はじめに
複数のエージェントが協調しながら意思決定を行うマルチエージェント強化学習(MARL)は、各エージェントが自分の報酬だけを追うとパレート劣位な均衡に陥りやすいという課題を抱えています。一方、量子強化学習(QRL)は主に量子回路を方策や価値関数の近似器として用いる方向で発展してきました。本記事では、この二つの流れを接続する研究アイデアとして、エージェント内部に量子状態を持たせ、そこに「自己定位モード」と「ボルン重み付き配慮モード」という二つの意思決定様式を組み込む設計を紹介します。前者は分岐後の自分の立場についての不確実性を扱う仕組み、後者は各分岐の結果をどれだけ重視するかを定める仕組みであり、両者は似ているようでいて役割が異なります。
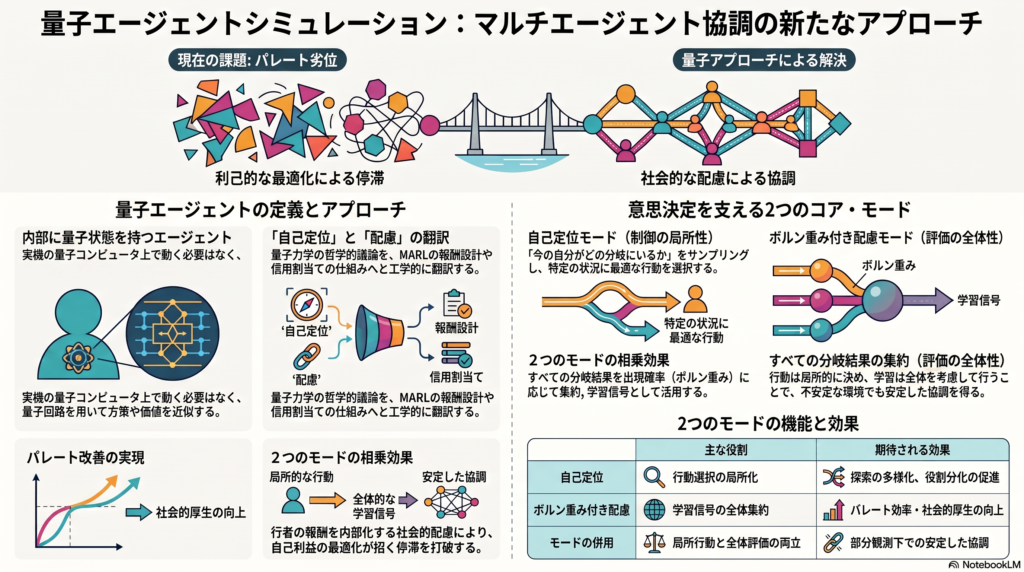
量子エージェントシミュレーションとは何か
ここで言う「量子エージェント」とは、必ずしも実機の量子コンピュータ上で動作する主体を指すものではありません。内部に量子状態を持ち、量子回路または量子に着想を得た表現を用いて方策や価値、内部的な乱択、相関の生成を行うエージェントとして定義するのが実践的です。この定義は、量子強化学習研究で一般的な「ハイブリッド量子古典モデル」や、パラメータ化量子回路を方策近似器として用いる枠組みと整合的です。
背景には、量子力学の解釈をめぐる議論があります。分岐後・観測登録前の主体が、宇宙全体の状態を知っていても自分がどの分岐にいるかを知らないという「自己定位的不確実性」の議論や、確率を単なる主観的不確実性ではなく各分岐へどれだけ重みを置くかという「配慮の尺度」として捉える議論が存在します。これらの哲学的議論をそのまま再現するのではなく、マルチエージェント強化学習における報酬設計や信用割当ての発想へ翻訳する点が、本研究アプローチの核となります。
自己定位モードとボルン重み付き配慮モードの違い
自己定位モードは、行動を選ぶ際に「いまの自分がどの量子分岐に属しているか」をサンプリングし、そのサンプル結果に条件づけられた方策で行動する仕組みです。これは主に行動選択を局所化する役割を担い、観測が不完全な環境において、分岐ごとに異なる反応戦略を持たせやすくする可能性があります。
一方、ボルン重み付き配慮モードは、すべての分岐の結果を、その分岐が生じる確率(ボルン重み)に応じて集約し、学習の評価に反映させる仕組みです。さらにこの仕組みに、他のエージェントの報酬も内部化する社会的な配慮の項を加えることで、自分の報酬だけでなく全体の帰結を考慮した学習信号を作ることができます。協調的なマルチエージェント学習の研究では、各エージェントが自分の報酬だけを最適化するとパレート劣位な均衡に収束しうること、パレート改善には他者の報酬を考慮する利他的な要素が有効であることが示唆されており、配慮モードはこの知見と整合する設計です。
両者は「制御の局所性」と「評価の全体性」という異なる機能を担っているため、片方だけでなく組み合わせて使うことで、部分観測下でもより安定した協調が得られる可能性があります。
数理モデルから見る量子マルチエージェント設計
この研究設計は、複数エージェントが協調するDec-POMDP(分散部分観測マルコフ決定過程)の枠組みの上に構築されます。各エージェントは局所観測を受け取り、行動を選び、環境は次の状態へ遷移し、各エージェントは報酬を得ます。パレート分析のためには、各方策プロファイルに対する割引リターンのベクトルを評価し、支配関係や超体積を測定します。
各エージェントは複数の量子ビットからなる内部のヒルベルト空間を持ち、内部状態は純粋状態または密度行列で表現されます。観測は古典的な前処理を経て量子回路へ入力され、可変回路によって内部状態が更新されます。ノイズを考慮する場合には、開放量子系の時間発展を扱う方程式を用いて数値的に解くことになります。
分岐は、量子状態に対する射影演算子の集合として定義され、各分岐が生じる確率はボルン則に従って計算されます。自己定位モードでは、この確率分布から分岐をサンプリングし、その分岐に条件づけられた方策で行動します。ボルン重み付き配慮モードでは、すべての分岐における報酬を、その確率と配慮の重みに応じて集約し、内部的な効用として用います。両者を併用する条件では、行動の選択は自己定位によって局所的に決め、学習の更新はボルン重み付き配慮による集約効用で行うという構成が考えられます。
なお、すべての分岐の報酬を一度に観測することはできないため、実際の実装では中央集権的な分岐批評家や、共通の乱数を固定した短期的な反実仮想ロールアウトによって推定する必要があります。この推定誤差をどう扱うかは、研究設計上の重要な論点です。
実装に向いたツールとシミュレーション手法
実装を現実的に進めるには、小規模・離散行動・部分観測・協調課題という条件から始めるのが堅実です。エージェントが協調か非協調かを選ぶ繰り返しゲームのような自作環境や、グローバル報酬と局所的な衝突ペナルティを併せ持つ既存のマルチエージェント環境を用いることで、協調と個体損失のトレードオフを自然に観察できます。
学習アルゴリズムとしては、協調的なマルチエージェント設定で強いベースラインとされる方策勾配系の手法を主軸に、比較対象として価値分解に基づく手法を併用する構成が考えられます。量子内部表現を組み込む場合には、勾配が伝搬しやすい手法のほうが扱いやすい傾向があります。
量子シミュレーションの面では、理想的な状態ベクトルシミュレーションと、ノイズを考慮した密度行列シミュレーションの両方を行うことが望ましいです。状態ベクトル表現は指数的にサイズが増大するため、量子ビット数やエージェント数が増えるほど計算コストは急速に重くなります。そのため、各エージェントが独立して小規模な量子状態を持つ設計から始め、エージェント間の厳密な量子相関はごく限定的な追加検証にとどめるのが現実的な進め方だと考えられます。
期待される研究仮説とその意味
この研究アプローチからは、いくつかの仮説が導かれます。第一に、自己定位モードだけでは協調の改善は限定的である一方、探索の多様化や役割分化には一定の効果が見込めるという仮説です。自己定位は方策を分岐ごとに局所化するため、観測が不完全な状況での反応戦略の多様性には寄与しやすいものの、目的関数自体は自分の報酬のままであるため、社会的厚生を直接押し上げる力は弱いと考えられます。
第二に、ボルン重み付き配慮モードのほうが、パレート効率や社会的厚生をより直接的に高める可能性があるという仮説です。他者の報酬や分岐全体の結果を内部化することで、局所的な自己利益の最適化が招くパレート劣位を避けやすくなると考えられるためです。
第三に、両者を組み合わせた条件が、部分観測や通信制限、環境の非定常性のもとで最も安定した協調を示す可能性があるという仮説です。もしこれが支持されるなら、量子的な内部表現の価値は計算速度の向上そのものよりも、確率構造と目的関数設計の自由度を広げる点にあるという解釈が成り立ちます。
これらはあくまで研究上の仮説であり、シミュレーションで肯定的な結果が得られたとしても、それは特定の量子力学解釈の正しさを裏付けるものではない点には注意が必要です。支持されるのはあくまで、分岐を意識した目的関数を持つエージェント設計が協調的なマルチエージェント学習において有効である可能性がある、という工学的な主張にとどまります。
実装上の課題とリスク
この研究アプローチには、いくつかの留意点があります。まずスケーラビリティの問題です。量子状態の厳密な表現は指数的にコストが増大するため、エージェント間の量子相関を厳密に扱う設計は小規模な検証にとどめる必要があります。
次に、反実仮想的な分岐報酬の推定誤差の問題です。ボルン重み付き配慮モードはすべての分岐の結果を必要としますが、実際の相互作用では一つの軌跡しか観測できません。このため、推定に用いる手法のバイアスや誤差が、モード間の比較結果に影響を与える可能性があります。
さらに、ノイズや実機との接続性の問題、そしてどの厚生関数をどのように重視するかという倫理的な設計判断の問題もあります。報酬の総和を高めることだけを目指すと、一部のエージェントが大きな不利益を被る設計になりかねないため、公平性に関する指標を併せて評価する姿勢が重要だと考えられます。
まとめ
量子状態を内部表現に持つエージェントへ、自己定位モードとボルン重み付き配慮モードという二つの意思決定様式を組み込む研究アプローチは、量子強化学習と協調的マルチエージェント学習、そしてパレート分析を結びつける試みです。自己定位は行動選択の局所化を、配慮モードは学習信号の全体的な集約を担うと整理することで、両者の役割の違いが明確になります。仮説として有力なのは、配慮モードが協調性の改善に直接寄与し、両者の併用が部分観測下での安定性をさらに高める可能性があるという見立てですが、これらは今後のシミュレーションによる検証が必要な段階にあります。
コメント