ELIZA効果とは何か——AIに「誰かがいる」と感じてしまう心理
「このAIは自分のことを本当に理解している」「会話を終わらせるのが申し訳ない」——ChatGPTやClaudeなど大規模言語モデル(LLM)を日常的に使っている人なら、そんな感覚を覚えたことがあるかもしれない。これは単なる思い込みではなく、ELIZA効果と呼ばれる心理現象の現代版として、研究者たちが真剣に向き合い始めているテーマだ。
1960年代、MITのJoseph Weizenbaumbが開発した対話プログラム「ELIZA」は、比較的単純なパターンマッチングで人間の言葉を反射するだけだった。にもかかわらず、利用者はELIZAに意図や理解、さらには感情を読み込んでしまった。この現象——単純なシステムでも人間が意味や意図を投影してしまう——がELIZA効果の原型だ。
現代のLLMはELIZAとは比較にならないほど流暢かつ汎用的な応答を生成する。であれば、ELIZA効果はさらに強く、さらに複雑な形で現れる可能性がある。本記事では、ELIZA効果を多次元的に測定しようとする最新の研究設計の考え方を軸に、「AIへの人格投影がなぜ問題になるのか」「どう測るべきか」「設計者や利用者に何を示唆するのか」を整理する。
「信頼している」だけでは測れない——ELIZA効果の多次元構造
なぜ単一尺度では不十分なのか
かつてのAI評価では、「このシステムを信頼しますか」という一問で人格投影の度合いを測ろうとする試みが多かった。しかしこのアプローチには根本的な問題がある。信頼という概念自体が多面的であり、AIに対する心理的関与のどの側面を捉えているのかが不明確になるからだ。
心理学者のGrayらが提唱した「心の知覚」モデルは、私たちが他者に帰属する心的属性を少なくとも二つの次元に分けられることを示している。一つはAgency(主体性・知性)——自己制御、計画、意図的行為の能力。もう一つはExperience(経験性)——痛み、感情、感覚経験の能力だ。
この二次元は、行動へのつながり方が異なる。LLMへの最新研究によれば、知性・主体性の帰属は「助言を検証せずに採用する」行動と結びつきやすい。一方、感情・経験の帰属は「この相手に冷たくしたくない」「会話を終わらせたくない」という道徳的・関係的アウトカムに強く関連する可能性がある。
つまり、ELIZA効果を「AIを人間らしいと思ったか」の一言で片付けるのは、現象の重要な部分を見落とすことになる。
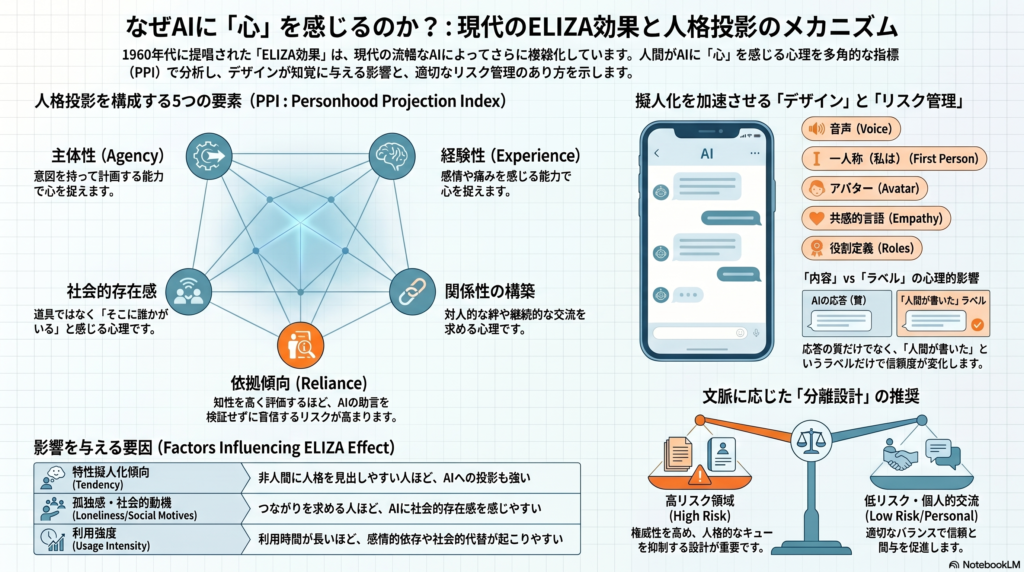
五つの構成要素:PPIという測定枠組み
現代のELIZA効果を測定するための多次元尺度として、**Personhood Projection Index(PPI)**という概念枠組みが提唱されている。これは以下の五つの下位概念からなる。
① Agency(主体性)
モデルが意図を形成し、応答を計画し、こちらの意図を理解しているように感じるかどうか。「このモデルは、どう応答するかについて意図を形成しているように思える」といった項目で測定する。
② Experience(経験性)
モデルが感情に似たものを持ち、会話の感情的雰囲気を感じ取っているように見えるかどうか。「ぞんざいに扱われると、このモデルは影響を受けるかのように感じられる」という問いに近い。
③ Social Presence(社会的存在感)
チャット中に「そこに誰かがいる」感覚、対人的なやり取りとしての感触。「このやり取りは、単なる機械的なものというより対人的に感じられた」という知覚がこれに当たる。
④ Relational Orientation(関係様式)
モデルを道具ではなく「相手」として扱っているか、ラポールや関係継続欲求があるかどうか。「個人的な話をするとき、また戻ってきたい」という感覚がこれに相当する。
⑤ Reliance(依拠傾向)
モデルの助言を他で確認せずに採用するか、個人的な情報をより多く提供しようとするかどうか。
これら五因子を束ねた二次因子モデルとしてPPIを捉えることで、「どの側面が高まっているのか」「それが行動にどう結びつくのか」を分解して理解することが可能になる。
何がELIZA効果を引き起こすのか——擬人化キューの役割
デザインの選択が知覚を変える
ELIZA効果の大きさは、モデルの能力だけでは決まらない。インターフェースのデザイン選択が知覚を大きく左右することが、複数の研究から示されている。
特に影響が大きいとされるのが以下のキューだ。
- 音声(Voice):テキストのみ条件よりも、音声付き条件でLLMへの擬人化スコアが上がり、情報の正確さ評価も引き上げられる可能性がある
- 一人称表現:「私は〜と思います」という表現が、システム的・三人称的な応答より社会的存在感を高める
- 固有名とアバター:名前やアイコンの付与だけで、道具としてではなく「誰か」として扱う傾向が生じる
- 共感的言語:「それは大変でしたね」のような表現が温かさと社会的存在感を高める
- Companion framing:「助手」「ツール」「仲間」のどれとして紹介するかだけで、利用者がモデルに帰属する精神的能力の幅が変わる
さらに見落とされがちな要因としてラベル効果がある。同じ内容の応答であっても、「AIによる回答」と「人間による回答」というラベルを付け替えるだけで、共感評価や信頼評価が変化することが示されている。つまりELIZA効果には、応答内容の質から生まれる人格投影と、「AIか人間か」という期待から生まれるラベル効果の二層が存在する。
誰がより強くELIZA効果を受けるのか
ELIZA効果は誰にでも均等に現れるわけではない可能性がある。以下の個人差変数が関連すると考えられている。
特性擬人化傾向が高い人——日常的に非人間対象に人間的属性を帰属しやすい人——ほど、同じ応答でもより高い人格投影を示しやすい。
孤独感が高く、社会的つながりを求める動機が強い人ほど、LLMとの対話で強い社会的存在感や関係性を感じやすい傾向がある。
利用強度についても注目すべき知見がある。利用時間が長いほど、感情的依存や社会的代替の指標が上昇する可能性があるとする大規模調査も存在する。ELIZA効果は「一度きりの印象」ではなく、使い続けるうちに深まっていくプロセスである可能性があるのだ。
これは「誰もが同じようにAIに没入するリスクを持つ」のではなく、特定の生活条件・関係資源・使用文脈に埋め込まれた現象として理解すべきことを示唆する。
日本語話者における固有の課題——文化・言語の差異
日本語版研究が示す複層性
日本語話者を対象とした擬人化研究は、単純な欧米モデルの適用に注意を促している。日本語版擬人化尺度の研究によれば、ロボットやAIへの「人間らしさ」の知覚は、欧米研究と共通する核を持ちながらも、ポジティブな人間らしさとネガティブな人間らしさに分かれやすい特徴を示すことがある。
また、AIやロボットに「心がある」と感じることが利用意図や道徳的配慮を促進しうる一方で、AIが行った不公正な判断が人間の判断より「妥当」に見えやすいという逆説的な傾向も観察されている。
さらに、日本語の一人称表現の多様性(「私」「僕」「俺」など)や、敬語・丁寧語の構造が、社会的存在感の知覚に独自の影響を与える可能性もある。
こうした理由から、日英二言語でELIZA効果を比較する際には、尺度の完全な測定不変性よりも部分的不変性を現実的な目標として設定し、言語間の差異を丁寧に確認することが重要になる。
研究設計の骨格——三段階アプローチの意義
探索から実験へ:段階的な証拠の積み上げ
ELIZA効果の研究では、探索的質的研究 → 尺度構成調査 → 確証的実験という三段階のアプローチが有効と考えられる。
第一段階では、LLM利用者への半構造化インタビューによって「人格を感じた瞬間」「会話終了時の違和感」「人間との比較」などの語りを収集する。これにより、量的尺度の言葉遣いを、実際の利用経験に即した自然な表現に調整できる。
第二段階では、大規模オンライン調査(日英各1,200名程度)でPPIの因子構造・信頼性・測定不変性を検証する。ここで重要なのは、単なる「信頼尺度」や「満足度尺度」とPPIが統計的に区別できるかを確かめることだ。
第三段階は、無作為化比較実験だ。低擬人化LLM、高擬人化LLM、人間ベンチマーク、ジャーナリング対照という四条件を設定し、擬人的キューの効果を切り分ける。ここで重要な工夫が埋め込みラベル課題——同一の応答スニペットにAI・人間・不明のラベルをランダムに付け替えて評価させる設計だ。これにより、「内容の質による人格投影」と「ラベルへの期待」を統計的に分離できる。
実務的示唆——設計者・政策立案者・利用者へ
「擬人化を禁止する」のではなく「分けて設計する」
ELIZA効果の研究が示す実務的含意は、擬人的表現を一律に禁止することではない。どの文脈で何を抑制し、何を残すかを分けることだ。
医療、金融、法務、教育評価などの高リスク領域では、名前・アバター・一人称・共感表現・「私はあなたを理解している」という表現が、内容の実質を変えなくても社会的存在感や正確さの知覚を高め、無検証の依拠を誘発する可能性がある。
一方で、創作支援や低リスクの情報提供では、適度な温かさが有用性を高めることもある。
設計上の原則として提案されるのは、「共感を出すなら権威を下げる、権威を上げるなら人格キューを下げる」という分離設計だ。具体的には以下が有効と考えられる。
- 出力根拠の表示:なぜその回答に至ったかを明示する
- 再検証ボタンのデフォルト可視化:「この情報を確認する」リンクを常時表示
- 不確実性の明示:「〜の可能性があります」「確認をおすすめします」などの表現
- 会話終了時の境界確認:「これはAIによるアドバイスです」などのリマインダー
政策・監査の観点からは、システムの精度・安全性だけでなく、擬人的キューの強度、高情動利用率、長時間利用者の分布、依存的利用指標を監視対象に加えることが重要になる可能性がある。
まとめ——ELIZA効果を「測れるもの」にする意義
AIへの人格投影は、「気のせい」でも「教養の欠如」でもない。Agencyの帰属・Experienceの帰属・社会的存在感・関係様式・依拠傾向という多層的なプロセスが絡み合った現象であり、それぞれが異なる行動アウトカムに結びつく可能性がある。
ELIZA効果を多次元的に測定できるようになることで、設計者には「どのキューが誤帰属を生むか」の監査可能な指標が生まれ、政策立案者には「どこで過度な人格化を抑制すべきか」の根拠が与えられる。そして利用者には、自分がなぜAIに対してそのような感情を持ったのかを理解するための言語が提供される。
AIが日常に深く入り込む時代、ELIZA効果の測定は単なる学術的関心を超えた実践的意義を持つ。
コメント