群ロボットが「触れ合うだけで学び合う」時代へ
複数のロボットが会話も指示もなく、ただ物理的に触れ合うだけで互いの技能を伝え合い、協調行動を自律的に獲得する――。そんな研究領域が、近年のロボット工学において注目を集めています。それが「群ロボットにおける身体的学習の共有」です。
従来のロボット制御では、あらかじめ人間がプログラムした動作ルールに従って機械が動くのが一般的でした。しかし、現実世界の複雑な環境に適応するには、ロボット自身が学び、仲間同士で知識を共有する仕組みが求められます。本記事では、この新しいアプローチの定義・理論・実装方法・将来展望を体系的に解説します。
群ロボット(スウォームロボティクス)と身体的学習の基本定義
スウォームロボティクスとは何か
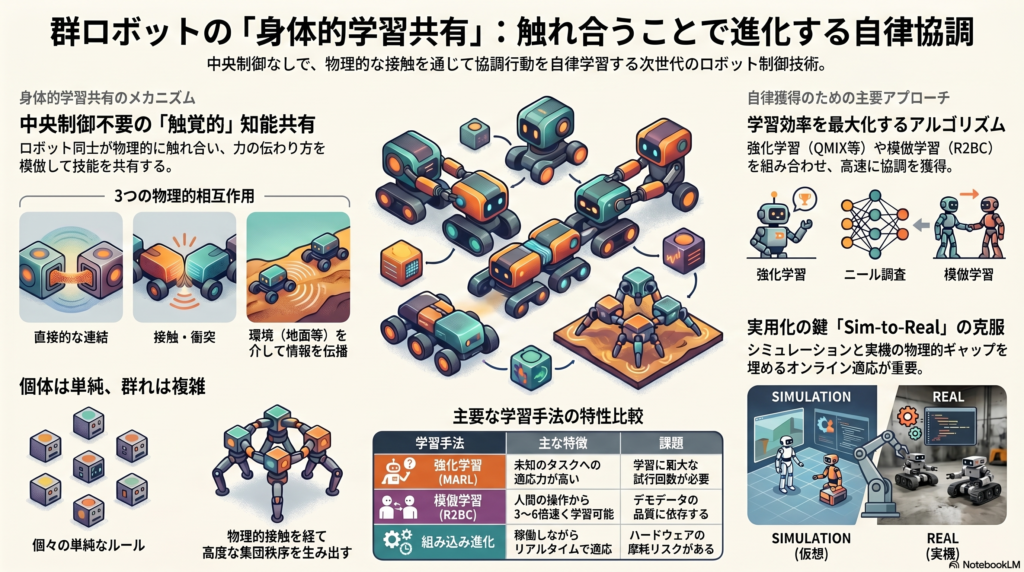
群ロボット(スウォームロボティクス)とは、多数の比較的シンプルなロボットが局所的な相互作用によって協調し、複雑な集団動作を実現するシステムです。重要なのは「中央制御なし」という点で、各ロボットは自身の局所的な観測・通信・計算能力だけで行動を決定します。
個体レベルでは単純なルールしか持たないにもかかわらず、群れ全体として秩序ある振る舞いが自然に生まれる――これが群ロボティクスの本質的な特徴です。群れのような移動、分散探索、大型物体の共同搬送などが代表的なタスクとして挙げられます。1990年代にM. Mataricらは、中央制御なしでもホーミング・探索・集団移動といった協調タスクを達成できることを実証し、この分野の礎を築きました。
身体的学習の共有とはどういう意味か
「身体的学習の共有」とは、ロボットが物理的に接触することで学習経験や技能を伝播・共有し、自身の行動を更新するプロセスを指します。たとえば、あるロボットが物体を押す最適な方法を学習したとき、その「力のかけ方」を物理的に隣接するロボットが触覚で感じ取り、自身の動作に反映する――そうしたイメージです。
動物行動学における社会的学習と類似したメカニズムであり、ロボットが隣人の挙動を観察・模倣する能力を備えることで、群全体への行動共有が可能になります。
物理的相互作用の種類
物理的相互作用には大きく3つの形態があります。
- 直接結合:マグネットやラッチ、グリッパなどで機械的に連結し、力を直接伝える
- 接触・衝突:互いに押し引きや衝突を通じて暗黙の情報を伝える
- 環境媒介型:物体や地面を介して間接的に力やパターンを共有する
どの形態を選ぶかは、タスクの性質やロボットの設計によって異なります。
協調行動を自律獲得するための主要アルゴリズム
マルチエージェント強化学習(MARL)
強化学習は、各エージェントが状態 s と行動 a の対に対して報酬 r を受け取りながらポリシーを獲得する手法です。マルチエージェント設定では、個別の観測から行動を決定しつつ、群全体の成果を最大化する方向で学習を進めます。
代表的なアプローチとして、中央集権的学習・分散実行(CTDE) フレームワークがあります。訓練時は全体情報を使って学習し、実行時は各ロボットが局所観測のみで動作するため、実用的なスケーラビリティを保ちながら高品質な協調行動の獲得が可能です。QMIX のようなQ値因子分解法では、局所Q値を混合ネットワークで統合してグローバルな最適解を近似します。
強化学習の利点は未知タスクへの適応能力と最適行動の自動発見にありますが、サンプル効率の低さと、他エージェントが同時に学習することで環境が非定常になる問題(非定常性)が課題として残ります。
模倣学習(Behavior Cloning)
模倣学習は、人間または熟練ロボットによるデモンストレーションから行動を学習する方法です。観測と行動の対データを教師信号として用い、方策パラメータをクロスエントロピー損失や最小二乗誤差で更新します。
特に注目される手法が、2025年に提案された R2BC(Robot-to-Robot Behavior Cloning) です。1人のオペレータが1台ずつロボットをテレオペレートするだけで、複数ロボットの協調行動を学習させることができ、従来の集中型行動クローンと比較して3〜6倍の速度で性能が向上したと報告されています。模倣学習は計算コストが比較的低く、人間の知識を直接活用できる点が強みです。一方で、デモの品質への依存度が高く、未経験の状況への汎化には限界があります。
進化的手法(組み込み進化)
遺伝的アルゴリズムなどを応用して制御ポリシーを進化的に最適化するアプローチです。中でも「組み込み進化(Embodied Evolution)」と呼ばれる手法では、各ロボットが自身のゲノム(行動規則)を持ち、別のロボットと出会ったときにゲノムを交換・変異させながら制御ソフトを更新します。これにより、ロボットが実際に行動しながら並行して設計プロセスも進む、リアルタイム適応が実現します。
利点は、人間が設計困難なブラックボックスな最適化が自動的に進むことですが、大量の試行・評価が必要なため計算コストが高く、実機ではハードウェアの消耗リスクも伴います。
自己組織化アルゴリズム
明示的な学習を行わず、あらかじめ設計されたローカルルールによって集団行動を実現する手法です。Boidsの群れモデルやフェロモン型スティグマジーなどが代表例です。設計・実装が比較的容易で計算負荷が小さい反面、複雑タスクへの汎用性は限られます。
力制御と接触モデル
物理的協調においては、ロボット間やロボット–環境間の接触力制御が不可欠です。インピーダンス制御モデルでは、目標位置と現在位置の差分から力を生成し、スムーズな接触動作を実現します。複数ロボットによる物体搬送ではハイブリッド位置/力制御が活用され、精密な協調が可能になります。ただし、高精度センサと制御システムが必要となるため、コストとスケーラビリティのトレードオフが生じます。
実験設計と評価指標:何をどう測るか
代表的なタスク設定
群ロボット協調学習の研究では、以下のようなタスクが多く用いられます。
- 大規模搬送タスク:複数台で大型物体を協調して運搬
- ギャップ横断:ロボット群が物理的に連結して橋を形成し渡る
- フォーメーション形成:指定された隊列を自律的に構成
- 分散探索・目標発見:広域環境での協調的情報収集
これらはいずれも単体では達成困難なケースを想定しており、群ロボットの協調能力を測るベンチマークとして機能します。
5つの主要評価指標
定量的な評価には以下の指標が広く使われます。
- 成功率:課題達成率(%)
- 学習速度(収束速度):収束までの時間や試行回数
- 堅牢性:通信ノイズや個体故障が発生した際のタスク継続率
- エネルギー効率:走行距離や駆動出力の合計
- スケーラビリティ:群サイズNの増加に対する性能の変化
群サイズや通信の有無、故障発生条件などを変えたパラメータスイープ実験を行うことで、各アルゴリズムの性能感度を多角的に評価できます。
シミュレーションと実機の乖離問題
シミュレーション環境では物理パラメータが理想化されているため、学習実験を効率的に繰り返せます。しかし実機では、タイヤの実際の摩擦特性・無線通信の遅延・モータ性能の個体差・バッテリ残量の変動など、多数の不確定要素が絡み合い、シミュレーションで学習したポリシーが十分な性能を発揮しないケースが生じます。
このギャップを埋めるために、ドメインランダム化(シミュレーション中の物理パラメータをランダムに変動させて学習)やオンライン適応(実機稼働中にリアルタイムでポリシーを更新)といった技術が重要な研究課題となっています。実験プロトコルとしては、まずシミュレータで基礎検証を行い、次に実機(10台規模)でフィードバック制御や通信プロトコルの調整を行うという段階的アプローチが現実的です。
代表的研究プロジェクトの比較
SWARM-BOT プロジェクト(Mondadaら、2005年)
EUの大型プロジェクトとして展開されたSWARM-BOTでは、個々の小型ロボット(s-bot)が剛性グリッパや柔軟ベルトで互いに連結し、単体では越えられない大型障害物を群れとして突破することを実証しました。群体サイズによって3つのタスクで超線形的な性能向上が見られ、最適なグループサイズの存在も解析されています。
PuzzleBots(Shiら、2021年)
受動的な「ノブと穴」によるパズル状連結機構を持つ9台のロボットで、ギャップ横断実験を実施。能動駆動と受動結合を組み合わせることで、群れとしての橋渡しと単独移動の両方を実現しました。実装コードはGitHubで公開されています。
R2BC(Mattsonら、2025年)
1人のオペレータが1台ずつテレオペレートするデモから多エージェント協調行動を学習させる手法。シミュレーションと実機の両方で検証され、集中型行動クローンと比較して学習効率が大幅に向上したことが報告されています。
ヘテロロボット間の物理結合(Michaelら、2024年)
ドローン(エアリアル)と地上車がスプールとベロクロで繋留し、単独では不可能なフェンス越えを計画的に達成した事例。異種ロボット間の物理結合という新たな可能性を示す研究として注目されています。
実装に向けた推奨アーキテクチャと必要要素
分散学習を基盤としたシステム構成
推奨されるアーキテクチャは、各ロボットに独立した計算ノードとセンサ・アクチュエータを搭載した分散強化学習を基盤とするものです。訓練時のみ全体評価用のモニタを使うCTDEフレームワーク(QMIXやCOMAなど)を採用しつつ、初期学習は模倣学習でブートストラップすることで、サンプル効率を改善できます。
必要なセンサとアクチュエータ
- 力覚センサ / タッチセンサ:接触力測定のため各リンク部に配置
- IMU(慣性センサ):自己位置推定・姿勢制御
- カメラ / LiDAR:環境認識・近距離通信補助
- 全方向移動ホイール:自由度の高い移動を実現
- 磁石・ソレノイド・ラッチ機構:他ロボットとの結合/解離
各ロボットが長時間稼働できるバッテリ管理も、実運用では重要な要素です。
リスクと対策
実機実験で想定されるリスクとして、ロボット同士の衝突による損傷、通信途絶による暴走、学習ポリシーの発散などが挙げられます。対策として、衝突緩衝機構(バンパー)の設置、速度上限の設定、緊急停止機能の実装が基本となります。また、モジュラー設計によって個体故障時に他ロボットで肩代わりできる冗長性を確保することも重要です。
まとめ:身体的学習共有が開く群ロボティクスの新地平
本記事では、群ロボットにおける身体的学習の共有について、定義から主要アルゴリズム、実験設計、代表的研究事例、実装提案まで体系的に解説しました。
重要なポイントを整理すると以下のとおりです。
- 群ロボットは中央制御なしに局所相互作用だけで複雑な協調行動を実現する
- 身体的学習の共有は、物理的接触を通じた技能伝播という動物の社会的学習に類似したメカニズム
- 強化学習・模倣学習・進化的手法それぞれに特性があり、タスクや環境に応じた選択が必要
- シミュレーションと実機のギャップ克服が、実用化への最大の課題の一つ
- SWARM-BOT・PuzzleBots・R2BCなど、物理的相互作用を軸にした研究が着実に成果を上げている
この分野はまだ多くの未解決問題を抱えており、研究の深化とともに産業ロボット・災害対応・宇宙探査など幅広い応用が期待されます。
コメント