語評価のための合成データセット(省略・敬語・曖昧時刻表現・共有/非共有情報)を整備する。
長期(9ヶ月〜): PREMem/RMM/REMem型の事前推論・graph retrieval・iterative retrievalを導入。ABAC・監査ログ・Red Team・差分プライバシー集計ダッシュボードを運用標準化する。
実用化チェックリスト
- エピソード粒度:ターン保存だけでなくラウンドまたはエピソード単位を保持している
- 更新管理:
supersedesまたはvalid_toがあり、最新情報優先が機械的に判定できる - 検索設計:semantic-onlyではなくentity / time / policyを再ランキングに使う
- 読解設計:retrievalとreadingを別評価し、JSON出力やcitation付き生成を行う
- 棄権:情報なし質問で答えない評価セットを持つ
- 監査:retrieval log・answer provenance・policy decision logを保存する
- セキュリティ:namespace隔離・ABAC・データ検証・汚染対策がある
- コスト:tokens/query・p95 latency・bytes/episodeにSLOがある
まとめ:「より大きいコンテキスト窓」から「よりよいメモリ表現」へ
エピソード記憶をLLMに統合する上での核心は、3段階の共同最適化だ。
- 書き込み時:who / what / when / where / source / validity / access_scopeを明示した構造化エピソードとして保存する
- 検索時:セマンティックスコアに時間・主体・更新関係・アクセスポリシーを加えたハイブリッド検索を行う
- 読解時:構造化推論と棄権ポリシーを備えたreaderで回答を生成する
単純なベクトルDBの導入だけでは、出来事の順序・更新の系譜・話者帰属・棄権という本質的な問題は解決しない。LoCoMoやLongMemEvalの評価結果、およびEM-LLM・PREMem・RMM・REMemが示す改善幅を踏まえると、今後の研究と実装競争の焦点は「より大きいコンテキスト窓」よりも「よりよいメモリ表現」と「読解可能なretrieval trace」に移っていく可能性が高い。
コメント