導入:なぜ「AIの見ている世界」を問う必要があるのか
生成AIやロボット制御モデルが急速に普及する中で、「どのAIが優れているか」はベンチマークの数値だけで語られがちです。しかし、モデルごとに入力・出力・学習目的がまったく異なる以上、そもそも「同じ土俵で比較できているのか」という問いが見落とされやすくなっています。
この記事では、生物学の「環世界(Umwelt)」という考え方をAIに応用し、モデルごとに異なる意味世界をどう捉え、どう比較していけばよいのかを整理します。まず環世界という概念の起源を簡単に確認したうえで、AIへの応用のしかた、そして具体的な比較の視点について順番に見ていきます。
環世界とは何か──生物学の概念からAIへ
ユクスキュルの環世界論
「環世界」は、生物学者ユクスキュルが提唱した概念で、客観的に存在する「環境」と、生物一個体にとって意味を持つ「環世界」を区別する考え方です。同じ場所にいても、種によって知覚できるものや反応できるものが異なるため、それぞれの生物は独自の意味世界の中で生きているとされます。
たとえばダニは、視覚や聴覚をほとんど使わず、酪酸のにおいや温度、着地の感触といったごく限られた手がかりだけを頼りに行動します。ダニにとっての世界は、人間が見ている世界とはまったく異なる、極めて限定された知覚と行動の組み合わせで構成されているのです。
知覚世界と作用世界の結びつき
環世界論では、生物が知覚する世界(知覚世界)と、生物が働きかけることのできる世界(作用世界)が、一つの循環構造(機能環)として結びついていると説明されます。何を知覚できるかと、何に対して行動できるかは切り離せない、という視点です。この「知覚と行動のセット」という考え方が、AIモデルの比較にも応用できる可能性があります。
AIモデルにも「環世界」がある
モデルごとに切り出す世界が違う
現在広く使われているAIモデルには、大きく分けて次のようなタイプがあります。
- 大規模言語モデル(LLM):テキストを中心に学習し、次の単語を予測する形で訓練される
- 視覚言語モデル(VLM):画像とテキストの対応関係を学習し、視覚的な概念と言葉を結びつける
- 強化学習エージェント:環境との相互作用から得られる報酬をもとに、行動方針を学習する
- ロボット制御モデル(VLA等):視覚・言語の知識とロボットの動作データを組み合わせて学習する
これらのモデルは、そもそも受け取る情報の種類(テキストか、画像か、状態変数か)、出力できる行動の種類(文章か、分類か、ロボットの動作か)、そして何を目指して学習しているか(次の単語の予測か、累積報酬の最大化か)がまったく異なります。つまり、同じ「AI」という言葉でくくられていても、それぞれが切り出している「意味のある世界」自体が違っている可能性があるのです。
環世界という視点で捉え直すメリット
こうした違いを「性能の優劣」としてだけ捉えると、本質的な違いが見えにくくなります。環世界という視点を導入すると、次のような問いを立てやすくなります。
- そのモデルは、どのような差異を「意味のある違い」として区別しているのか
- その差異に対して、どのような行動を取ることができるのか
- その差異は、時間が経ってもどれくらい保持されるのか
- その差異は、学習目的によってどれくらい重要視されるのか
これらを整理することで、単純な性能比較では見えてこない、モデルごとの「得意な世界」と「苦手な世界」を浮かび上がらせることができます。
モデルタイプ別に見る環世界の特徴
言語モデルの環世界
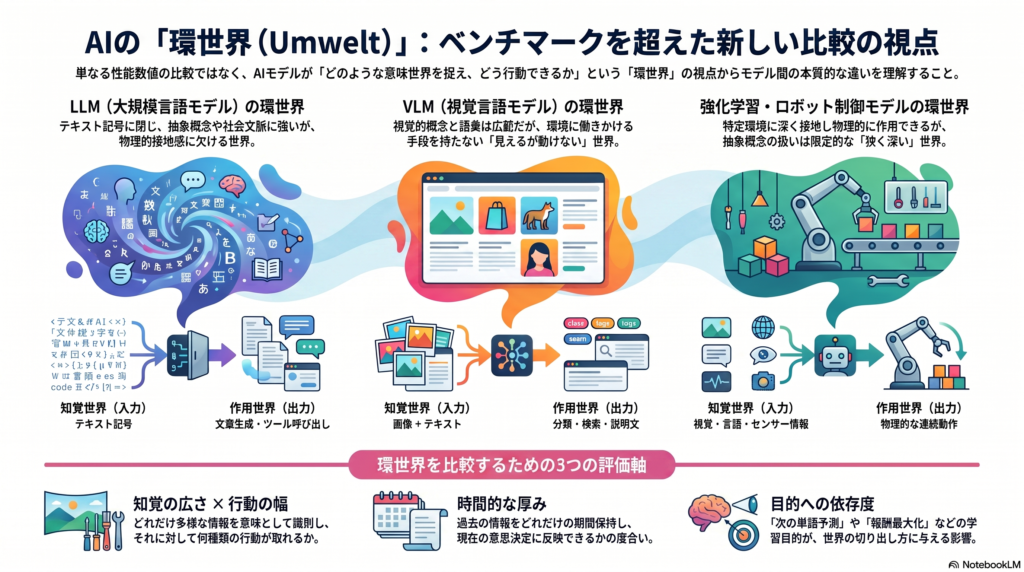
LLMは、テキストという記号を通じて世界を捉えています。そのため、抽象的な概念の扱いや、社会的な文脈の読み取りには強みを発揮しやすい一方で、物理的な空間や連続的な動作といった、身体を通じた世界の捉え方には弱さが出やすいと考えられます。テキストという入力・出力に閉じている以上、行動の幅も基本的には言葉やツールの呼び出しに限られる傾向があります。
視覚言語モデルの環世界
画像とテキストを対応づける形で学習するモデルは、視覚的な概念の幅広さという点で強みを持つ可能性があります。一方で、こうしたモデルの多くは分類や検索といった出力にとどまり、環境に直接働きかける手段を持たないため、「見えるが動けない」世界になりやすいと考えられます。
強化学習エージェントの環世界
強化学習によって訓練されたエージェントは、特定の環境の中で行動し、報酬を最大化するように学習します。そのため、訓練された環境の中では行動の選択肢や結果の予測において深い理解を持ちやすい一方、訓練環境から外れた状況や、記号的・抽象的な概念の扱いには弱さが出やすいと考えられます。「狭いが深い」世界と表現できるかもしれません。
ロボット制御モデルの環世界
視覚・言語の知識とロボットの動作データを組み合わせて学習するモデルは、言葉の指示と実際の動作を結びつけるという点で、より現実世界に接地した世界を持ちやすいと考えられます。ただし、こうしたモデルは特定のロボットの構造やセンサーの制約に強く依存するため、異なるハードウェアへの応用には課題が残りやすい傾向があります。
異なるAIをどう比較すればよいか
表現の比較だけでは不十分
異なるモデルの内部表現を比較する手法として、表現類似性解析などの手法が研究の分野で用いられています。こうした手法は、複数のモデルが同じ刺激に対してどのような内部的な近さを形成するかを調べるのに役立ちます。
しかし、環世界という視点に立つと、内部表現の近さだけを見るのでは不十分だと考えられます。なぜなら、環世界は表現だけでなく、「その差異に対して何ができるか」「その差異をどれくらい重視するか」「その差異をどれくらいの時間保持するか」という要素も含んでいるからです。
比較のための複数の視点
異なるタイプのモデルを公平に比較するためには、次のような複数の観点を組み合わせることが有効だと考えられます。
- 知覚の広さ:どれだけ多様な情報を意味のある差異として取り込めているか
- 行動の幅:認識した差異に対して、どれだけ多様な行動を取ることができるか
- 目的への依存度:学習目的が変わったときに、行動や表現がどれだけ大きく変化するか
- 時間的な厚み:過去の情報をどれだけ保持し、行動に反映できるか
- 説明のしやすさ:内部で何が起きているかを、人間が理解できる形でどれだけ再現できるか
こうした複数の観点を組み合わせることで、「性能が高いかどうか」ではなく、「どのような世界を、どのように切り出して生きているモデルなのか」という、より本質的な比較が可能になっていく可能性があります。
ブラックボックスなモデルへの対応
近年の高性能なモデルの中には、内部の構造や学習データの詳細が公開されていないものも少なくありません。こうした場合には、内部表現に直接アクセスできなくても、モデルの振る舞いや出力の一貫性を観察することで、間接的に環世界の特徴を推測するアプローチが有効になると考えられます。
まとめ:AI比較の新しい視座として
この記事では、生物学の「環世界」という概念をもとに、AIモデルごとに異なる意味世界を捉える視点を紹介しました。要点を整理すると次の通りです。
- 環世界とは、主体が知覚できる世界と、働きかけられる世界が結びついた、主体固有の意味世界のことである
- LLM・視覚言語モデル・強化学習エージェント・ロボット制御モデルは、それぞれ入力・行動・学習目的が異なり、切り出している世界そのものが異なっている可能性がある
- 単純な性能比較だけでなく、知覚の広さ、行動の幅、目的への依存度、時間的な厚みといった複数の観点を組み合わせることで、モデルごとの特徴をより深く理解できる可能性がある
AI技術が多様化する中で、「どちらが優れているか」という単純な比較から一歩進んで、「それぞれのモデルがどのような世界を生きているのか」という視点を持つことは、今後のAI活用や研究の方向性を考えるうえで、有用な手がかりになっていくと考えられます。
コメント