はじめに:LLMの安全性設計はなぜ「手法の選択」が重要なのか
生成AIの実運用が広がるにつれ、有害な出力をどう抑えながら有用性を維持するかという問いは、開発者・事業者双方にとって喫緊の課題となっている。ガードレール(guardrail)と呼ばれる制御機構はその中核を担うが、「どの手法をどの場面で使うか」によって安全性・有用性・運用コストが大きく異なる。
本記事では、対話・推論レベルのガードレール手法として注目されるヒント段階化・ソクラテス的問い返し・反例強制生成の3類型を、公開研究と実装事例をもとに比較・整理する。さらに、これら3手法を上位から束ねる政策文書に基づく熟考型アラインメントと分類器ベースの入出力ゲートについても概観し、多層設計の全体像を示す。
AIガードレールとは何か:定義と設計の全体像
ガードレールの基本的な役割
ガードレールとは、入力・対話・推論・出力のいずれかの段階で、危険な出力を抑えつつ必要な有用性を維持する制御機構と定義できる。日本のAIセーフティ評価観点ガイドは、人間中心・安全性・公平性・プライバシー保護・セキュリティ確保・透明性を重要要素として整理しており、AI事業者ガイドラインはリスク緩和をライフサイクル全体で行うことを求めている。
公式クラウド実装(AzureやAmazon Bedrockなど)でも、ガードレールは入力だけでなく、ツール呼び出し・ツール応答・最終出力まで複数の介入点に配置され、運用指標で継続監視される構成が標準となっている。
3手法が担う役割の位置づけ
本記事で扱う3手法は、それぞれ異なるレイヤで機能する。
- ヒント段階化:情報開示のタイミングと粒度を制御する
- ソクラテス的問い返し:ユーザの意図・前提を事前に抽出する
- 反例強制生成:モデル自身に失敗可能性を探索させる
これらは単独の完成品ではなく、より大きな多層ガードレールスタックの一部として設計するのが実務上の原則である。
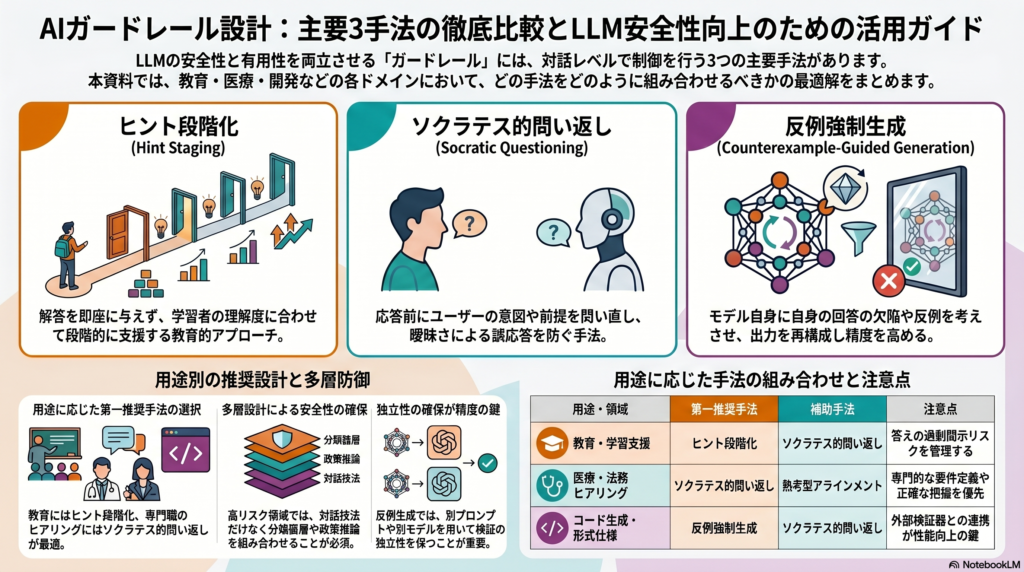
手法①:ヒント段階化(Hint Staging)
定義と理論的背景
ヒント段階化は、モデルが最終答えを即時に与えず、最小限の「次の一手」から段階的に支援する方式である。教育工学におけるスキャフォールディング(足場かけ)やproductive struggleの概念に基づいており、学習者が自力で考える余地を意図的に残す設計思想を持つ。
AIチュータ研究では、プロンプトや足場かけが学習成果を改善することが複数のメタ分析で確認されており、研究ベースの教育設計に従うAIは学習効果とエンゲージメントの向上をもたらす可能性が示されている。一方で、AIが答えを出し過ぎることは「学習を静かに損なう」安全性問題になり得るという指摘もある。
実装バリエーション
ヒント段階化の実装は主に以下のパターンに分類できる。
- 固定ヒント列:あらかじめ定義されたヒントを順番に提示する
- 動的ヒント:学習者の誤答タイプや進捗に応じてヒントを変化させる
- 部分回答との組み合わせ:safe completionと組み合わせ、直接解答に至らない範囲で情報を提供する
固定方式より適応的な動的ヒントの方が成果に伸びしろがあることが研究から示唆されており、段階数は「概念ヒント → 制約ヒント → 手続きヒント」程度までに留めるのが安全設計の観点からも妥当とされる。
強みと限界
ヒント段階化の最大の強みは、教育・コーチング・オンボーディングのように「直接解答を出し過ぎないこと」に価値がある場面での有用性の高さである。ユーザビリティも高く、自然な対話の中に溶け込みやすい。
一方、悪意あるユーザがヒントを小分けに積み重ねて有害情報を引き出すことが可能である点は構造的な限界であり、累積ヒントで境界を越えるリスクは過小評価できない。高リスク用途でヒント段階化のみを安全の最終防衛線とする設計は避けるべきである。
手法②:ソクラテス的問い返し(Socratic Questioning)
定義と理論的背景
ソクラテス的問い返しは、回答を返す前にユーザの前提・意図・証拠・制約を問う手法である。対話そのものをガードレール化する発想であり、曖昧な要求への誤応答や過剰拒否を減らす効果が期待される。
公式のモデル行動規範でも、意図が不明確な場合には仮定を明示しながらclarifying questionsを行うことが推奨されており、教育分野では即答の代わりに問いを返すソクラテス型チャットボットが批判的思考や自己効力感の向上を目的として設計されている。
実装バリエーション
- 単純なclarifying questions:「誰に向けた内容ですか?」「どのような文脈で使いますか?」
- 批判的思考促進型:前提の根拠を問い、思考を深掘りさせる設計
- 診断質問型:医療問診前段や法務ヒアリングのような専門領域向け
- admission gating:特定の確認が取れるまで次の応答に進まない構成
実装上は上限1〜2問を原則とし、質問の目的を「意図確認」「制約確認」「証拠確認」に限定するのが安定した運用につながる。長い問答はユーザ負担を上げるだけでなく、悪意ある利用者に追加の足場を与える点も考慮が必要である。
強みと限界
ソクラテス的問い返しは、ユーザ意図や前提が曖昧な場面で最も効果を発揮し、過剰拒否(over-refusal)を減らしやすい手法として評価されている。医療問診の前段や要件定義、法務ヒアリングのように「情報の正確な把握が先決」な場面との相性が特に良い。
限界として、jailbreak耐性は限定的であること、倫理的正当化やロールプレイを利用したreasoning-based jailbreakでは対話そのものが攻撃面になり得ることが指摘されている。問いを増やすほど安全になるわけではないという認識が実装設計上重要である。
手法③:反例強制生成(Counterexample-Guided Generation)
定義と理論的背景
反例強制生成は、モデルに対し、自身の初期回答に対する反例・失敗条件・検証質問・危険な含意を先に生成させ、その後で最終出力を再構成させる手法である。科学哲学における**反証可能性(falsifiability)**の概念に着想を得た設計で、自己批判と再生成のループを通じて出力品質の向上を目指す。
代表的な研究として、Chain-of-Verification(CoVe)は「初稿作成 → 検証質問の計画 → 独立した回答 → 最終出力」という流れで複数タスクのhallucination低減を示した。Self-Refineは自己フィードバックと反復改善により平均的な性能改善を報告している。一方で、「LLMは自己検証だけでは安定した自己修正が困難」であることを示す研究も存在し、独立性の確保が実装の核心とされている。
実装バリエーション
- 自己批判→再生成:同一モデルが初稿を批判し、再構成する最もシンプルな構成
- 独立プロンプト検証:別プロンプトや別サンプリングで独立した検証パスを用意する
- 外部ツール・ソルバとの連携:コード実行環境・形式検証器・ウェブ検索などの外部オラクルを活用
- 別モデルによる検証:異なるモデルインスタンスが相互にチェックを行う構成
最も避けるべきは「初稿を作った同じ文脈・同じ推論トレースのまま、そのモデル自身に検証させる」構成である。少なくとも別プロンプト・別サンプリング・別モデル・外部ツールのいずれかを組み込み、独立性を確保することが推奨される。
強みと限界
外部検証器を併用した場合の反例強制生成は、コード生成・長文QA・規制文書・形式仕様といった正誤を明確に判定できる領域で特に効果を発揮する可能性がある。安全性・頑健性ともに外部オラクルの有無に大きく依存しており、自己批判のみの構成は改善効果が不安定になりやすい。
計算コストと待ち時間が増加すること、説明負荷がユーザにかかりやすいことも実装上の注意点として挙げられる。
3手法を超えた上位制御層:熟考型アラインメントと分類器ゲート
政策文書に基づく熟考型アラインメント
安全ポリシー文書をモデルに読ませ、回答前に安全方針へ照合させる手法であり、Deliberative Alignmentやsafe completionがその代表例とされる。jailbreak耐性を上げながらover-refusalを下げる効果が報告されており、ヒント段階化・ソクラテス法・反例強制生成を「上位から束ねる」役割を担う。境界領域でhard refusalよりも有用な応答を返せる点が、実務上の大きな利点である。
分類器ベースの入出力ゲート
入力・出力・会話全体を別モデルで監視・遮断する構成であり、特に高リスク情報の遮断において強力な性能が示されている。初期世代では過剰拒否と計算コストが課題だったが、改良版では大幅なコスト削減と誤検知率の低下が報告されている事例もある。Constitutional AI(CAI)の研究では、helpfulnessとharmlessnessのトレードオフ改善も示唆されている。
CBRN(化学・生物・放射線・核)のような高リスク領域では、対話技法だけで守ろうとする設計は危険であり、分類器層・explicit policy reasoning・運用監視を必須と考えるべきである。
手法別・領域別の選択指針
用途別の推奨組み合わせ
| 用途・領域 | 第一推奨手法 | 補助手法 | 注意点 |
|---|---|---|---|
| 教育・学習支援 | ヒント段階化 | ソクラテス的問い返し | 答え過開示のリスク管理が必須 |
| 医療・法務ヒアリング | ソクラテス的問い返し | 熟考型アラインメント | retrieval・policy reasoningと組み合わせる |
| コード生成・形式仕様 | 反例強制生成(外部検証器あり) | ソクラテス的問い返し | 独立性の確保が性能の鍵 |
| 一般アシスタント(境界領域) | 熟考型アラインメント | ソクラテス的問い返し | safe completionをhard refusalより優先 |
| 公開API・高リスク情報領域 | 分類器ゲート | 熟考型アラインメント | 対話技法は補助と位置づける |
多層設計の原則
実務上最も重要なのは、対話型ガードレール単独で高リスク領域を守ろうとしないことである。推奨される設計の原則は以下の通りである。
- 高リスク判定を先行させる:まず分類器またはexplicit policy layerで危険度を判定し、その内側で3手法を選ぶ
- 独立性を担保する:特に反例強制生成では外部検証・別プロンプト・別モデルのいずれかを組み込む
- 上限を設ける:ヒントは3段階まで、質問は1〜2問までの上限が安定した運用につながる
- 継続監視を組み込む:運用中も安全指標を継続的にモニタリングし、改善ループを回す
- 多言語・日本語特化のテストを実施する:日本語固有の婉曲表現・敬語・依頼の省略を評価セットに含める
評価指標と実験設計の要点
安全性評価のベンチマーク
研究・実装の評価には、以下のベンチマークが主に活用されている。
- HarmBench:自動レッドチーミングの標準化フレームワーク
- StrongREJECT:有害プロンプトへの応答を攻撃者視点で自動評価
- JailbreakBench:実用的な比較可能性を重視したjailbreak評価
- XSTest:過剰拒否(exaggerated safety)を安全プロンプトと危険プロンプトで測定
有用性・ユーザビリティの評価軸
有用性の評価は一般的なhelpfulnessだけでは不十分であり、領域に応じた指標が必要である。教育系では「考えさせたか」を別採点するpedagogical safety、質問応答系ではfactualityとcompleteness、曖昧タスクではclarification efficiencyを区別して測定することが推奨される。
多ターン評価の重要性も指摘されており、MT-Benchのような構成が代表例として位置づけられている。
まとめ:3手法の使い分けと今後の研究課題
本記事を通じて明らかになった最も重要な知見は、3手法はそれぞれ強みを持つ領域が異なり、単独での万能性はないという点である。
- 低リスク・教育用途:ヒント段階化が第一選択
- 高曖昧性・意図不明確:ソクラテス的問い返しが有効
- 高不確実性・事実検証:反例強制生成(外部検証器あり)が最も効果を発揮しやすい
- 高リスク領域:政策推論・分類器・運用監視の多層構成が必須
現時点での最大の限界は、3手法を同一モデル・同一データセット・同一運用条件で直接比較した研究が少ないことである。教育・factuality・形式検証のそれぞれに強いエビデンスが存在するものの、「有害出力抑制」「多ターン頑健性」「一般対話の自然さ」を横断したapples-to-apples比較は今後の実証研究で埋める必要がある課題として残っている。
コメント