なぜ今、RAGに「解釈学」の視点が必要なのか
RAG(Retrieval-Augmented Generation)は、大規模言語モデル(LLM)に外部知識を組み合わせることで、最新情報や専門知識を活用した回答生成を可能にする技術として、急速に普及しています。しかし実務での導入が進む一方で、「取得した情報がうまく統合されない」「回答が断片的で一貫性に欠ける」といった課題が繰り返し報告されています。
こうした課題の本質を理解するうえで、哲学・解釈学の分野から生まれた概念——エルメネウティック・サークル(解釈学的循環)——が有力な分析枠組みを提供します。本記事では、解釈学的循環の考え方をRAGシステムに適用することで、部分的情報取得の限界と全体的文脈統合の難しさを構造的に整理し、既存の技術対策とその限界まで含めて論じます。
エルメネウティック・サークルとは何か——全体と部分の循環的理解
解釈学的循環の哲学的背景
エルメネウティック・サークルとは、「全体の理解は部分への言及によって成り立ち、部分の理解は全体への言及によって成り立つ」という循環的な解釈プロセスを指します。19〜20世紀にかけて、ディルタイ、ハイデッガー、ガダマー、リクールといった哲学者たちが議論を深めてきた概念です。
ディルタイは、テキストや歴史的事象を理解するには、部分と全体を何度も往復しながら理解を深化させるしかないと主張しました。ハイデッガーはこの循環を存在論的に捉え、私たちが何かを理解するとき、すでに何らかの**先行理解(前理解・先入見)**を持って臨んでいると指摘しました。
ガダマーの「地平融合」とリクールの二重循環
ガダマーはこの議論をさらに発展させ、「地平融合(Horizontverschmelzung)」という概念を提唱しました。解釈者が持つ既存の理解の「地平」と、テキストが持つ意味の「地平」が出会い、融合することで、より深い理解が生まれるというモデルです。ガダマーにとって、理解とは「自らの先入見を危険にさらす行為」であり、解釈者は常に自分の偏見が問い直されるリスクを負いながら意味を掴んでいきます。
一方リクールは、ガダマーと対照的に理解(直接的な把握)と説明(検証的な分析)の双方向的循環を解釈学的プロセスに組み込むべきと主張しました。リクールの枠組みでは、感情的・直感的な理解と論理的・分析的な説明が交互に深まっていくことで、解釈が成熟します。
これらを整理すると、解釈学的循環の基本構造は「前理解 → 部分(断片)への参照 → 全体の仮解釈 → 再解釈による前理解の更新 → ……」という自己相似的なスパイラルとして描けます。
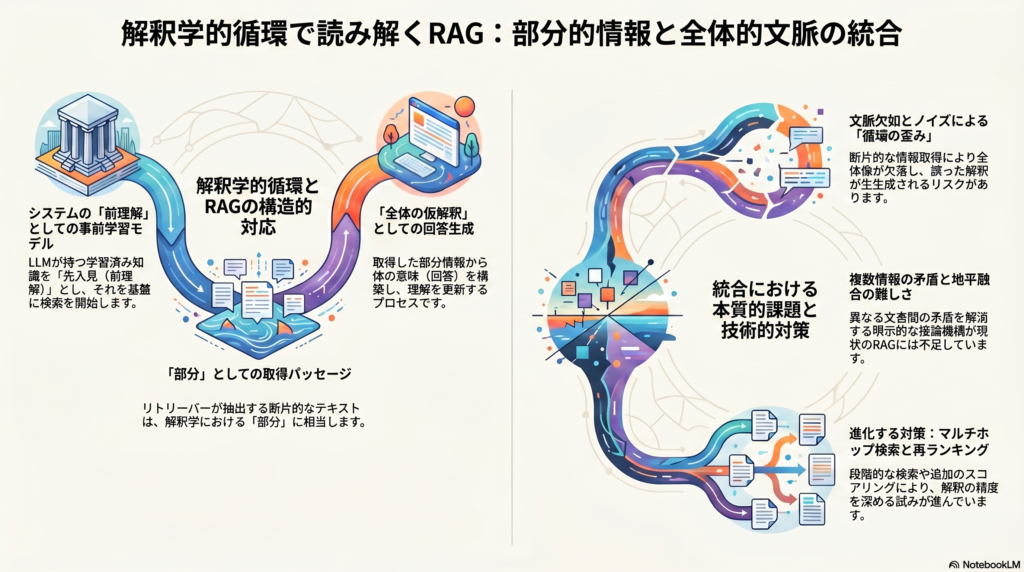
RAGシステムの技術的構成——解釈学的循環との対応関係
RAGの主要コンポーネント
RAGシステムは大きく以下のモジュールで構成されます。
- クエリエンコーダ:ユーザーの入力を埋め込み表現に変換し、類似検索の基盤を提供する
- リトリーバー:BM25などの疎な検索やDPR(Dense Passage Retrieval)などの密な埋め込み検索、あるいはそのハイブリッドにより、外部知識コーパスから上位K件の関連文書を取得する
- 生成器(ジェネレータ):入力クエリと取得文書を組み合わせ、BARTやT5などのTransformerベースのSeq2Seqモデルで回答文を生成する。RAGの原論文(Lewis et al., 2020)では、全生成過程で同一文書を使うRAG-Sequence方式と、各トークン生成時に文書を切り替えるRAG-Token方式が提案されている
- 外部インデックス:Wikipedia等のコーパスをベクトル化して格納した非パラメトリックメモリ
RAGプロセスと解釈学的循環の対応
解釈学的循環とRAGのプロセスは、以下のように対応させることができます。
| 解釈学的概念 | RAGにおける対応要素 |
|---|---|
| 前理解・先入見 | モデルの事前学習済み知識・パラメトリックバイアス |
| 部分(テキストの断片) | リトリーバーが取得した上位K件のパッセージ |
| 全体の仮解釈 | 生成器が出力する回答文 |
| 前理解の更新 | フィードバックや追加検索によるシステム改善 |
モデルは事前学習済みの「前理解」を基盤にしてクエリを解釈し、リトリーバーが返す「部分情報(断片)」をもとに「全体(回答)」を生成します。その回答がユーザーの評価や後続の対話を通じてフィードバックされることで、システム全体の理解が更新されていく——この反復プロセスはまさに解釈学的循環のパターンに合致しています。
部分的情報取得の本質的な限界
断片性と文脈欠如
RAGにおいてリトリーバーが取得するのは、あくまでもコーパス全体の「断片」に過ぎません。上位K件のパッセージが問いに関連する内容を含んでいたとしても、それらは文脈の一部しか表現していない可能性があります。全体像を把握するために必要な前提条件や背景知識が欠落していることは珍しくなく、その結果として生成モデルは不完全な情報をもとに回答を組み立てざるを得ません。
解釈学的に言えば、これは「部分だけを繰り返し参照し、全体への往復が成立していない」状態です。ガダマーが強調したように、部分は常に全体の文脈の中で意味を持ちます。しかしRAGのリトリーバーはテキストの意味的全体性よりもクエリとの類似度スコアを優先するため、意味論的に重要な文脈が欠落したままパッセージが選択されるリスクがあります。
ノイズと冗長性の問題
取得パッセージの中には、クエリとの関連度が低い文書(ノイズ)が混入することがあります。このノイズが生成時のハルシネーション(事実と異なる回答の生成)の一因になり得ることが複数の研究で指摘されています。また、上位K件の中に実質的に同じ内容が繰り返し含まれる「冗長性」の問題も存在し、多様な知識を取り込むべき検索が特定の視点に偏る原因になりえます。
解釈学的循環の観点では、ノイズは「誤った部分情報が前理解を歪め、全体解釈を誤った方向に引き込む」プロセスに相当します。一度形成された誤った全体像は、後続の部分解釈にも影響を及ぼし、循環全体が誤った方向へ収束してしまう危険性があります。
スコープの偏りとマルチホップ問題
コーパスのドメイン偏りや検索クエリの曖昧さにより、特定の側面ばかりが取得され、他の重要情報が抜け落ちることもあります。複数の推論ステップを必要とする「マルチホップQA」のような問題では、単一の検索で必要な情報をすべて取得することが構造的に困難です。これは解釈学が言う「部分から全体への移行が一度では完結しない」問題に対応しており、反復的な検索と解釈のサイクルが不可欠となります。
全体的文脈統合における課題
矛盾する情報の統合
複数のパッセージが相互に矛盾する情報を含んでいる場合、生成モデルはどの情報を採用するか、あるいはどう統合するかを判断しなければなりません。誤った矛盾解消は誤情報の生成につながる可能性があり、これはRAGシステムの信頼性を損なう根本的なリスクです。
ガダマーの地平融合になぞらえれば、複数の「地平」(異なる文書の主張)が衝突したとき、解釈者(生成モデル)は適切な融合を実現できるかが問われます。しかし現状のRAGシステムには、矛盾解消のための明示的な推論機構が内蔵されていないことが多く、生成モデル自身のバイアスや訓練データの偏りが矛盾解消の方向性を左右してしまいます。
長期文脈の維持と推論の一貫性
長文の対話や多段階の推論では、前段階で得た情報を後続のステップでも保持し続ける必要があります。しかし上位K取得による各ステップの検索は独立して行われることが多く、対話の歴史的文脈や推論の流れを一貫して維持する手段が不足しがちです。
リクールが論じた「理解と説明の双方向的循環」に照らすと、RAGには「説明(検証)」のフェーズが弱いという課題があります。生成された回答がどの根拠に基づいているかを検証し、その検証結果を次のサイクルに反映させる機構が整備されていないと、循環は深まらず表面的な往復にとどまります。
既存の技術的対策とその限界
再ランキングとコンテキスト圧縮
取得後に追加のスコアリングを行う再ランキング(Re2G等)は、ノイズ文書の影響を軽減し、取得品質を高める効果が期待できます。ただし計算コストが増大するうえ、初期の候補に適切な文書が含まれていない場合には効果がありません。
コンテキスト圧縮・フィルタリング(FiD-Light等)は冗長情報を削減して生成負荷を下げる一方、圧縮の過程で有用な情報まで失われるリスクがあります。
マルチホップ検索とChain-of-Thought
マルチホップ検索(RQ-RAG等)は複雑な質問を複数の小問に分解し、段階的に検索・回答することで、単一検索では到達できない知識へのアクセスを可能にします。しかし、質問分解の誤りや初期回答の誤謬が後続ステップに伝播する「累積誤り」の問題があり、ステップ数に比例してレイテンシも増加します。
Chain-of-Thought(CoT)型アプローチ(IM-RAG等)は推論プロセスを可視化し、逐次検索を誘導することで整合性の向上が見込まれます。一方、トークン数の増大によるコスト増加や、一度誤った推論の方向に進むと修正が困難になる問題があります。
Fusion-in-Decoder(FiD)型統合と知識グラフ
FiD型融合では、BART/T5のデコーダが複数文書を並列に参照することで、多様な情報を直接統合できます。大量の知識を同時に活用できる利点がある一方、高メモリ・高計算コストが実装の障壁になります。
知識グラフを用いた構造的検索(KRAGEN等)は、エンティティ間の関係をトリプルで表現することで論理的飛躍を減らし、一貫性のある情報取得を目指します。ただし知識グラフ自体の構築・維持が大規模な課題であり、ドメインの変化への追従も難しいため、汎用システムへの適用には制約があります。
これらの対策はそれぞれ一定の効果を持ちながらも、根本的な課題——部分取得の断片性や前理解のバイアス——を完全には解消できていません。解釈学的に言えば、「循環をより深く、より正確に回す」ための工夫であり、循環そのものの構造的限界は依然として残ります。
まとめ——解釈の循環から見えるRAGの可能性と限界
本記事では、エルメネウティック・サークルの視点からRAGシステムにおける部分的情報取得と全体的文脈統合の課題を整理しました。
解釈学的循環が示す「前理解 → 部分 → 全体 → 更新された前理解」というプロセスは、RAGの「事前学習済み知識 → リトリーバーによる断片取得 → 生成器による回答統合 → フィードバックによる更新」という流れに構造的に対応しています。この枠組みを通じることで、RAGが抱える課題——断片性・ノイズ・矛盾・長期文脈の喪失——が、単なる技術的欠陥ではなく、解釈という行為に本質的に伴う困難であることが浮かび上がります。
今後のRAGシステム開発においては、回答の忠実度や文脈再現性を多面的に評価する指標の整備、ユーザーとのインタラクティブなフィードバックループの実装、高品質なドメイン固有データの設計が鍵となるでしょう。解釈学が数百年をかけて深めてきた知見は、AIシステムの設計に対しても示唆に富んだ視座を与え続けます。
コメント