AIが変える「意味」の構造——記号論という視点がなぜ今必要なのか
画像生成AI、音声クローン、動画合成——これらマルチモーダルAIの急速な普及は、私たちが日常的に接するコンテンツの「信頼性」を根本から揺さぶっている。写真は本当に現実の痕跡なのか。声は本当に話者の存在を示すのか。そうした問いに、19世紀の哲学者チャールズ・サンダース・パースが築いた記号論が、今あらためて鋭い分析ツールとして機能する。
パースの三項関係——記号(表現体)・対象・解釈項——とアイコン・インデックス・シンボルの分類は、AIが生成するコンテンツがどのように意味を生み、どこで誤認が起きるかを構造的に説明できる枠組みだ。本記事では、技術的メカニズム(埋め込み空間、注意機構、拡散モデル)と制度的文脈(著作権、来歴標準、EU AI Act)を接続しながら、生成AIが記号論的に何を変えているのかを掘り下げる。
パースの三項関係とアイコン・インデックス・シンボルの基礎
三項関係はなぜ「二項」に還元できないのか
パースの記号論の核心は、意味が「記号と対象の一対一の対応表」ではなく、**記号が解釈項を生み、その解釈項が対象への関わり方を規定する連鎖(セミオーシス)**として成立するという点にある。1867年の「On a New List of Categories」で提示されたこの立場は、フェルディナン・ド・ソシュールの二項的言語記号論(記号表現と記号内容の恣意的結合)とは根本的に異なる。
記号が対象を指す仕方には三つの様式がある。
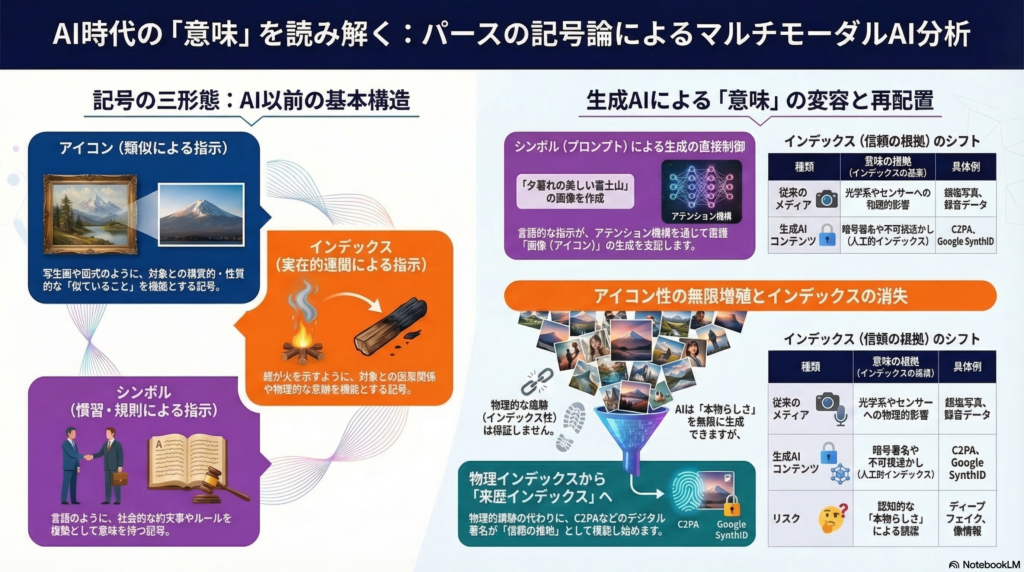
アイコン(Icon) は「類似(resemblance)」による指示だ。対象が実在しなくても、記号の性質だけで指示は成立しうる。絵画や図式がその典型で、描かれた対象との視覚的類似が意味の根拠になる。
インデックス(Index) は「実在的連関(因果・接触・時空的隣接)」による指示だ。パースの定義を借りれば、インデックスは「対象に実際に影響されることによって対象を指す記号」である。煙が火を指示し、足跡が通過者を指示するように、物理的な痕跡関係がその意味の基盤となる。
シンボル(Symbol) は「慣習・規則・習慣(habit/law)」による指示だ。言語の大部分はシンボルであり、「木」という音声・文字列が樹木を指示するのは、解釈共同体の規則性に基づく。
現実のメディアはこれらの混成として現れる。写真は物理インデックス(光学・センサ応答による対象の痕跡)でありながら、視覚的アイコンでもあり、キャプションや文脈によってシンボル的にも機能する。この混成性こそが、生成AIが記号論的に何を崩しているかを理解する鍵になる。
マルチモーダルAIの技術構造——記号論的に重要な四つのメカニズム
共有埋め込みがもたらす「意味の統計空間化」
CLIPに代表される対比学習モデルは、大規模な画像とテキストのペアから、両者を共通の表現空間へ写像する。重要なのは、この空間における「意味」が外界の事物への直接参照ではなく、学習データにおける共起構造(co-occurrence)として表現されるという点だ。
パース的に言えば、対象(Object)が外界の事物から「データ分布の統計的構造」へと移動している。ImageBindはさらにこれを拡張し、画像・テキスト・音声・深度・熱・IMUを単一の埋め込み空間へ整列することで、「画像が他モードを束ねる軸」となる構造を作った。センサーの痕跡(インデックス)すら「画像的表現」へと翻訳されてしまうことになる。
拡散モデルがインデックスの直感を揺さぶる理由
DDPMに始まりLatent Diffusionへと発展した拡散モデルは、ノイズを段階的に除去することで画像を生成する確率過程だ。この過程では、画像は「対象の光学的痕跡」ではなく、「推定過程の確率論的産物」として生まれる。
Stable Diffusionが採用する潜在拡散では、テキストなどの条件付けがクロスアテンション機構を通じて生成の各段階に注入される。これは記号論的に極めて重要な回路だ。**シンボル(言語・プロンプト)→注意機構→アイコン(高忠実な生成画像)**という変換が工学的に一般化されたことを意味するからだ。classifier-free guidanceによって条件付けの強度を「ノブ」として調整できることも、この回路の制御可能性を示している。
視覚言語モデルが「解釈項の自動生成」を担う
Flamingo、BLIP-2、LLaVAといった視覚言語モデル(VLM)は、事前学習済みの視覚エンコーダと大規模言語モデルを接続し、画像入力に対してテキスト応答を生成する。パース的には、これは解釈項(Interpretant)——記号が心的に生み出す効果——をモデルが自動的に生成することを意味する。
特にLLaVAのように「GPT-4が生成した視覚指示データで訓練」されたモデルでは、「どう答えるべきか」という規範的解釈がデータに埋め込まれており、シンボル(規則)が学習を通じて増殖する構造になっている。
Whisper・AudioLMが示す音声インデックスの変質
Whisperは音声を汎用的にテキストへ変換する。この認識過程では、音声が持つ話者性・感情・環境音といったインデックス的要素がテキスト化によって落とされうる。逆にAudioLMは音声を離散トークン列として言語モデル的に生成し、話者性(声の特徴=インデックス)を模倣可能にする。インデックスの「偽造」が体系的に可能になった時代の到来だ。
アイコン・インデックス・シンボルはどう再配置されるか
生成AIが「アイコン性の無限増殖装置」になる構造
拡散モデルの高忠実生成により、画像・音声・映像の視覚的・聴覚的類似性(アイコン性)は爆発的に増幅している。写真らしさ、声らしさ、映像らしさを人工的に生成するコストが劇的に下がった結果、アイコンとしての記号は「低コストで無限増殖する」状況になった。
この増殖は証拠性とは切り離して評価しなければならない。高いアイコン性は、対象との実在的連関(インデックス性)を何ら保証しない。しかし人間の認知は、十分に高いアイコン性に対してインデックス性を自動的に付与してしまう傾向があることが、ディープフェイク検出に関する複数の研究で示唆されている。これが「インデックス誤認」の認知的構造だ。
物理インデックスから「来歴インデックス」へ——C2PAとSynthIDの意義
従来の写真・録音は、光学系やセンサーが対象の物理的影響を受けて生成されるという「物理インデックス」を持っていた。生成AIコンテンツはこの根拠を欠く。そこで社会的な代替として機能しうるのが、C2PA(Coalition for Content Provenance and Authenticity) による暗号署名付き来歴情報や、Googleが開発したSynthIDのような不可視透かしだ。
これらは「このコンテンツがどのような過程で生まれたか」を記録・証明する「人工インデックス」として機能しうる。しかしメタデータがプラットフォーム間で剥がれる問題や、表示UIが追いついていない現実もある。来歴技術が真に機能するためには、標準化・プラットフォーム実装・UI設計・規制という多層の取り組みが必要だ。
シンボルが生成過程を直接制御するパラメータになる
プロンプト、テンプレート、評価基準、安全ポリシー——これらはすべてシンボル(規則・慣習)の体系だが、生成AIにおいてはこれらが生成過程を直接制御するパラメータとして機能する。言語埋め込みがクロスアテンションで画像生成を条件付けるように、象徴秩序が制作工程の深部に入り込んでいる。
また、学習データの偏り(bias)は「何がそれらしく語られるか」「誰がどんな役割で表象されるか」を規定するシンボル的秩序として作用する。CLIPはデータの能力と偏りの体系的把握が課題であることを明示しており、Stable Diffusion系はLAION由来の大規模データの安全配慮の必要性を警告している。データの地盤が「記号論的地盤」でもあることを、開発者・研究者は強く意識する必要がある。
意味論的帰結——誤認・誤帰属・権利侵害のリスク構造
インデックス誤認が引き起こす誤情報の温床
生成AIコンテンツは外界対象の作用を受けた痕跡ではなく、学習と条件付けからの推定産物だ。それゆえ生成物が示す「それらしさ」は、類似(アイコン)としては強くても、出来事への参照保証(インデックス)としては原理的に弱い。しかし人間の真偽判定能力がディープフェイクに対して限定的であることは、複数のメタ分析が繰り返し指摘している。報道・行政・法務の現場では、生成物を証拠として扱わない明示的なルールと検証プロトコルが不可欠だ。
作者性の分散と責任の曖昧化
モデル開発者、データ提供者、プロンプト入力者、編集者、配布プラットフォーム——生成コンテンツの形成には複数の主体が関与する。これは解釈項(どのような意味効果が生まれるか)の責任主体が分散することを意味し、従来の「作者」概念では捉えられない新たなガバナンスの課題を生む。
日本の著作権・人格権への影響
文化庁は2024年3月に「AIと著作権に関する考え方について」を公表し、学習段階の著作物利用、生成・利用段階の侵害判断、AI生成物の著作物性(創作意図・創作的寄与の有無)などを整理した。ただしこれは拘束力のない整理であり、技術発展や事例蓄積を踏まえた継続的な見直しが明記されている。
著作権にとどまらず、実在人物の顔・声・名前に関わる肖像権・プライバシー・パブリシティ権との摩擦も深刻だ。生成AIが「本人らしさ(インデックス的類似)」を人工的に生成できてしまうため、これらの権利侵害リスクは構造的に高い。
EU AI ActとC2PAが描く国際的規制の枠組み
欧州ではAI Act(Regulation (EU) 2024/1689)が成立し、透明性義務とリスクベース規制の枠組みが段階的に施行されている。C2PA等の来歴標準はグローバルに標準化が進む一方、プラットフォームでの実装とメタデータ保持の実効性にはギャップがある。日本のAI事業者ガイドライン(第1.1版、2025年)も責任分界とリスク管理の枠組みを提示しており、これらは「インデックス性を社会的に回復する制度的足場」として機能しつつある。
まとめ——三項関係の「多層化」として生成AI時代を読む
生成AI時代のパース記号論は「三項関係が崩れる」のではなく、三項関係の接続点が多層化すると捉えるのが適切だ。対象は外界の事物だけでなく、データ分布・プロンプト文脈・プラットフォーム規範へ分岐し、解釈項も人間の心的効果に加えてVLM/LMMの説明やモデレーション判断として外化される。
実務上の優先事項は三点に集約できる。第一に、来歴の可視化をデフォルトにすること——C2PAや透かしの採用とプラットフォーム側の表示実装。第二に、インデックス誤認を前提に設計すること——証拠扱いを禁じるルールと検証プロトコルの整備。第三に、文化的・法的文脈をデータとUIに組み込むこと——偏り監査、地域規範、著作権・人格権への継続的配慮だ。
記号論という古典的枠組みが、生成AIの時代にこれほど鋭い分析力を持つのは、意味が「記号と対象の対応」ではなく「関係の連鎖」として成立するというパースの洞察が、AIが拡張・変容させる「意味の生産過程」を正確に照射するからだ。
コメント