フィジカルAIが注目される理由:言語だけでは足りない時代へ
ChatGPTをはじめとするLLM(大規模言語モデル)は、テキスト処理の分野で目覚ましい成果を上げてきた。しかし、ロボットや自律システムが「現実世界で動く」ためには、言語理解だけでなく、カメラ・力覚センサ・IMUといった多様な身体センサとの統合が不可欠だ。
この課題に応えるのが、「フィジカルAI(Physical AI)」あるいは「身体性AI(Embodied AI)」と呼ばれる研究分野である。本記事では、その概念的な定義から主要な先行研究、具体的な統合アーキテクチャ設計、さらに倫理・安全面の考慮点まで体系的に解説する。
「身体性(Embodiment)」とは何か:フィジカルAIの出発点
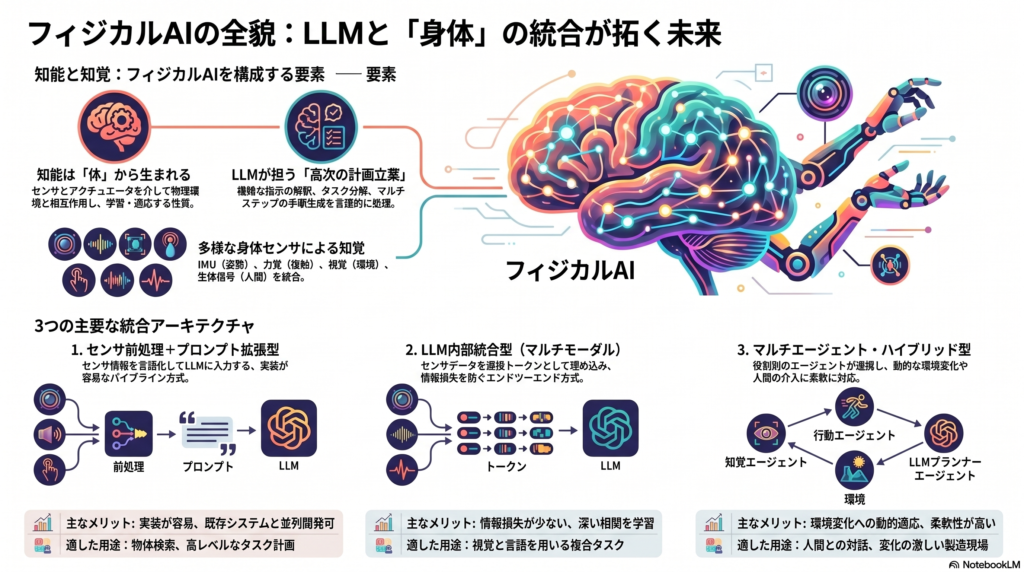
知能は「体」から生まれる
「身体性」とは、AIエージェントがセンサーとアクチュエータを通じて物理環境と相互作用しながら知能を発達させる性質を指す。単にデータを処理するのではなく、環境との相互作用のなかで学習し適応する点が、従来の言語モデルとの本質的な違いだ。
フィジカルAIとは「センサー・アクチュエータを介して環境と相互作用しつつ、知能を発達させる身体性を備えたAI」であり、環境適応や協調動作などの特性を有するとされる。
つまり、ChagGPTのようなサイバー空間のエージェントとは異なり、フィジカルAIは物理空間で動くロボットや車両・ウェアラブル機器として具現化されるものだ。知覚・推論・行動が「身体」に統合されることで、はじめて現実世界のタスクに対応できる。
LLMが担う役割:高次の計画と指示解釈
LLMは「推論・推論展開・階層的計画立案」能力を持ち、ロボットに高次な指示解釈や抽象化の補助をもたらす。ユーザ指示の分解やタスク間の整合性チェック、マルチステップ手順の生成といった言語的な知識処理にLLMを用いることで、ロボットの行動計画の高レベル化・汎化性能向上が期待される。
ただし、LLM自身は物理的経験がないため、環境への適用にはセンサフィードバックとの連携が必須となる。言語能力と身体センサをいかに結合するかが、フィジカルAI研究の核心的な問いだ。
主要センサの特徴と前処理:データが語る身体の状態
フィジカルAIでは、複数のセンサが連携してロボットや機器の「知覚」を担う。それぞれのセンサには固有の特性と前処理上の課題がある。
IMU(慣性センサ):動きの基盤
IMUは加速度・角速度を測定し、姿勢・運動を推定する。小型・低消費電力で高速サンプリング可能だが、ドリフトやノイズが生じやすい。実装では、拡張カルマンフィルタなどのセンサ融合技術でドリフトを補正しながら、リアルタイムの姿勢推定を行うのが一般的だ。100Hz以上の高レートサンプリングが可能で、リアルタイム制御との親和性が高い一方、積分誤差の蓄積には継続的なキャリブレーションが求められる。
力覚・触覚センサ:「触れること」の精密化
力覚センサはタッチポイントや接触力・トルクを計測し、物体把持や力制御に必要とされる。高精度だが一般に設置が複雑でコスト高、応答速度は遅いものもある。一方、触覚センサは柔軟な接触面積や圧力分布を検知し、物体形状の認識や把持の安定化に有用だが、開発途上で感度や耐久性に限界がある。これら二種のセンサは組み合わせて使うことで、ロボットハンドの精密操作を実現する。
視覚センサ:環境認識の中心
視覚センサは環境の画像や3D形状を取得し、物体検出・環境マッピングに不可欠だ。高次元データで情報量は多いが、ノイズや照明変動に弱く、通信・計算負荷が大きい。LLMへの統合にあたっては、画像をCLIPやViTで埋め込み化するか、物体ラベルや文字列に変換してテキストとして入力する手法が多く採用されている。
生体信号センサ:人間の内的状態を読む
生体信号センサは心拍(ECG)、筋電(EMG)、脳波(EEG)などを検知し、非侵襲で情報量が得られる反面、測定精度や装着性、プライバシー問題が課題となる。ウェアラブルHMI(ヒューマン・マシン・インターフェース)領域では、ユーザのストレス状態や意図をリアルタイムに推定し、ロボット側の行動調整に活用する試みが進んでいる。
先行研究から学ぶ:RT-2、PaLM-E、SayCanの何が革新的か
フィジカルAIの研究は近年急速に蓄積されており、特にGoogleをはじめとする大手研究機関から重要な成果が相次いでいる。
RT-1/RT-2:ロボットデータとWebデータの融合
RT-1はロボット制御データ中心で汎用モデルを実現し、RT-2では画像・テキストをトークンとして連結し、ゼロショット推論などを達成した。RT-2の特徴は、インターネット規模の視覚言語データとロボット軌跡を同時にファインチューニングすることで、新しい物体や未知のコマンドに対してもゼロショットで対応できる点だ。ただし大規模モデルであるため、リアルタイム制御への適用にはメモリ・計算資源の面で制約がある。
PaLM-E:センサデータをトークンとして直接統合
PaLM-Eは、ロボットのカメラ画像や連続的センサ出力を埋め込みトークンとしてLLMに直接入力する手法で、画像・状態をタグ埋め込みで処理し、言語モデルがロボット計画に利用可能な多モーダルモデルを構築する。562億パラメータという巨大モデルで高い性能を示したが、訓練コストの大きさが実用展開上の課題として残る。
SayCan:「言語の意図」を「実行可能な行動」へ
SayCanはLLMによるタスク計画候補と、事前学習されたスキルのアフォーダンス(実行可能性)を組み合わせた手法で、実世界のキッチン環境で高水準指示を実行し、非地上化モデルと比較して約2倍の精度向上を報告した。自然言語指示が「実行可能なスキルの確率」で重み付けされることで、現実的かつ安全な動作選択が可能になる。ただし辞書型のスキルセットに依存するため、新しい行動の追加には再訓練が必要という課題もある。
Inner Monologue:フィードバックで計画を磨く
Inner Monologueはロボットが取った行動に対し、成功・失敗判定やシーン記述、人間反応などの自然言語情報をLLMに逐次入力することで計画を修正・洗練する手法で、閉ループの言語フィードバックにより高レベル指示の完遂率が大幅に向上することを示した。環境状態を言語化してLLMに再投入するこのアプローチは、動的環境への適応という観点で特に注目に値する。
統合アーキテクチャ3選:設計の選択肢と使い分け
LLMと身体センサを統合する方式には複数のアプローチがあり、それぞれ遅延特性・学習方式・適用範囲が異なる。
アーキテクチャ①:センサ前処理+LLMプロンプト拡張型
最もシンプルな構成は、各センサデータを前処理モジュールで特徴量に変換し、自然言語プロンプトとしてLLMへ入力するパイプライン型だ。「視覚マップ:障害物あり、距離50cm」「力覚:0.3N」「ユーザ指令:右に移動」といった情報をプロンプトに組み込み、LLMが高レベルの計画を生成する。
この方式の利点は実装が比較的容易で既存の制御系と並列開発できる点にある一方、遅延が大きく、センサから特徴・言語への変換過程で情報損失が生じやすく、リアルタイムの微調整には不向きという欠点がある。高レベルタスク(物体検索、協調作業)の計画生成には適している。
アーキテクチャ②:LLM内部統合型(マルチモーダルTransformer)
センサデータの埋め込みをLLMの入力トークン空間に直接組み込み、エンドツーエンドで学習するアプローチで、PaLM-EやRT-2がこれに相当する。
この方式は情報損失が少なく深い相関を学習可能で複数モーダルの同時最適化による汎用性の高さが利点だが、訓練・推論とも計算コストが極めて大きく巨大なGPUクラスターが必要で、動的制御には別経路が必要となる欠点がある。視覚と言語を両用する複合タスクや、ウェアラブルセンサとの統合アプリに向く。
アーキテクチャ③:マルチエージェント・ハイブリッド型
LLMエージェントが高レベル計画を立案し、視覚エージェントや強化学習エージェントが環境フィードバックを処理する、複数エージェントの協調構成だ。音声認識→LLM→視覚エージェント→LLMという閉ループが形成され、環境変化への動的な適応が可能になる。
この方式は各エージェントが専門性を発揮し柔軟な適応が可能で環境変化への動的対応や人の介入(ヒューマン・イン・ザ・ループ)を容易に実装できるが、システム全体の複雑度が増し同期・インターフェース開発が困難で複数エージェント間での意思決定整合性を管理する必要がある。人間との対話や変化の激しい製造ライン環境などに適した構成と言える。
倫理・安全・法規制:身体データを扱う責任
フィジカルAIが扱う映像・音声・生体信号は、個人のプライバシーに直結するセンシティブな情報だ。システム設計の段階から法規制と倫理への配慮が欠かせない。
プライバシー保護の原則
映像・音声・バイオデータは個人情報・生体情報に該当する可能性が高く、日本では個人情報保護法、EUではGDPRで厳格に規制される。利用者からの明示的同意(オプトイン)、データの匿名化・暗号化、必要最小限のデータ収集原則が必須とされる。カメラ映像での顔のリアルタイムぼかしや、音声の音素レベル変換保存といった技術的対策が現実的な選択肢として挙げられる。
ロボット誤動作のリスクとフェイルセーフ
LLMの「ハルシネーション(虚偽生成)」や指示解釈ミスを防ぐため、信号出力にガードレール(動作可能な範囲の制約、事前学習されたアフォーダンスでのフィルタ)を設ける必要がある。SayCanのようにスキルで生成結果を検証する仕組みや、LLM自身が根拠を付記するReAct型の自己検証を組み合わせることで、安全性を高める方向性が示されている。
法規制の全体像
EUのAI規則案(AI Act)では「高リスクシステム」に該当する可能性が高く、事前認証・性能検証・透明性などの要求が生じる。日本では個人情報保護法、産業用では労働安全衛生法、車載系では道路運送車両法・自動運転規制も念頭に置く必要がある。プロジェクトの設計段階から法務専門家・倫理委員会と連携し、データ管理基準と安全基準を明確化しておくことが望ましい。
研究ロードマップ:短期から長期への展開
フィジカルAI研究は段階的な投資と人員計画が重要だ。
短期(~6ヶ月)ではプロトタイプ基盤構築と小規模データ収集開始、中期(1~2年)では複数アーキテクチャの比較評価と成果公開・特許出願、長期(3~5年)では大規模性能検証とユーザ実証・社会実装準備および安全認証・法規制対応が主要なマイルストーンとなる。
必要スキルとしては、ROS/ROS2の運用、深層学習(LLM/VLM)実装、システム連携設計、安全工学、法規知識など幅広い専門性が求められる。研究規模に応じて数千万円から数億円規模の予算が想定されるが、オープンソースモデル(Octo、OpenVLA等)の活用で初期コストを抑える戦略も有効だ。
まとめ:フィジカルAIは「言語と身体の統合」という新フロンティア
フィジカルAIは、LLMの高度な言語推論能力と、多様な身体センサから得られるリアルタイムの物理情報を融合することで、現実世界で機能する汎用的な知能システムを目指す研究領域だ。
本記事では以下の要点を解説した:
- 「身体性」の概念とLLMがフィジカルAIに果たす役割
- IMU・力覚・視覚・生体信号などセンサ別の特徴と前処理手法
- RT-2・PaLM-E・SayCan・Inner Monologueなど先行研究の革新ポイント
- 3種の統合アーキテクチャ(プロンプト拡張型・内部統合型・マルチエージェント型)の比較
- プライバシー・安全・法規制への対応指針
技術の急速な進展とともに、評価指標の標準化・安全基準の整備・倫理的ガイドラインの策定が急務となっている。フィジカルAIはロボット工学・AI・認知科学の交差点に位置し、今後数年で社会実装が加速すると予想される分野だ。
コメント