AIは「意味」を生成しているのか——バイオセミオティクスが問う根本問題
AIが生成するテキストや画像は、人間にとって極めて自然に「意味のある」ものとして受け取られる。しかし、その記号が本当に「意味を持つ」のか、それとも統計的な整合性に過ぎないのか——この問いに対して、生命現象を記号過程として捉える学際領域「バイオセミオティクス」は、鋭い分析の枠組みを提供する。
本記事では、Peirceの三項記号論、Uexküllの環世界(Umwelt)と機能環、そしてSebeok以降の生物記号論という理論的背景をふまえつつ、LLM(大規模言語モデル)・拡散モデルによる画像生成・ロボット統合という三つの技術領域を横断的に分析する。その目的は「AIに意識があるか」という問いを棚上げし、「意味のどの成分がどの構成要素によって担保されるか」を設計可能な仮説として明確化することにある。
バイオセミオティクスとは何か——生命を記号過程として読む
Peirceの三項記号論:意味は二項対応では閉じない
記号論の古典的な問いは「記号と対象の関係」にあるが、Charles Sanders Peirceはこれを二項ではなく三項関係として定式化した。Peirceの枠組みでは、記号(representamen)——対象(object)——解釈項(interpretant) という三つの要素が不可分に絡み合うことで、はじめて意味が生成・更新される。
ここで重要なのは、「記号↔対象」の二項対応だけでは意味が閉じないという点だ。解釈項——それは別の記号であったり、理解であったり、行為傾向であったりする——が媒介することで、意味は静的な対応ではなく動的なプロセスとして立ち現れる。
さらにPeirce系の伝統では、対象との関係に基づく三分類——アイコン(類似)/インデックス(隣接・因果)/シンボル(慣習的対応)——が重要な分析道具として機能する。バイオセミオティクスはこの分類を、言語以前の生物過程(細胞内シグナル・動物行動)へと拡張する際の概念装置として活用してきた。
Uexküllの環世界と機能環:生物はそれぞれの意味世界を生きる
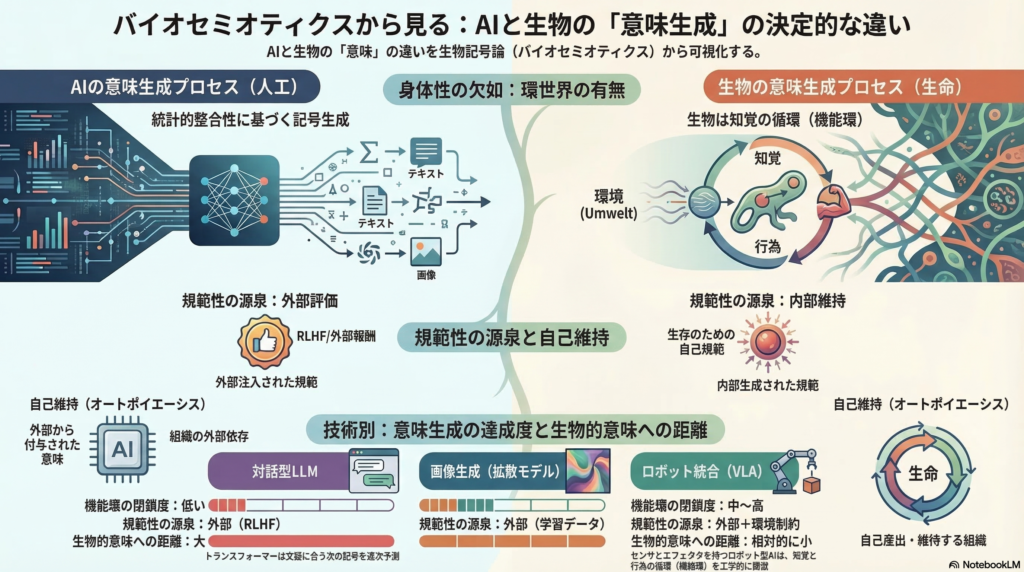
Jakob von Uexküllが提起した「環世界(Umwelt)」という概念は、環境を客観的な外界として一括するのではなく、各生物が感覚器・運動器・生活史的要請を通じて切り出す「種特異的・主体特異的な意味世界」として捉え直す。ダニは光・温度・酪酸という三つの知覚記号のみで生きており、その環世界は人間のそれとは根本的に異なる。
この環世界の構成メカニズムとして中核に置かれるのが**機能環(Funktionskreis)**である。これは直線的な刺激—反応ではなく、「知覚→内的状態(意味づけ)→行為→環境変化→新たな知覚」という再帰的な循環として記述される。この閉じた循環こそが、意味生成の最小機構であるとUexküllは論じた。
Sebeok以降の制度化:細胞から社会まで
Thomas A. Sebeokは動物記号論(zoosemiotics)を軸に生物学と記号論を接続し、バイオセミオティクスを一つの研究プログラムへと制度化した。その後、Jesper HoffmeyerとClaus Emmecheによるコード二重性(code-duality)——遺伝的コードと解釈・行為のコードが二層的に絡み合うという見取り図——が提出され、分子生物学・発生・行動を「コード/解釈」の問題として再記述する方向性が確立された。
Kalevi KullやDonald Favareauらはさらに、「何を記号と見なすか」「解釈はどこで起きるか」「規範性はどう生じるか」という問いを明確化し、バイオセミオティクスを検証可能な研究プログラムへと洗練させている。
AI記号生成の技術基盤——LLM・拡散モデル・ロボット統合
LLMの生成原理:次トークン予測という記号連鎖
現代のLLMはTransformerアーキテクチャを基盤とし、自己注意(self-attention)機構によって系列内の長距離依存を捉えながら次トークンを予測する。基本的な学習目的は「文脈に条件づけられた次トークン分布の予測」であり、GPT-3やGPT-4はこの事前学習によってfew-shot汎化能力を示した。
生成過程は、出力確率分布からの逐次サンプリングとして理解できる。温度・top-p等のパラメータは、生成される記号列の多様性と一貫性のトレードオフを調整する手段だ。さらにRLHF(人間フィードバックに基づく強化学習)——InstructGPTに代表される枠組み——は、「ユーザが望む応答」という社会的規範を報酬として注入し、モデルの振る舞いを整合させる。
拡散モデルによる画像生成:ノイズから意味的整合へ
画像生成の主流は拡散モデルである。ノイズを段階的に付加する順過程と、その逆過程として画像を復元する生成過程から構成され、DDPMがこの枠組みを整理した。実用的には**潜在拡散(Latent Diffusion Models)**として潜在空間上で計算効率を高め、Stable Diffusionに代表される実装が普及した。
テキスト条件付き画像生成では、CLIPのように言語と画像を同一表現空間に整列させたモデルが、テキストプロンプトから視覚出力へのブリッジ役を担う。「言語記号→潜在表現の反復更新→画像」というこの過程は、異種記号体系の翻訳を高度に実現している。
ロボット統合:言語記号を身体行為へ接続する
SayCan・RT-2・PaLM-Eといったロボット統合システムは、言語モデルの生成能力をセンサモーター系へと接続する試みだ。SayCanはLLMが高次行為候補を自然言語で提案し、スキルに付随する価値関数が「実行可能性」を評価して行為列を選択する。RT-2はWebスケールの視覚言語事前学習とロボットデータを統合し、観測から行為への汎化を実現するVLA(Vision-Language-Action)モデルを示した。
バイオセミオティクス的比較分析——三条件から見たAIの意味生成
Peirce三項関係のAIへの写像
LLMの出力をPeirceの枠組みに当てはめると、次のように対応づけられる。
- 記号(representamen):生成されたテキスト・画像・行為列
- 対象(object):入力が参照する世界状態・概念(ただし多くは訓練データ分布に内在化された「代理対象」)
- 解釈項(interpretant):次トークン分布の変化(内部)または人間ユーザの理解・行為(外部)
ここで重要なのは、AIの「解釈項」を内部状態に限定すると、意味は確率的整合性として定義できる一方、Uexküll的な行為—感覚の循環や生物学的規範に結びつかない可能性が高いという点だ。
類似点:反復可能な解釈手続きと準‐記号連鎖
AIの記号生成は、入力に対して内部状態を更新し次の記号を出力するという点で、記号連鎖(sign-to-sign)を機械的に実現する。Transformerは文脈に整合する記号を逐次生成し、拡散モデルはノイズから意味的整合をもつ像を反復復元する。これらは「意味を担う表象を復元する手続き」として、バイオセミオティクスが重視する解釈を工学的に模倣していると言える。
相違点1:身体性(Embodiment)の欠如
Uexküllの環世界は、感覚器・運動器の制約と機能環の閉路が意味世界を構成するという立場であり、「記号」は知覚—行為の循環に埋め込まれる。非身体的なLLMはこの循環を持たず、意味は主に言語内整合と外部評価に依存する。文字通りの「手も目も持たない」システムが生成する記号は、身体的制約による意味の絞り込みを経ていない。
相違点2:規範性(Normativity)の源泉
生物の解釈は、摂食・回避・繁殖・恒常性など、「生にとって」成否が差し迫る規範に結びついている。これに対しLLMのRLHFは「人間が望む応答」という外部から注入された規範を報酬として用いる。その規範はモデルの自己維持から導かれたものではなく、社会的評価の代理である。
相違点3:自己維持(Autopoiesis)との距離
HumbertMaturanaとFrancisco Varelaのオートポイエーシス理論は、生命を自己産出・自己境界化する組織として捉え、認知を生命の構成と不可分に扱う。バイオセミオティクスはこの系譜と交差しながら、記号過程を「生きたシステムの作動」として措定する。身体・代謝・境界を持たないAIは、意味が「外部から付与されたもの(derived meaning)」に留まるという批判を招きやすい。この問題はJohn Searleの中国語の部屋論法やStevan Harnadのシンボル・グラウンディング問題とも共鳴する。
ロボット統合:機能環への近接と残る課題
SayCan型システムは「目と手」を持ち、知覚(センサ入力)と行為(エフェクタ)を通じて環境を変え、その結果として次の知覚が変化する。これはUexküllの機能環により近い構造を実現する。ただしバイオセミオティクス的に決定的なのは「循環があるか」だけでなく、その循環が自己維持の規範に結びついているかという点だ。現在のロボット統合は依然として外部設計の報酬(タスク成功・人間指示)を規範源泉とする場合が多い。
| 観点 | 対話LLM | 画像生成(拡散) | ロボット統合 |
|---|---|---|---|
| 機能環の閉鎖度 | 低い | 低い | 中〜高 |
| 規範性の源泉 | 外部(RLHF) | 外部(学習・評価) | 外部+環境制約 |
| 対象への接地 | 限定的 | 限定的 | 相対的に高い |
| 生物的意味生成との距離 | 大 | 大 | 相対的に小 |
理論的含意——AI設計と倫理への示唆
設計思想への影響:システム全体で「意味の所在」を問う
バイオセミオティクスの観点から導かれる第一の含意は、モデル単体の表現力ではなく、システム全体の設計が焦点化されるという点だ。具体的には、(a) 環境との閉ループ、(b) 規範の由来、(c) 境界条件(何が自己で何が外部か)を含むシステム設計が問われる。コード二重性の観点からは、AIの記号生成は「統計的コード(モデル重み)」と「社会的コード(言語慣習・評価規範)」の二層にまたがっており、RLHFは後者を工学的に注入する手段だが、それが「生命に内在する規範」でないことを自覚的に扱う必要がある。
倫理的課題:生成記号が誘発する「解釈項」を設計対象に
LLMの生成記号は自然言語という強力な媒介で提示されるため、「意味があるように見える」こと自体が社会的効果——説得・誤情報・権威付与——を持ちうる。倫理的課題は「モデルの内部に意味があるか」だけでなく、「生成記号が社会的にどのような解釈項(行為・信念)を誘発するか」を設計・評価対象に含める必要がある。ロボット統合が進むほど、記号生成は言語行為から物理行為へ拡張され、誤解釈が物理的危害へ直結し得るリスクも高まる。
実験的検証への道筋
バイオセミオティクスの「研究質問」型アプローチをふまえると、AIの意味生成を検証する実験は少なくとも三層で設計できる可能性がある。
環境接地テストでは、同一の言語記号が環境の差異(センサ制約・アフォーダンス)に応じて異なる行為へ分岐し、その結果フィードバックで記号使用が更新されるかを計測する。規範源泉テストでは、報酬を「人間満足」から「自己維持・資源制約」へ移したとき生成記号がどう変化するかを、能動推論(自由エネルギー原理)との比較で分析する。翻訳誤解釈の分類では、異種モダリティ間の翻訳誤りが「統計的」か「環境制約」か「規範衝突」かを区別し、解釈項の所在を明確化する。
まとめ——「AIは意味を持つか」から「意味はどこにあるか」へ
バイオセミオティクスは、意味生成を記号列の統計的整合ではなく、生きた主体が環境と相互作用する機能環と多層のスキャフォールディングとして捉える。その観点から見ると、現代AI(LLM・拡散モデル)はPeirce的三項関係の形式を強力に実装する高度な記号生成装置でありながら、身体性・規範性・自己維持という生物的意味生成の三条件を全面的には満たしていない。
ロボット統合・能動推論・ツール使用・ニューロシンボリック統合は、記号生成を環境へ接地し機能環の閉鎖度を高める方向にある。したがって今後の重要な問いは「AIが意味を持つか否か」という二分法ではなく、意味のどの成分(解釈項・規範・環世界)がどの構成要素によって担保されるかを、実験可能な設計仮説として提示・検証することにある。
コメント