はじめに:なぜ秩序パラメータの「自動抽出」が難しいのか
秩序パラメータとは、もともと相転移理論において「相転移の一方の側でゼロ、他方で有限値をとる」巨視的な量として定義されてきた概念です。磁性体における磁化や、化学系における反応座標(reaction coordinate)など、系の「状態」を少数の変数で要約する役割を担います。
この概念を観測時系列から「自動的に」抽出しようとするとき、単純な次元圧縮や再構成精度の最大化では十分でないことが知られています。なぜなら、求められるのは「再構成が上手い潜在変数」ではなく、巨視的状態の識別・遅いダイナミクスの保持・因果的一貫性・物理的可読性・再現性をすべて同時に満たす低次元表現だからです。
本記事では、こうした要件を満たす多段パイプラインの設計思想から、具体的な手法の選択基準・実装指針まで、研究者・エンジニア向けに体系的に整理します。
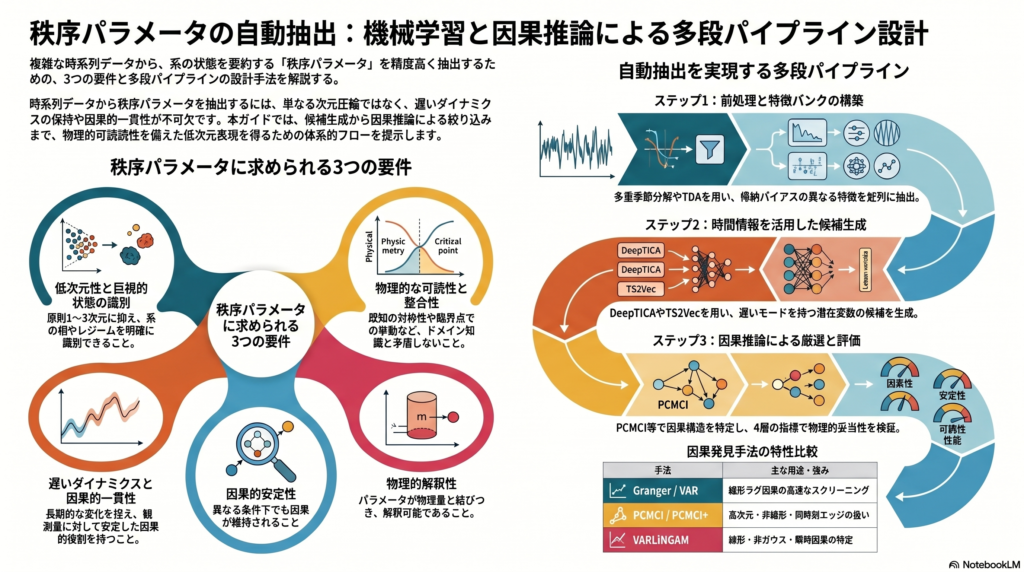
秩序パラメータ自動抽出の5つの要件
候補となる潜在変数 $z_t = f_\theta(x_{1:t})$ に課すべき条件は、次の5点に整理できます。
1. 低次元性
原則として1〜3次元、多くとも8次元未満に抑えることが推奨されます。次元が増えるほど解釈性と汎化性が落ち、「何を表しているか」が不明瞭になります。
2. 巨視的状態の十分性
相・状態・レジーム・周期位相・同期度など、系の巨視的な振る舞いを識別できることが必要です。ただ「変動を再現する」だけでは不十分です。
3. 遅いダイナミクスの保持
未来予測や長時間自己相関が崩れないこと。相転移や状態遷移のような「ゆっくりした変化」を捉えられているかが重要な評価軸になります。
4. 因果的一貫性
調整(conditioning)後も、downstream の観測量への効果や媒介が安定して確認されること。相関が強いだけでは不十分で、因果グラフ上での役割が明確である必要があります。
5. 物理的可読性
既知の対称性・単調性・臨界点近傍の変化・周波数成分・振幅と位相などと整合していること。分野の知識と矛盾しない潜在変数であることが、最終的な信頼性を担保します。
多段パイプラインの全体設計
「単一モデルで真の秩序パラメータを決め打ちする」より、複数の役割分担を持つパイプラインが現実的です。推奨されるフローは以下のとおりです。
生時系列データ
↓ 品質監査・再サンプリング・欠損処理
↓ STL/MSTL 分解
↓ 特徴バンク構築(スペクトル・自己相関・TDA・遅延座標)
↓ 候補生成バンク(教師あり・時間情報付き・自己教師あり・生成モデル)
↓ 因果発見(Granger / PCMCI / FCI / LiNGAM)
↓ 因果効果推定(DoWhy / EconML / Tigramite)
↓ 物理・化学・生理妥当性検定
↓ 安定性選別・Paretoランク付け
最終秩序パラメータと不確実性推定このフローで重要なのは、「候補を広く出す」段階と「候補を削る」段階を明確に分離している点です。表現学習器は候補生成の役割を担い、因果推論は候補の絞り込みを担います。
前処理:「データを整理する」工程の重要性
観測時系列をそのままモデルに投入すると、欠損・不規則サンプリング・多重季節性・非定常性に起因する擬似相関を「秩序パラメータ」と誤認するリスクがあります。前処理は単なる準備作業ではなく、結果の信頼性を左右する工程です。
時刻軸の整備
不規則サンプリングが含まれる場合、まず Lomb–Scargle スペクトル解析のような不等間隔系列対応の手法を使うことが推奨されます。均一再サンプリングへの無理な変換は情報を歪めます。
多重季節分解(STL/MSTL)
複数の周期性が重なっている場合はMSTLを用いて trend・seasonal・residual に分解してから特徴抽出や因果探索を行うと、擬似相関が減少します。
欠損値の扱い
欠損メカニズム(MCAR/MAR/MNAR)を区別することが重要です。系列依存を壊す単純削除は避け、短い欠損には補間、季節性のある単変量にはSTL+Kalman系、多変量・高欠損には深層補完が候補になります。ただし、補完法の誤差が下流の因果推論に伝播することを常に意識する必要があります。
特徴バンク構築:異なる帰納バイアスを並列に持つ
特徴抽出の段階では、帰納バイアスの異なる複数の視点から特徴を並列に持つことが重要です。最低限含めるべき特徴群は以下のとおりです。
- スペクトル特徴:Welch法、Lomb–Scargle
- 自己相関・偏自己相関(ACF/PACF)
- トレンド/季節/残差:STL/MSTLによる分解結果
- 遅延座標による再構成状態空間:Takens埋め込みに基づく
- トポロジカル特徴(TDA):persistent homologyによる構造把握
実装面では、tsfresh や TSFEL で大量の統計・スペクトル特徴を自動生成し、giotto-tda でTDAパイプラインを構築する組み合わせが実務的です。
候補生成:手法の役割分担と選択基準
候補生成では、「競合させる」のではなく「候補バンクとして併用する」設計が有効です。
教師ありアプローチ:DeepLDA / DeepTDA
相状態ラベルや既知レジームが存在する場合に強力です。解釈性が高く、supervised baseline として最初に試す価値があります。
時間情報を直接使う無教師学習:DeepTICA・VAMPnets・Time-lagged Autoencoder
単純なAE/VAEは時間方向の重要性を落としやすい弱点があります。これらの手法は「遅いモード」や「マルコフ的な潜在変数」を目的関数に直接組み込んでいるため、物理・化学系での第一候補になります。Python ライブラリ mlcolvar でこれらをまとめて比較できます。
汎用自己教師あり表現学習:TS2Vec
ラベルがなく系列が長い場合や欠損がある場合に有効な汎用ベースラインです。階層的対照学習によりスケール不変表現を学習し、欠損入力でも比較的安定した挙動を示します。
VAE・拡散モデルの位置づけ
VAEは潜在空間の候補生成には有用ですが、学習される潜在軸が損失設計に強く依存するため、「そのまま秩序パラメータ」と見なすのではなく、候補として因果・物理検証に回すことが適切です。拡散モデルは現時点では秩序パラメータ抽出の主戦力というよりも、欠損補完や候補拡張の補助手段として位置づけるのが現実的です。
因果推論:「相関と因果を区別する」ための第二段
因果推論は、「相関の強い潜在変数」と「秩序パラメータらしい潜在変数」を区別するための重要な工程です。
因果発見の手法選択
| 手法 | 主な用途 |
|---|---|
| Granger / VAR | 線形ラグ因果のスクリーニング。高速で動くベースライン |
| PCMCI / PCMCI+ | 高次元・非線形・同時刻エッジを扱える中心手法 |
| PC / FCI | 制約ベース法。FCI は潜在交絡を許容する |
| VARLiNGAM / TS-LiNGAM | 線形・非ガウス・瞬時因果が想定できる場合に有力 |
推奨構成は、生特徴と潜在候補の両方に対して因果発見を実行し、潜在変数がネットワーク構造の中でどの位置に現れるか(媒介変数か、根本変数か)を確認することです。
因果効果推定:「グラフを描いて終わり」にしない
因果グラフを得た後は、各候補変数が downstream observables に与える total / direct / mediated effect を定量的に推定します。DoWhy + EconML の組み合わせにより、高次元共変量下でのCATEや、placebo検定・subsample感度分析を実行できます。Tigramite の CausalEffects は一般化backdoor推定と媒介解析を扱えます。
調整集合を変えたときに効果の符号や大きさが不安定な候補は、「相関に過剰適合した潜在量」として降格させることが推奨されます。
評価設計:4層の指標で候補を絞り込む
再構成誤差や予測性能だけでは不十分です。評価は以下の4層で設計します。
- 表現品質層:再構成誤差、潜在次元の圧縮率
- 時間予測品質層:一歩先・マルチステップ予測、状態遷移分類
- 遅いダイナミクス再現層:長時間自己相関の保持、VAMP/TICA的slow modeの保持
- 因果品質層:SHD・TPR・FDR、効果推定誤差、refutation pass rate
特に合成データ検証では、Ising相転移・Brusselator型反応振動子・Kuramoto概日時計ネットワークといった「既知の秩序パラメータと因果構造を持つ系」で、各層の指標を同時に測ることが推奨されます。
実装指針:モジュール構成と計算資源の目安
ライブラリ構成
- 前処理:SciPy、statsmodels(STL/MSTL、Lomb–Scargle、ACF/PACF)
- 特徴化:tsfresh、TSFEL、giotto-tda
- 表現学習:PyTorch + mlcolvar(DeepTDA・DeepTICA・VAMPnets等をまとめて扱える)
- 因果発見:Tigramite、causal-learn、lingam
- 因果効果推定:DoWhy + EconML
計算資源の目安
- CPUのみ:特徴抽出・Granger・VAR・PC・小規模PCMCI
- GPU(12〜24GB):TAE・TS2Vec・VAE・DeepTICA・VAMPnets
- GPU(24GB以上):長系列・多候補学習・拡散補完
ただしこれはあくまで目安であり、系列長・変数数・バッチ設計によって大きく変わります。
ハイパーパラメータの初期設定指針
- 窓長:主周期の4〜10倍、または系列長の5〜20%
- 遅延埋め込みの遅れ τ:自己相関の 1/e 低下点か相互情報量の第一極小
- 潜在次元:1〜8を候補にし最小有効次元を選択
- PCMCI の τ_max:既知周期・自己相関長に基づき5〜50程度から探索
まとめ:「よく予測できる」より「因果的に読める」潜在変数を選ぶ
秩序パラメータの自動抽出において最も重要な原則は、「再構成や予測が上手い潜在変数」ではなく、「因果的に一貫し、物理・化学・生理学的に意味を持つ潜在変数」を選ぶことです。
そのためには、時間情報を活かした表現学習で候補を広く生成し、因果発見と効果推定で候補を絞り込み、ドメイン知識と安定性選別で確定する、という多段手法が現時点で最も実装可能な戦略といえます。
現在の研究には、識別可能性の問題・因果発見の非定常性への脆弱性・補完と因果推論の分離・生成モデルの解釈可能性という4つの主要なギャップが残っています。これらを克服するべく、物理拘束付き因果表現学習や end-to-end 統合フレームワークの研究が今後の焦点になるでしょう。
コメント