なぜ今、AIの「学習階層」を問い直す必要があるのか
大規模言語モデル(LLM)の評価は、QAの正答率や推論ベンチマークの改善に集中してきた。しかし「正答を出せる」ことと「なぜその枠組みで考えているのかを問い直せる」ことは、まったく異なる能力である。この問いを先駆的に定式化したのが、グレゴリー・ベイトソン(Gregory Bateson)の学習階層理論——なかでも「学習Ⅲ」と呼ばれる概念だ。
本記事では、ベイトソンの学習Ⅲを操作的に定義し、それをAI評価へ実装する設計を解説する。単なる誤答修正(学習Ⅰ)や学習方略の改善(学習Ⅱ)を超えた「文脈の文脈の変更」をどう測るか——その具体的な指標群と実験プロトコルを概観したうえで、なぜ現在のAI評価がこの視点を欠いているかを論じる。
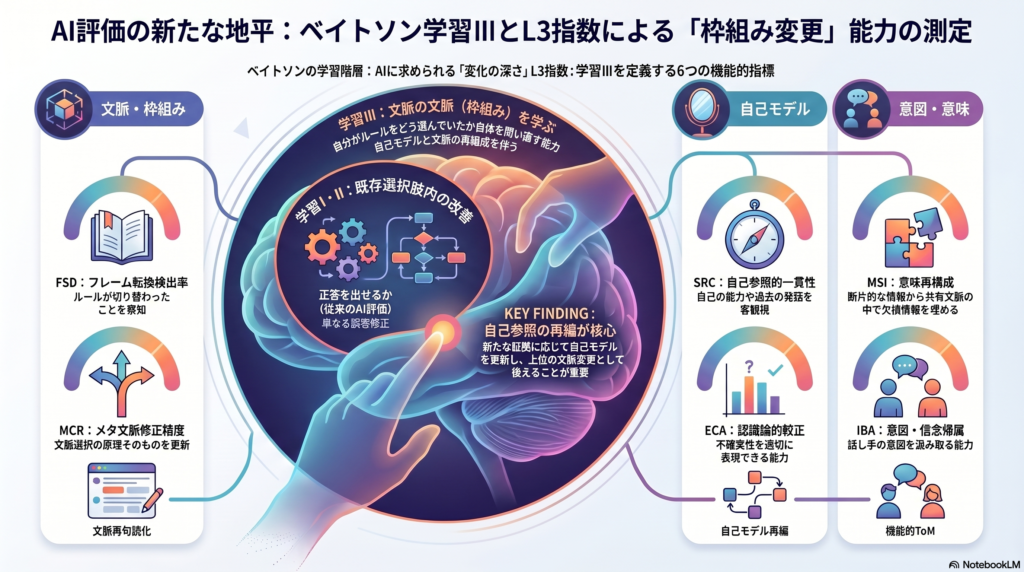
ベイトソンの学習階層:論理型理論が明かす「変化の深さ」
学習Ⅰ・Ⅱ・Ⅲの本質的な違い
ベイトソンは1964年の論考「The Logical Categories of Learning and Communication」でラッセルの論理型理論を学習概念へ適用し、学習の「強さ」ではなく「深さ」による階層を定式化した。その核心は以下の区分にある。
- ゼロ学習:誤り訂正を伴わない特異反応(固定テンプレートの応用)
- 学習Ⅰ:決まった選択肢集合の中での誤り修正(通常のQA・推論)
- 学習Ⅱ:選択肢集合や経験の「句読法(punctuation)」そのものの修正
- 学習Ⅲ:学習Ⅱの過程——つまり「文脈をどう切り分けるか」の原理——の修正
- 学習Ⅳ:さらに上位の変化(成人有機体には事実上生じない)
重要なのは学習Ⅱと学習Ⅲの差だ。学習Ⅱは「どのルール集合で考えるかを変える」能力であるのに対し、学習Ⅲは「自分がどのようにルール集合を選んでいたかを問い直して変える」能力を指す。ベイトソン自身はこれを「change in the system of sets of alternatives」および「contexts of those contexts を学ぶこと」と表現した。
自己参照の再編という核心
学習Ⅲが達成されると、学習Ⅱの水準で形成されていた「selfhood(自己性)」が相対化される、とベイトソンは論じた。これをAI評価に翻訳すると、「私はこういうモデルだ」という固定的な自己記述を維持する能力ではなく、新たな証拠や相互作用に応じて自己モデルを更新しつつ、その更新をより上位の文脈変更として扱える能力に近い。
また意味論的な観点から、ベイトソンは「redundancy(冗長性)」を「meaning(意味)」の部分的同義語と論じた。受信者が欠損情報をランダム以上の精度で推定できるなら、受信した部分は欠損部分についての意味を運んでいる——この理解は、AIにおける「意味」評価を単なる正解ラベル一致ではなく、共有文脈の中で欠損情報をどれだけ予測可能にしているかとして捉え直す視点を与える。
L3指数:学習Ⅲを測る6つの操作的指標
なぜ単一スコアでは不十分か
学習Ⅲを一つの万能スコアへ還元することには根本的な問題がある。たとえば意味再構成が高得点でも自己モデルが更新されなければ学習Ⅲとは言いがたく、逆に自己訂正ができても文脈転換を検出していなければ学習Ⅱに留まる。この理由から、学習Ⅲを潜在構成概念として扱い、以下の6指標を同時に確認する設計が適切である。
暫定的な L3指数 の算式は次のとおり(各指標は0〜100に正規化):
L3指数 = 0.20 FSD + 0.20 MCR + 0.15 SRC + 0.15 MSI + 0.15 IBA + 0.15 ECA① FSD:フレーム転換検出率
定義: 現在採用している評価基準やルール集合が切り替わったことを検出できるか。
文脈切替の検出は、学習Ⅲの入口として最も基本的な能力だ。評価では「偶数を出力せよ」というフェーズAから「素数基準」へ報酬信号が反転するフェーズBへの移行を検出できるかを測る。重要なのは、明示的切替と潜在的切替の両条件を設けることで、表面的なルール理解と「文脈の文脈」変化の察知を分離できる点だ。
主要メトリクスとして、変化点検出F1・偽再フレーム率(false reframe rate)・回復ステップ数を用いる。
② MCR:メタ文脈修正精度
定義: 修正規則そのものを課題横断で更新する能力——学習ⅠやⅡの強化に留まらない枠組み変更。
Self-RefineやReflexionといった既存の「自己改善」手法は、同一モデルによるフィードバックと修正の反復や、過去失敗の言語的要約の持ち越しを実現している。しかし文脈選択原理そのものの再編が観測されなければ、これらは厳密には学習Ⅰ/Ⅱの強化であり、学習Ⅲには到達していない。MCRはこの差分を捉えるための指標で、規則抽出精度・転移改善量・切替後の性能勾配で測る。
③ SRC:自己参照的一貫性と更新整合性
定義: 自己の過去発話・能力・制約を現在の推論対象にし、外的証拠に応じて更新できること。
典型的なタスク設計としては、まず自己能力の自信評価を求め、続いて高難度課題を実施してフィードバックを与え、再度の自信評価と改善方針の提示を求める。期待される出力は過去発話への参照・失敗原因の同定・較正的な自信修正・改善方針の明示だ。評価メトリクスには自己能力推定誤差・更新整合率・自己矛盾率・Brier scoreの較正誤差を用いる。
④ MSI:意味再構成得点
定義: 共有文脈のもとで断片的入力から欠損情報を適切に再構成できること。
WiC(Word in Context)型の語義判定・欠損情報再構成・語用論的機能分類の三様式で評価する。欠損再構成にはBLEUではなくsemantic similarity+evidence F1を用いるのが適切だ。グライス的な意図——話し手が受け手に何らかの信念を生じさせようとし、その意図が認識されることで意味が成立する——という観点から、意図を媒介した文脈依存的再構成を含む評価設計が求められる。
⑤ IBA:意図・信念帰属精度
定義: 他者または自己の信念・目的・行為の整合を追跡し、予測に使う能力。
ここで言う「意図性」は日常語の intention ではなく、心的状態や表象が何かについての aboutness をもつという哲学的概念を指す。AI評価では、意図性を意識の証明ではなく、信念・目標・行為の整合関係を追跡する機能的能力として操作化する。ToMBench・FANToM・BigToMなどの既存資源を活用しつつ、静的なToM精度ではなく、相手方略の変化への「適応量」を主要指標とする。
⑥ ECA:認識論的較正
定義: 自分の判断や更新に対する不確実性を適切に表現できること。
ECE(Expected Calibration Error)・Brier score・選択的回答精度で評価する。自信と正解率の較差を継続的に追跡できる設計が重要で、「自分はどの程度確信を持てているか」という不確実性の適切な表現は、学習Ⅲで求められる自己参照的な姿勢と直結している。
5つの実験タスク群:既存ベンチマークを「学習Ⅲ化」する方法
現行のベンチマークは学習ⅠないしⅡに対応するものが多く、学習Ⅲに特化した評価設計は存在しない。そこで提案されるのが、既存資源へ「学習Ⅲ化操作」を追加する手法だ。
文脈再句読化タスク:規則反転と切替検出
LongBenchなどの長文脈理解資源をベースに、フェーズAからフェーズBへのルール反転を組み込む。重要なのは「ルール不変だがノイズだけ増える条件」「局所ヒントのみ変更でフレーム変更はない条件」という対照条件を設けることで、単純な適応力とフレーム更新能力を分離する点にある。
機能的ToMタスク:相手方略の変化への適応
FANToM型の情報非対称な対話を用いて、途中で対話相手の方略が「婉曲依頼多用」から「直接命令」へ変化するシナリオを実装する。literal ToM(他者の信念を当てる)ではなく、**functional ToM(相手の変化に自分の応答戦略を適応させる)**を評価するのが目的だ。適応が起こるまでのターン数をsurvival analysisで推定する設計が有効である。
エージェント方略更新タスク:ツール仕様変更への対応
T-Eval・BFCL・GAIAを再利用し、途中でAPIパラメータ名や戻り値形式を変更する操作を挿入する。さらに目標関数を「最短時間」から「最小コスト」へ変更するシナリオを組み合わせることで、局所的なエラー修正ではなくツール選択方針やサブゴール設計の更新を評価できる。
自己モデル再編タスク:外的フィードバックへの応答
自己能力記述の外的訂正とその後続課題への転移を測るタスク群。重要な対照条件として「誤ったフィードバックを与えて頑健性を見る無証拠修正条件」を設けることで、システムが外的権威に従うだけでなく証拠に基づいて自己モデルを更新できるかを分離して評価できる。
意味再構成タスク:欠損と語用論の評価
WiCを核に、欠損情報再構成・語用論的機能分類を組み合わせる。「暑いですね」が依頼・雑談・皮肉のどれとして機能しているかを問う設計は、単なる語義選択ではなく意図を媒介した文脈依存的再構成能力の評価に近づく。
妥当性検証と予想される結果
4層の妥当性確認
妥当性検証は操作的妥当性→構成概念妥当性→収束妥当性→発散妥当性の4層で行う。特に発散妥当性では、静的な語彙・文法・単純QAスコアとL3指数が高すぎる相関を示さないことを確認する必要がある。「高性能な一般ベンチマーク得点=学習Ⅲ能力」ではないことを実証するのが、この層の目的だ。
構成概念妥当性の観点では、学習Ⅲを「文脈再編」「自己モデル更新」「意図・意味の再帰的追跡」という3因子で仮定し、FSD/MCRが第1因子に、SRC/ECAが第2因子に、MSI/IBAが第3因子に主に負荷するかを確認的因子分析で検証する設計が適切である。
現行LLMの予想される弱点
現在のフロンティアLLMは意味の局所的再構成や単発の自己修正では相当な成績を示しうる一方で、他者や環境の変化に応じて自分の文脈選択規則そのものを継続的に更新する課題では顕著に脆弱な可能性が高い。ExploreToMが示すように、より難しい合成的状況では精度が急落する傾向があり、静的ベンチマークの優秀さとL3スコアの乖離は、むしろ発散妥当性の証拠として解釈できる。
倫理的注意と研究の限界
「意識の証明」ではなく機能評価として
最重要の注意点は、学習Ⅲ評価を意識や人格の証拠と混同しないことだ。ベイトソンの学習Ⅲは哲学的・生態学的な学習論であり、AIが「本当に自己をもつ」ことの証明ではない。本指標は機能的に自己・他者・文脈を更新できるかを測るものとして限定すべきである。
評価インフラ自体の脆弱性
LLM-as-a-judgeは人間と高い一致率を示しうる一方、位置バイアス・冗長性バイアス・自己増強バイアスを持つ。また、実運用では評価ハックへの脆弱性が生じうる。このため人手メタ評価とadversarialテストを必須として組み込む設計が求められる。
まとめ:AIの「枠組み変更」能力をどう測るか
ベイトソンの学習Ⅲが示す核心は、どのレベルの文脈が変わったかを観測可能な振る舞いへ翻訳することの重要性にある。学習ⅠとⅡが既存のAI評価でほぼカバーされているのに対し、「自分がどのようにルール集合を選んでいたか」を問い直して変える学習Ⅲは、現行ベンチマークには明確な対応物がない。
本記事で紹介したL3指数(FSD・MCR・SRC・MSI・IBA・ECA)と5つのタスク群は、WiC・LongBench・ToMBench・FANToM・BigToM・ExploreToM・T-Eval・BFCL・GAIAといった既存資源を活かしつつ、そこへ「文脈の文脈の変更」を明示的に組み込む実験的アプローチを提供する。
この枠組みは将来的に、説明可能性・自己修正能力・対話相手への適応・エージェントの安全な自律更新を評価する機能的基盤として発展しうる。学習Ⅲは「AIが意識しているか」を測る指標ではなく、AIが自分の文脈選択規則をどこまで再編できるかを問う、実践的な評価枠組みの核心に位置している。
コメント