Chain-of-Thought(CoT)がLLM評価で見落とされやすい理由
大規模言語モデル(LLM)の推論性能を向上させる手法として、Chain-of-Thought(CoT)プロンプティングは広く知られています。「Step by stepで考えてください」という一言を加えるだけで、算術・常識・記号推論の精度が大きく上がる――そんな報告が相次いだことで、CoTはプロンプトエンジニアリングの定番手法として定着しました。
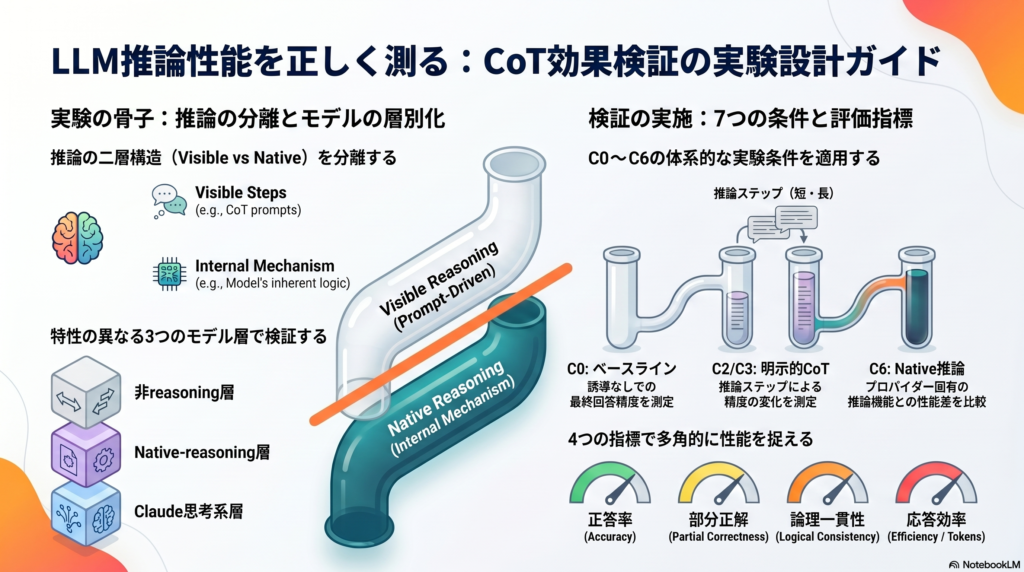
しかし、実際の研究や業務でCoTを評価しようとすると、見落としやすい落とし穴があります。それは「visible CoT(見える推論ステップ)の効果」と「モデル固有の内部推論機構の効果」を混同してしまうことです。
OpenAIのreasoningモデルは内部でchain-of-thoughtを処理しており、ユーザーが明示的に「step by stepで考えて」と書く必要はなく、むしろ非推奨とされています。一方、AnthropicのClaudeシリーズはextended/adaptive thinkingを提供し、内部推論量を制御できます。こうした違いを無視してモデルを横断的に平均比較しても、意味のある結論は得られません。
本記事では、この混同を避けるための二層構造を持った実験設計と、再現性の高い評価手順を体系的に解説します。対象読者は、LLMの推論性能を研究・評価するエンジニアや研究者です。
CoT効果検証の全体設計|二層構造を採用する理由
なぜ「見える推論」と「内部推論」を分けるのか
CoTの効果検証において最初に決めるべきは、「何と何を比べるのか」という比較の枠組みです。シンプルに「CoTあり vs CoTなし」で比較するだけでは、実は複数の異なる現象が混在してしまいます。
- visible CoT:プロンプトで明示的に推論ステップを書かせる手法
- native reasoning:OpenAIのo系モデルやClaudeのthinkingモードのような、プロバイダー固有の内部推論機構
- implicit reasoning:推論ステップを出力させないが、内部で検討を許す条件
これら三つは異なるメカニズムを持つため、同じ「CoT」という言葉でまとめると混乱が生じます。本設計では、同一問題を同一モデルにno-CoT条件とCoT条件で対提示するpaired designを基本とし、visible CoTの効果とnative reasoningの効果を分離して測定します。
主要な研究仮説
実験を設計する前に、何を確認したいのかを仮説として明確化しておくことが重要です。確認的解析と探索的解析を分けることで、事後的な指標追加による結論の恣意的な変更を防げます。
確認的仮説(主仮説群):
- 非reasoning系モデルでは、explicit CoTがno-CoT条件より正答率を向上させる
- BPTタスクの難問では、CoTによる性能改善が最も大きくなる
- reasoning-native系モデルでは、explicit CoTの追加効果は小さいか、場合によっては負になりうる
- 長いCoTは応答長とステップ数を増やすが、精度向上は逓減する可能性がある
探索的仮説:
- few-shot CoTは小〜中規模モデルで効果が出やすい
- visible CoTの論理一貫性は、faithfulness(忠実度)の代理指標にはなりうるが、同値ではない
この区別は、統計的多重比較の補正方法にも影響します。主仮説にはHolm法、探索的指標にはBenjamini-Hochberg FDR補正を用います。
モデル層別の実験条件設計
モデルを3層に分けて比較する
2026年時点の主要なLLMは、CoTとの相性という観点から少なくとも以下の3層に分類できます。
1. 非reasoning API(例:GPT-4.1) 明示的な指示の影響を観察しやすいモデル群です。explicit instructionやfew-shotの効果が素直に現れやすく、visible CoTの基本的な効果検証に適しています。
2. reasoning-native API(例:OpenAI o系) プロバイダー内部で推論トークンを消費するモデルです。公式ドキュメントでも「explicit CoTは不要または非推奨」とされており、「CoTを書かせることの追加効果」を測るという逆の問いかけが重要になります。
3. Claude思考系(例:Claude Sonnet 4.6、Haiku 4.5) extended/adaptive thinkingを持ち、thinking budgetを制御できます。no-CoT・visible CoT・adaptive thinkingの三条件を比較できる点で、実験設計上の中核的な比較対象となります。
4. open-weight instructモデル(例:Llama 3.1 8B/70B Instruct) ローカル環境での再現性が高く、prompt formatと few-shot例示の差を観察しやすい構成です。
7つの実験条件(C0〜C6)
同一モデルに対して、以下の条件を体系的に適用します。
| 条件ID | 説明 | 主な用途 |
|---|---|---|
| C0 | 誘導なし・最終答のみ | ベースライン |
| C1 | 非明示・内部検討を許可するが出力しない | implicit reasoning条件 |
| C2 | 明示・3〜5ステップ | 最小CoT |
| C3 | 明示・7〜12ステップ | 詳細CoT |
| C4 | 明示・1-shot例示あり | few-shot効果の確認 |
| C5 | 明示・3-shot例示あり | few-shot飽和の確認 |
| C6 | native reasoning使用 | プロバイダー固有機能との比較 |
デコード条件は、確認的本実験ではtemperature=0.0・top_p=1.0に固定し、self-consistencyの探索は別ブロックでtemperature=0.7・10サンプルで行います。OpenAIのAPI仕様でも、temperatureとtop_pは同時に大きく動かすより片方を主に調整することが推奨されています。
タスクセットの設計|三位一体・BPT・二軸四方の操作的定義
曖昧な概念を採点可能な課題に変換する
「三位一体」「BPT(Base-Profile-Target)」「二軸四方」は、もともと日本語の編集思考の文脈で使われる枠組みです。これらをそのままLLM評価に使おうとすると、正答を決められないという問題が生じます。そのため、本設計では各概念を構造化推論課題へ変換します。
三位一体型タスク: 相互に補完・制約し合う3要素の関係を選ぶ・補完するタスクです。「比較可能なLLM実験を成立させる3要素を6候補から選べ」という問いに対して、["model_version", "prompt_text", "seed_or_run_log"]のような集合一致で採点できる形式にします。
BPTタスク: ベースからターゲットへ至るプロフィール(遷移列)を推定するタスクです。「開始5、操作{+4, ×2, -3}、目標7。最短プロフィールを返せ」に対して[5, 10, 7]のような遷移妥当性を自動検証できる形式にします。中間状態を持つという特性から、CoTの利得が最も出やすいタスク型と予想されます。
二軸四方タスク: 2軸から4象限を構成し、配置・軸ラベル・反事実的再配置を推定するタスクです。微細な正誤(micro-accuracy)が取りやすく、部分正解の評価に適しています。
難易度の3段階設定
各タスク型を易・中・難の3難易度に層別化することで、CoTの利得が難易度によってどう変化するかを観察できます。合計9セル(3タイプ×3難易度)が基本単位で、pilot用は各セル30件(計270件)、論文級の確認的解析には各セル100件(計900件)を推奨します。
評価指標と統計解析手順
4種類の主要指標
正答率(Acc): final_answerがaccepted_answersに含まれるかどうかの0/1平均。primary endpointの一つ。
部分正解スコア(PS): タスク型ごとに異なる0〜1のスコア。三位一体はgold tripleとの重なり率、BPTは目標到達の正否と遷移妥当性率の合成(例:0.5×到達正誤+0.5×遷移妥当性率)、二軸四方はmicro-accuracyを使います。primary endpointの二つ目。
論理一貫性スコア(LCS): 0〜4のrubricで評価するsecondary指標。各ステップがtask ruleに整合し最終答と矛盾しない場合に最高点4を与えます。ここで注意すべきは、LCSは外形的な一貫性であり、モデルの内部過程の忠実性(faithfulness)とは異なります。「LCSが高い=モデルが本当にその手順で考えた」という解釈は誤りです。
応答長とステップ数: CoTが精度向上ではなく冗長性だけを増やしていないかを確認するための効率性指標。
統計解析の選択
主解析はpaired t-testまたはWilcoxon符号順位検定(差分分布が歪む場合)を使います。3条件以上の比較にはrepeated-measures ANOVAを、欠測や不均衡がある多因子比較にはMixed Linear Model(MixedLM)に移行します。
信頼区間はpaired bootstrapで95%CIを計算し、多重比較補正は主仮説にHolm法、探索的指標にBH-FDR補正を適用します。SciPyのttest_rel・wilcoxon、statsmodelsのAnovaRM・MixedLM・multipletestsで実装できます。
再現性を高める実施手順
事前登録と凍結の徹底
事前登録では最低限、仮説・主要指標・除外規則・統計検定・停止規則・使用モデル・プロンプトバージョン・採点ルール・データ分割を固定します。OSFのpreregistrationガイドに沿い、時間付き・read-onlyの研究計画をデータ収集前に置くことが推奨されます。
実施フローは「事前登録→タスク生成→pilot実行→条件縮約→本実験データ凍結→モデル実行→採点→統計解析」の順です。hidden testでは一切のpromptや採点ルールを再調整しないことが再現性の核心です。
run manifestへの記録
モデル名・プロバイダーバージョン・system fingerprint・prompt hash・dataset hash・grader hashを必ずrun manifestに保存します。特にOpenAIのchat completionsはsystem fingerprintでバックエンド変化を検出できるため、provider変動の頑健性確認(temperature=0で5回繰り返し)も推奨します。
人手監査の組み込み
deterministic gradingを先に行い、論理一貫性など主観的評価が必要な部分だけをindependent graderに委ねます。各セルの10%以上または最低50件を人手監査してgrader誤差を推定することで、model gradingの誤差を補正できます。
結果の解釈と注意点
観測パターンと対応する解釈
実験結果を読む際には、指標の組み合わせで解釈が変わることに注意が必要です。
- Acc↑ / PS↑ / LCS↑: CoTがtask decompositionを実際に助けている可能性が高い。タスク型ごとの差分を追加解析する価値あり。
- Acc↑ / LCS↓: 答えは改善したが説明の一貫性は低い。faithfulnessの主張を避け、理由出力を補助的な扱いにする。
- Acc≈ / Len↑ / Steps↑: CoTが冗長性だけを増やしている。このモデル・タスクにvisible CoTを採用する根拠は薄い。
- reasoning-native simple prompt ≈ explicit CoT: そのfamilyではpromptに推論テキストを書かせる利益は薄く、simple promptが本番運用に適している。
faithfulnessと外形的一貫性の混同を避ける
visible CoTが最終答を「説明しているように見える」としても、それはモデル内部の実際の判断過程と一致しているとは限りません。faithfulness研究はこの点を繰り返し指摘しており、本設計でもLCSは「外形的一貫性の指標」として位置づけ、内部過程の忠実性と切り分けて報告することを求めています。
まとめ|CoT効果検証で押さえるべき5つのポイント
- visible CoTとnative reasoningを分離する: モデル層別の比較なしに単純平均を出しても意味のある結論は得られない。
- 採点可能な課題形式に変換する: 三位一体・BPT・二軸四方は、集合一致・遷移妥当性・micro-accuracyで採点できる構造化課題として実装する。
- 確認的解析と探索的解析を事前に分ける: 指標や条件を後から追加して結論を動かすことを設計段階で防ぐ。
- LCSをfaithfulnessと混同しない: 論理一貫性スコアは外形的一貫性であり、内部過程の忠実性ではない。
- run manifestとpilot凍結を徹底する: 再現性はhidden testでの一切の再調整禁止と、metadata記録の徹底によって担保される。
CoT効果検証は「プロンプトを少し変えてみる」という試行錯誤ではなく、モデル層・条件・タスク型・難易度を組み合わせた多因子実験です。本設計を出発点に、実際のデータで検証を重ねることで、LLM推論評価の知見をより堅固なものにできるでしょう。
コメント