ノオスフィアはなぜ「測れる概念」になったのか
ノオスフィア(noosphere)はもともと哲学・思想上の概念として語られてきた。しかし近年、人間とAIが密接に協働し、制度やネットワークが認知と意思決定に深く関与するようになったことで、「集合的な知性の状態を定量的に追跡したい」という実務的・学術的要求が高まっている。
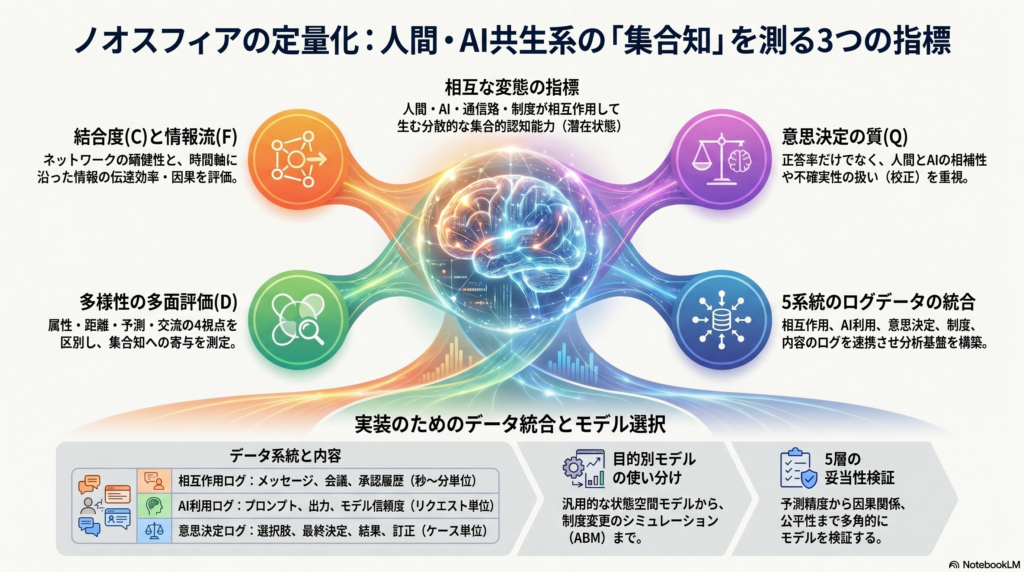
本記事では、ノオスフィアを**「人間・AI・通信路・制度が相互作用して生む分散的な集合的認知能力」**として操作的に定義し直したうえで、これを測定・モデル化するための枠組みを詳しく解説する。中核となるのは4つの観測変数——結合度(C)、情報流(F)、意思決定の質(Q)、多様性(D)——であり、これらを潜在状態変数と組み合わせることで、哲学的な問いを推定可能な統計問題に変換できる。
ノオスフィアの操作的定義と潜在状態モデルの考え方
なぜ「潜在状態」として扱うのか
ノオスフィアをそのまま直接観測しようとすると、対象が広すぎて測定が破綻する。そこで有効なのが、潜在状態(η_t)を置き、それが観測ベクトルを生成するというモデル構造だ。数式で書けば次のようになる。
z_t = H η_t + B x_t + ε_t
η_t = G η_{t-1} + ω_tここで z_t = (C_t, F_t, Q_t, D_t)^T が4つの観測変数、x_t が制度変更・外生ショック・AIモデル更新などの共変量を表す。
このアプローチの利点は、「ノオスフィアが実在するか」という哲学的な問いを脇に置き、「どの潜在状態がどの観測指標にどう現れるか」という推定・予測の問題として扱える点にある。制度変更の前後で観測ベクトルがどう変化したかを追うことで、間接的にノオスフィアの状態変化を推定できる。
設計上の未指定事項に注意する
モデルを構築する前に確認すべき設計事項がある。対象システムの境界(国家なのか、組織なのか、オンラインコミュニティなのか)、分析の時間粒度(秒単位か月単位か)、意思決定の目的関数(正答率を使うのか期待効用か)、制度の符号化単位、介入対象の設定——これらが定まらないと、最適なモデルは一意に決まらない。実装に入る前に明確化しておくことが、後の混乱を防ぐ。
4つの観測変数を正確に定義する
結合度(C):つながりの「質」まで測る
結合度とは、システム内のアクター間の接続状態を表す変数だ。最も単純な指標は有向密度(ρ_t)だが、これだけでは不十分なことが多い。
- 代数的連結度(λ₂):ネットワークが分断されにくいかを測る。値が大きいほど頑健なつながりを持つ。
- 参加係数(P̄_t):複数の関係レイヤ(人間同士・人間-AI・制度接触など)を跨いでいるかを測る多層ネットワーク固有の指標。
- 同類結合度(r_t):似たもの同士でつながっているか、それとも異質な組み合わせが多いかを表す。
実務上は「つながっている」だけでなく、「誰と、どの層で、どれだけ均等に」つながっているかまで捉えることが重要だ。
情報流(F):トポロジだけでは見えない時間順序
ネットワーク構造だけを見ても、実際の情報がどう流れているかは分からない。情報流は時間順序と動力学を込めて計測する必要がある。
代表的な指標として、**時間効率(E_t^temp)**がある。これは、タイムスタンプ付きのイベントデータから、情報がどれだけ速く到達できるかを計算するものだ。また、**リレーショナルイベントモデルのハザード(λ_{ij}(t))**は、連続時間でのメッセージ・参照・承認といったイベントの発生強度をモデル化し、誰が誰にいつ影響を与えたかを推定できる。さらに、**伝達エントロピー(TE)**はXの過去系列がYの将来を予測改善するかどうかを測り、一方向の因果的影響の有無を判断する手がかりになる。
注意点として、pairwise な情報指標は多者間の依存関係(polyadic dependency)を取り逃がしやすいため、複数の指標を組み合わせて使うことが推奨される。
意思決定の質(Q):正確さだけでは不十分な理由
意思決定の質を「正答率」だけで測ることには根本的な限界がある。正答率は不確実性を捨て、過信を検出できない。より実態に近い評価のためには以下を組み合わせる必要がある。
- Brierスコア(BS)とログスコア:確率予測の精度を測り、不確実性の扱いを評価する。
- 期待校正誤差(ECE):「70%と言ったとき本当に70%の確率で正しかったか」という校正の良さを測る。
- 後悔(Regret):最適な選択と実際の選択の差分を効用ベースで評価する。
- ヒューマンAI相補性スコア(S_t):人間のみ・AIのみと比較して、人間とAIの協働が実際に上回っているかを直接測る指標。
相補性スコアは特に重要だ。人間とAIを組み合わせれば自動的に良くなるわけではなく、タスク構造・信頼の校正・権限の分担によって成否が分かれる。この指標がなければ「AI導入の効果」を正しく評価できない。
多様性(D):4種類の多様性を混同しない
多様性は一つの数値に圧縮すると重要な情報が失われる。実務では少なくとも以下を区別する必要がある。
- 属性多様性(Shannon entropy H):構成員の職種・バックグラウンドなどカテゴリの分布を測る。
- Rao-Stirling指数(Δ):カテゴリ間の距離(disparityの概念)を込めた多様性。variety・balance・disparityを統合できる。
- 予測多様性(V^pred):個々のエージェントの予測値のばらつきを測り、集合知への寄与を評価する。
- 交流の多様性:属性が多様でも異なる属性を持つ者同士が実際に交流しているかどうかは別問題だ。
多様性と接触の多様性は分けて観測することで、「構成は多様だが分断している」という状態を検出できる。
統合数理モデルの4つの選択肢
動的多層状態空間モデル:汎用性の高い基本形
最初に導入するモデルとして適しているのが、多層ネットワーク上に潜在状態を置く動的多層状態空間モデルだ。各レイヤのエッジ生成に制度ルール(R_t)と外生ショックを組み込み、観測変数との関係を線形状態空間で表現する。
このモデルは、予測・異常検知・欠測補完・要約指数の算出を一つの枠組みで行える点で実務的に強い。内部業務ログ・チャット履歴・AI利用ログ・アウトカム評価データが揃う組織であれば比較的実装しやすい。制約は、潜在状態の意味付けがモデル依存になりやすいことだ。
リレーショナルイベント/SAOM型モデル:ミクロな相互作用を追う
「誰が誰に、いつ、どの制度下で、どの程度影響したか」を細かく追いたい場合は、連続時間イベントモデルが有力だ。メッセージ・承認・AI問い合わせなどをイベントとして扱い、イベント強度を推定する。
信念更新式を組み込むことで、社会的影響とAI助言の取り込みを同時にモデル化できる。高頻度のタイムスタンプ付きログが豊富な場合に適している。
ABM-IAD-階層ベイズモデル:制度変更の反実仮想に強い
「AIの説明義務を強めたら意思決定の質はどう変わるか」「承認権限を分散したら情報流はどう変化するか」といった政策設計の反実仮想を評価したいときは、**エージェントベースモデル(ABM)**に制度分析フレームワーク(IAD)を組み合わせるアプローチが適している。推定には尤度フリー法(ABC、SMCなど)を用いる。設計コストが高い分、制度変更シミュレーションの精度は高い。
時変因果グラフ+ネットワーク干渉モデル:介入効果の評価に特化
政策介入の因果効果を最も明確に評価できるのが時変因果グラフだ。制度変更 do(R_t = r_1) に対する Q_t の期待値変化として介入効果を定義できる。ただし、ネットワーク干渉(ある個人への介入が他者に波及する効果)があると通常の独立性仮定が崩れるため、干渉を前提にした推定設計が必要になる。
実務上はこのモデルを単独で使うのではなく、動的状態空間モデルの上に因果オーバーレイとして重ねる形が現実的だ。
実装ロードマップ:5系統データの統合と検証の5層
必要なデータの種類
実装には次の5系統データを整備するのが最短経路だ。
| データ束 | 中身の例 | 粒度の目安 |
|---|---|---|
| 相互作用ログ | メッセージ・会議・承認・編集 | 秒〜分 |
| AI利用ログ | プロンプト・出力・信頼度・モデル版 | リクエスト単位 |
| 意思決定ログ | 候補・最終決定・結果・誤り訂正 | ケース単位 |
| 制度ログ | 権限・承認経路・ポリシー改定 | 日〜週 |
| 内容表現 | テキスト埋め込み・距離行列 | 文書・発話単位 |
特に AI 利用ログと意思決定ログの連携が重要だ。「誰が、いつ、どのAI出力を、どんな根拠で採用・却下したか」を監査可能にしておかないと、Q_t の変化が「AI性能の問題」なのか「組織フローの問題」なのかを識別できない。
検証は5層で行う
モデルの妥当性は「データへの当てはまり」だけでは不十分だ。
- 測定妥当性:伝達エントロピーと到達効率の相関確認、代数的連結度と分断事象の対応など、指標間の収束・弁別妥当性をチェックする。
- パラメータ同定:既知パラメータで人工データを生成し、推定器が元の値を回復できるかを確認する(parameter recovery)。
- 予測妥当性:rolling-origin backtestで次期 Q_{t+1} の予測精度を評価する。
- 因果妥当性:AI UI 更新やルール変更を自然実験として扱い、差分の差分法や干渉対応推定で因果効果を評価する。
- 公平性・制度妥当性:人間がAI出力を覆した頻度・理由の記録、被影響者分析、異議申立て率の追跡を行う。
まとめ:ノオスフィアの定量化は「単一方程式」ではなく「観測系の設計」
ノオスフィアの定量的モデル化は可能だ。ただし、それは「絶対的なノオスフィア方程式」を一つ与えることを意味しない。重要なのは次の3点だ。
第一に、結合度と情報流を分けること。 つながっていても情報は流れないし、ハブが存在しても実際の流れがそこを通るとは限らない。構造と動力学は別の観測で捉える必要がある。
第二に、意思決定の質を「正確さ」だけで定義しないこと。 校正・効用・相補性・説明責任まで含めることで、AI活用の実態が初めて評価できる。
第三に、多様性を単一指数に潰しすぎないこと。 属性多様性・意味的多様性・予測多様性・交流多様性は別物であり、それぞれが異なる集合知メカニズムに作用する。
実装上の推奨は、動的多層状態空間モデルで観測系を固定→イベントモデルで相互作用機構を分析→ABMで反実仮想→因果グラフで政策効果推定という段階的なアプローチだ。対象境界・時間粒度・目的関数を最初に明確化することが、モデル選択の実質的な出発点となる。
コメント