ルーマンの社会システム論は、高度な抽象性ゆえに「美しいが検証できない理論」と評されることがある。しかしその核心にある構造的カップリングという概念は、適切な観測設計があれば、実際のコミュニケーション・データや制度変化の痕跡として観測できる可能性がある。本稿では、「どの指標が使えるか」「どのモデルで推定するか」「どのデータを集めるか」という実践的な問いに沿って、ルーマン理論の実証化に向けた研究設計を整理する。
ルーマン理論の「実証化」とはなにか
「直接測定できない」から始める
「社会はコミュニケーションの自己産出系である」というルーマンの根本命題を、そのまま数値に落とすことはできない。これは理論の欠点ではなく、射程の違いの問題だ。目指すべきは命題そのものの直接測定ではなく、その命題が予測するパターンの観測である。
ルーマン理論の核心である「社会は人間ではなくコミュニケーションから成る自己産出系である」という命題そのものを直接測ることはできないが、自己再生産するコミュニケーション系列が、他システム由来の刺激を自システムのコードに翻訳しつつ反復的に取り込むパターンは、テキスト・ネットワーク・制度イベントの複合指標としてかなりの程度まで観測可能である。
この整理は、佐藤俊樹の再構成とも整合的だ。佐藤は、ルーマン理論を経験的に使うには、観察対象を「自己再生産の経験的観察が可能な通信系列」に限定すべきだと述べている。つまり、「すべての社会現象を測る」という過大な野心を一度手放し、「どの現象なら観測可能か」を先に確定させることが、実証化の第一歩になる。
構造的カップリングの操作的定義
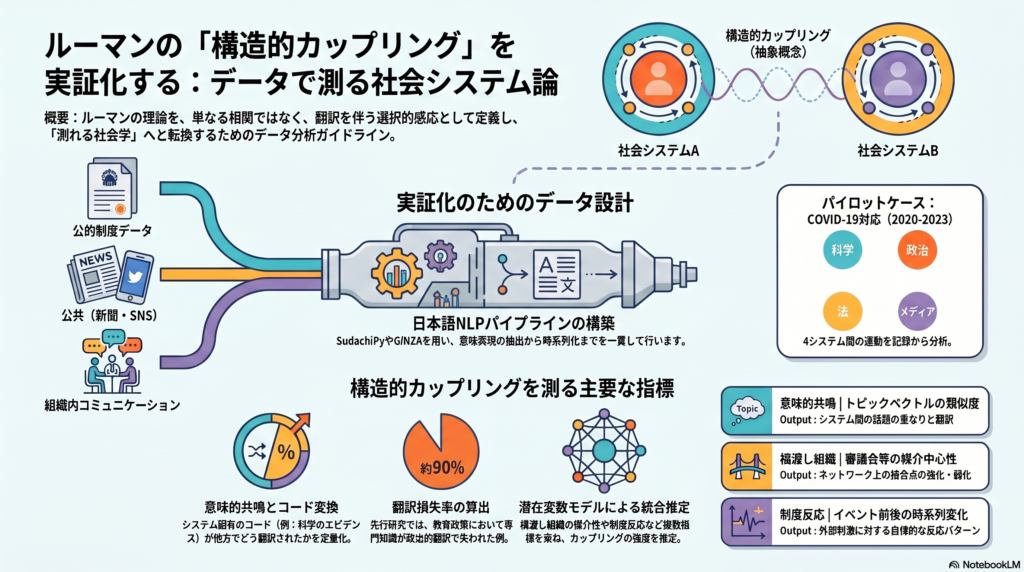
研究の中核仮説は、構造的カップリングを「二つのシステムが融合すること」ではなく、各システムが操作的閉鎖を保ったまま、特定の外部刺激に対して選択的に敏感になる関係として定義し、その痕跡を、制度イベント前後の話題変化、コード変換、参照ネットワーク、橋渡し組織の媒介、翻訳損失率の変動として推定する、というものである。
単なる「相関」ではなく「翻訳を伴う選択的感応」を観測しようとしている点が、この定義の核心だ。システム間に話題の重複が見られたとしても、それがそれぞれのコードに従って処理されているかどうかが問われる。
先行研究が示す「測定の足がかり」
助言・標準・翻訳損失という三つの切り口
直接的にルーマン理論を実証に用いた研究は多くないが、すでにいくつかの重要な先例がある。
日本のCOVID-19対応を対象とした酒井晃介は、助言(advice)を科学システムと政治システムの構造的カップリングとして経験的に示した。助言とは一方向の「影響」ではなく、距離を保ちながら両システムを連関させる界面として理解される。これは、専門家会議のような組織が「どちらのシステムにも属しながらどちらにも還元されない」という機能を持つことを実証的に示すものである。
Knudsenは医療における標準(standards)を分析し、標準化が医療組織を複数の機能システムに対して「いらだちやすくする」ことで構造的カップリングを形成すると論じた。ここでの発見は、構造的カップリングが「言説内容」だけでなく、「どの規則や標準が決定系列を媒介しているか」にも表れるという点だ。
そして最も数量的に具体的な先例が、Steiner-Khamsiの教育政策研究における翻訳損失の分析だ。ノルウェーの教育改革では、白書が引用した232本の文献のうち、委員会報告と共有されていたのは22本、すなわち9.5%にすぎず、90.5%の知識が政治的翻訳過程で失われたと報告された。
ルーマン的には、この「損失」は失敗ではなく、機能分化したシステム間での翻訳の必然的選択性を示す、極めて重要な観測痕跡である。「失われた知識」を定量化できること、そしてそれが理論的に意味を持つことが、この研究の重要な示唆だ。
データ設計:何を、どこから集めるか
公的制度データを中核に置く
本研究で想定するデータは、公的制度データ、公共コミュニケーション・データ、組織内コミュニケーション・データの三系統に分けるのがよい。
公的制度データの中核は、日本の国会会議録検索システム、e-Gov法令検索API、e-Govパブリック・コメント、国立公文書館デジタルアーカイブである。これらは制度的イベント、法改正、政府解釈、答弁連鎖、行政の応答性を追跡するうえで最も信頼性の高い公開ソースだ。
公共コミュニケーション・データとしては、新聞については、朝日新聞クロスサーチ、マイサク(旧毎索)、読売のヨミダスなど新聞データベースが利用でき、SNSについてはX APIが公開会話へのプログラム的アクセスを提供し、YouTube Data APIも動画・コメント・チャンネルに関連するデータ取得を可能にする。
組織内コミュニケーションについては、倫理的制約と実現可能性の観点から段階的に取り組むのが現実的だ。最初の実証は公開データ中心で行い、アクセス権限付き組織データは第2段階以降の拡張ケースとして扱う方が現実的である。
前処理パイプラインの設計
前処理は、日本語データを前提として、正規化→分割→形態素解析→意味表現→関係抽出→時系列化の順で行う。形態素解析にはSudachiPyを、依存構造・固有表現・品詞情報の統合にはGiNZAを用いるのが妥当である。
トピック推定にはLDAかSTMをベースにしつつ、短文が多いSNSではBERTopicのような埋め込み+c-TF-IDF型の手法が有利なことが多い。
時間粒度は日次・週次・月次の複数解像度を保持し、後の感度分析で比較する。特に構造的カップリングはイベント前後の短期変化と、制度的沈殿としての長期変化の双方に現れうるため、複数粒度の同時保持が必須である。
指標の設計:四つの観測軸
意味的共鳴・コード整合・橋渡し組織・制度反応
構造的カップリングを観測するための指標は、単一のものに絞らず、複数の系統から束ねることが重要だ。
意味的共鳴指標では、各システムの文書集合からトピックベクトルを推定し、橋渡し文書から推定した翻訳行列を通じてシステム間の意味的類似度を計算する。重要なのは、これが高く、しかも同時にAの自己再生産指標が高いままであれば、Aはbに「吸収」されたのではなく、B由来の刺激をA的に翻訳している、と解釈しやすい。吸収と翻訳の区別こそが、ルーマン的な分析の核心になる。
コード整合的刺激指標では、各文書に対し「科学的証拠/政治的正統性/法的適法性/メディア的ニュース価値」などのコード近似を教師あり分類または辞書法で付し、コード分布ベクトルを推定する。たとえば、科学システムの「有効性・リスク・エビデンス」が、政治システム側で「実施可能性・説明責任・社会的受容」に変換されるなら、その翻訳規則自体が構造的カップリングの一部である。
橋渡し組織指標では、酒井の助言研究やKnudsenの標準研究が示したように、構造的カップリングはしばしば審議会、専門家会議、中央銀行、憲法裁判所、標準化組織のようなインターフェース組織で濃縮される。これらの組織が二部グラフ上でどれだけ媒介中心性を持つかを時系列で追跡することで、カップリングの強化・弱化を観測できる。
制度イベント反応指標では、法改正や専門家委員会設置、危機宣言などをイベントとし、前後の時系列変化を反実仮想と比較する。ここで重要なのは解釈の仕方だ。これを「Aがbを直接変えた」と読むのではなく、イベントがBの内部コミュニケーションの選択構造をどの程度ずらしたかとして解釈することである。
統合モデル:潜在変数としてのカップリング強度
複数指標を束ねることの意味
この計画の要点は、構造的カップリングを単一指標で断定しないことにある。代わりに、自己再生産、翻訳、橋渡し、制度反応という四系統の観測量を束ねて、「カップリングが強い」と解釈できる潜在構成概念として推定する。
最終的な推定は階層ベイズ・状態空間モデルを用いた潜在変数モデルとして設計する。潜在カップリング状態をAR(1)過程として置き、意味的共鳴、コード整合、媒介中心性、翻訳損失率、制度反応などを観測指標として読み込む。こうすると、「自己再生産が強いが外部刺激への感応も強い」という、ルーマン的にもっとも重要な組合せが一つの潜在状態として推定できる。実装にはPyMCかStan、診断にはArviZが使いやすい。
パイロットケース:日本のCOVID-19対応
四つのシステムを横断する分析
実証デザインとして最も適切なのは、日本のCOVID-19対応を対象とし、科学・政治・法・マスメディアの四システムを観測する設計である。期間は2020年1月から2023年12月を基本とし、必要に応じて2024年まで延長する。
このケースが適切な理由は複数ある。酒井の先行研究が既に理論的足場を与えていること、国会・行政・専門家会議・法改正・新聞・SNSの公開記録が比較的充実していること、そして危機対応の制度イベントが明瞭であることである。
サンプル規模についても現実的な見通しが立てられる。パイロットケースでも5万〜20万文書規模、発話単位なら数十万発話、制度イベントは50〜200件程度を見込むのが妥当である。
妥当性検証の四層構造
単に推定するだけでなく、その推定がどこまで信頼できるかを複数の方向から確認することが研究品質を支える。
妥当性検証は四層で行う。第一に、構成概念妥当性として、トピックとコードの人手評価、外部専門家評価、既存分類との整合性を確認する。第二に、識別妥当性として、カップリング潜在変数に少なくとも三系統以上の指標を読み込ませ、単一指標依存を避ける。第三に、外的妥当性として別政策領域に複製する。第四に、感度分析として、時間窓、トピック数、辞書、ニュースソース、SNS有無、橋渡し組織の含め方を変えて推定を比較する。
限界と倫理的配慮
「直接作用の証明」にはならない
構造的カップリングは本質的に潜在構成概念であり、観測されるのはあくまでその痕跡であって、概念それ自体ではない。また因果推論は可能でも限定的であり、ルーマン自身の理論前提からして、他システムへの直接作用を証明する研究にはならない。証明できるのは、制度イベントや橋渡し組織を契機として、あるシステムが外部刺激に対してどの程度・どの形で自分自身の通信規則に従って反応したか、である。
倫理的配慮については、公開データであっても、引用断片が検索可能である以上、再同定と二次被害の危険は残る。したがって、公開時は集計値・埋め込み空間・匿名化済み参照IDを基本とし、原文の公開は最小限とする。
まとめ:「抽象理論」を「使える方法」へ
本稿で整理した研究設計の核心は、構造的カップリングを単一の指標で断定するのではなく、自己再生産・翻訳・橋渡し・制度反応という四系統の観測量を束ねて潜在構成概念として推定するという方針にある。先行研究が示すように、知識の「翻訳損失率」や「橋渡し組織の媒介中心性」は、すでにデータから取り出せる指標として機能しうる。
重要なのは、ルーマン理論が本来持つ「非因果的・非還元主義的な発想」を保ちながら、同時に再現可能な分析手続きを設計するという、両立が難しく見えるが実は整合的な要請に応えることだ。「測れない理論」から「痕跡を観測できる理論」への転換は、理論の精度を落とすのではなく、理論が照らせる現実の範囲を具体化することを意味する。
コメント