はじめに:多段推論でエラーが連鎖するのはなぜか
大規模言語モデル(LLM)が複雑な問いに答えるとき、複数の推論ステップを積み重ねる「マルチホップ推論」が不可欠です。しかしこのアプローチには重大な弱点があります。それが干渉伝播——ある推論ステップで生じたエラーやノイズが、後続のステップに連鎖的に影響を及ぼす現象です。
Chain-of-Thought(CoT)プロンプティングやRAG(Retrieval-Augmented Generation)を活用した高度な推論パイプラインでも、この問題から逃れることはできません。一度の誤りが全ステップを汚染する可能性があり、研究者の間では「ステップ1で間違えるとステップ2以降すべてが誤る」と指摘されることもあります。
本記事では、干渉伝播のメカニズム・定量化指標・介入実験・因果解析の手法を体系的に整理し、この課題に取り組む研究計画の全体像を解説します。
マルチホップ推論と干渉伝播の基礎知識
マルチホップ推論とは何か
マルチホップ推論とは、単一の事実から直接答えが得られない問いに対し、複数の中間ステップを経て結論に至る推論手法です。たとえば「ある人物が生まれた国の首都はどこか」という問いに答えるためには、①その人物の出身国を特定し、②その国の首都を検索するという、最低2ステップの推論が必要になります。
HotpotQA・2WikiMultiHopQA・MuSiQueといったベンチマークデータセットでは、こうした多段推論の精度が問われます。LLMにおいてはCoTプロンプティングが有効であることが示されており、特に大規模モデル(おおよそ1000億パラメータ以上のクラス)での効果が報告されています。また、外部知識グラフを活用するGraphRAG系の手法も精度向上に寄与しています。
干渉伝播(Interference Propagation)の概念
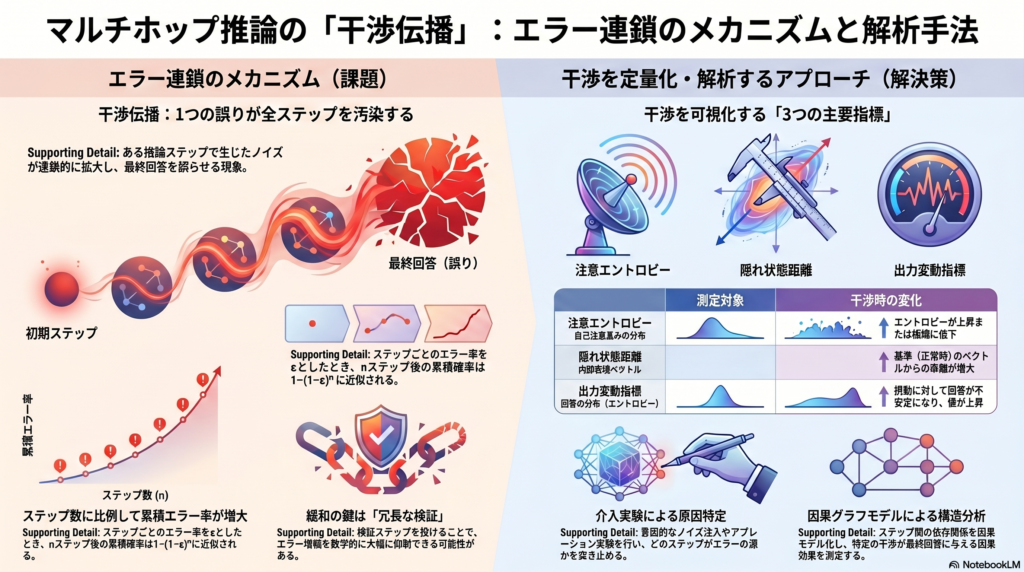
干渉伝播とは、推論チェーン内に挿入されたエラーやノイズが次のステップに影響し、連鎖的に拡大していく現象を指します。理論的には、ステップごとのエラー率を ε とすると、n ステップ後の累積エラー確率は 1−(1−ε)n に近似されます。つまりステップ数が増えるほど、最終的な誤り確率が高まる傾向があります。
一方で、冗長な検証(Redundancy)を導入した場合はエラー確率が O(nk+1εk+1) 程度に抑えられるという理論結果もあり、設計次第でエラー増幅を緩和できる可能性があることも示されています。
干渉を定量化する主要指標の比較
干渉伝播を研究するためには、各ステップでの干渉度を数値化する指標が必要です。以下では、代表的な指標とその特徴を整理します。
出力変動指標(Output Fluctuation)
同一の問題に対してプロンプトを微妙に変化させたり、摂動を加えたりしたときの出力分布のエントロピーを正規化した指標です。値が大きいほど、モデルの出力が不安定であり、干渉に敏感であることを示します。異なるプロンプト間での回答ばらつきを定量的に捉えることができるため、堅牢性評価に広く使われます。
注意エントロピー(Attention Entropy)
Transformerの自己注意機構における重み分布のエントロピーを計算します。注意が一部のトークンに集中している(低エントロピー)ほど局所的な依存性が強く、逆に広く分散している(高エントロピー)ほど情報が希薄化する可能性があります。干渉が進むと注意分布が乱れることが想定され、エラー伝播の代理指標として有効です。
隠れ状態距離(Hidden State Distance)
干渉なしの基準状態との隠れ層ベクトルを比較し、L2ノルムやコサイン距離で乖離度を計測します。距離が大きいほど、内部表現が基準から逸脱しており、外乱の影響が強く表れていることを示します。ステップごとにこの値を追跡することで、どのステップで干渉が急増するかを可視化できます。
干渉効果指標(Interference Effect)
RAGの文脈で用いられる概念で、複数の文書の組み合わせによる有用性の非線形変化を定量化するものです。ドキュメント di,dj をセット S に追加したときの有用性変化を、単独追加時の合算と比較します。これをマルチホップ推論に応用すると、「中間ステップ同士の負の相互作用」として干渉を評価できます。
相互情報量(Mutual Information)
各ステップの入力・出力間、または隠れ状態間の相互情報量を計算します。干渉が発生すると情報流通が乱れ、相互情報量が低下したり予測パターンが崩れたりすることが理論的に予想されます。計算コストが高いため実用時は近似手法を使うことが多いですが、理論的な根拠として重要な指標です。
干渉増幅・減衰に関わる理論的メカニズム
なぜ干渉が増幅したり、場合によっては減衰したりするのか。考えられるメカニズムを整理します。
埋め込みノルムと摂動耐性の関係
Chain-of-Thoughtの頑健性解析では、入力埋め込みのノルムが大きいほど摂動(外部ノイズ)への耐性が低くなるという理論結果が報告されています。埋め込みベクトルの大きさは、情報の「感度」に対応する可能性があり、ノルムが過大になると些細なノイズでも表現が大きく変化してしまう恐れがあります。
注意重みの集中・分散と情報伝達
Transformerの注意重みが一局集中している場合、特定トークンへの依存度が高まります。これは局所的なエラーがそのままボトルネックになりやすい状況を生み出します。一方、注意が過度に分散した高エントロピー状態では、誤情報が広範囲のトークンに波及し、干渉が拡大しやすくなる可能性があります。深層Transformerでは注意重みのエントロピー崩壊が学習困難の原因になるとされており、この観点は推論時の干渉解析にも活用できます。
情報圧縮・ボトルネック効果
ネットワーク内部で情報が低次元空間に圧縮されるとき、必要な情報とノイズの混合比が変化します。埋め込み空間が広く、メモリ容量が十分あれば多様な情報を保持でき、干渉の影響が希釈されると考えられます。反対に、情報が過度に圧縮されると細かな差異が失われ、ノイズと有益な信号の区別が困難になる可能性があります。
自己一貫性と冗長検証による減衰効果
Self-Consistencyなどの手法では、複数回の推論結果を集約することでエラーを相殺し、干渉の影響を減衰させることが可能です。冗長な検証ステップを設けると理論上の誤り確率が大幅に下がるとされており、干渉減衰のメカニズムとして重要な視点を提供します。
実験設計:干渉伝播を測定・検証するアプローチ
使用モデルとデータセットの選定
干渉伝播の研究には、内部状態にアクセスできるオープンウェイトモデル(Llama-2やQwenなど)と、精度の高いクローズドモデル(GPT-4など)を組み合わせることが考えられます。データセットはマルチホップQA系としてHotpotQA・2WikiMultiHopQA・MuSiQueが有力な候補であり、数学的推論系であればGSM8KやMATHも適しています。
介入実験の設計
干渉の因果的影響を検証するには、以下のような介入手法が有効です。
アブレーション実験では、特定ステップの出力を固定または削除し、後続ステップへの影響を評価します。たとえばステップ2の回答を意図的に誤った値に置き換え、ステップ3以降の正答率がどれだけ低下するかを計測します。
ノイズ注入実験では、入力テキストや中間ステップのトークン列に無関連な情報を挿入し、後続の回答と注意分布の変動を観察します。挿入位置や情報の種類(矛盾情報・無関係情報など)を変えることで、干渉の発生源を特定できます。
**因果介入(Doオペレータ)**では、Transformerの特定ニューロンや注意重みを直接操作し、出力の変化を観察します。これは構造的因果モデル(SCM)の枠組みで解釈でき、モデル内部における干渉の因果的役割を明らかにする手法です。
**差分法(Difference-in-Differences)**では、干渉を入れたグループと入れなかったグループを比較し、ステップごとの変化量差分から純粋な干渉効果を推定します。
ステップごとの計測方法
推論を逐次ステップで記録し、各ステップ終了時に上記の指標を計測します。CoTプロンプティングの場合は中間ステップ生成後の注意分布と隠れ状態を取得し、GraphRAG系ではグラフ更新ごとのノード密度や連結性を評価します。基準条件(干渉なし)と干渉条件を複数回実行し、ログを比較することで差分が明確になります。
因果グラフモデルによる干渉の構造分析
ステップ間の因果チェーンをモデル化する
ステップ i での干渉度を Ii、出力品質を Yi としたとき、推論チェーンは「Ii→Yi→Ii+1」のような因果グラフで表現できます。この構造により、ある時点での干渉介入(do(I1))が最終出力 Yn に与える因果効果を定量化することが可能になります。
インストゥルメンタル変数(IV)の活用
干渉を直接操作できない場面では、間接的に干渉度に影響を与える外生変数を利用するIV法が有効です。たとえば、プロンプトの文体や形式を変えることでステップごとの信頼度が変化するなら、それをIVとして利用できます。バックドア基準やフロントドア基準を適用することで、交絡因子を排除した因果効果の推定が可能になります。
可視化で干渉の「流れ」を掴む
注意重みヒートマップ
各推論ステップの自己注意行列を可視化し、干渉挿入前後でパターンがどう変わるかを観察します。注意のスパース化や分散の変化は、情報フローの乱れを直感的に示します。
干渉指標の時系列プロット
出力変動度・注意エントロピー・隠れ状態距離などの指標をステップごとに折れ線グラフとして描きます。特定のステップで値が急増する場合、そこが干渉の「増幅点」である可能性を示唆します。
知識グラフの進化図
GraphRAG系のアプローチでは、各ステップで構築される知識グラフのトポロジー(ノード数・密度・クラスター数)をステップごとに並べて可視化します。グラフの断片化が進むほど、干渉による情報ロスが大きい可能性があります。
まとめ:干渉伝播研究が切り拓くLLM推論の信頼性向上
本記事では、マルチホップ推論における干渉伝播の基礎概念から、定量化指標・実験設計・理論メカニズム・因果解析手法・可視化アプローチまでを体系的に解説しました。
重要なポイントは以下の通りです。
- ステップ数の増加に伴い累積エラー確率は増大するが、冗長検証や自己一貫性により減衰できる可能性がある
- 埋め込みノルムの大きさや注意エントロピーの高さが干渉増幅に関与すると理論的に示唆されている
- アブレーション・ノイズ注入・因果介入などの実験設計を組み合わせることで、干渉の発生源を特定できる
- 因果グラフモデルやIV法を用いることで、相関ではなく因果的なメカニズムの解明が期待できる
この研究の知見は、エラー耐性の高い推論パイプラインの設計や、モデル内部の改良指針として活用できると考えられます。
コメント