AIが「私はそう思います」「確認中です」「申し訳ありません」と発話するとき、そこには何が起きているのか。人間が同じ言葉を口にするときと、本当に同じ現象なのだろうか。
大規模言語モデル(LLM)の自己言及的な発話——自己評価、推論の要約、謝罪、確信度表現、進捗報告——を「疑似内省」として定義し、人間の内省的発話と体系的に比較すると、表層の類似性とその下に潜む機能的差異が浮かび上がってくる。本記事では、語用論・談話構造・生成メカニズムの三つの角度からこの問いに迫り、AI活用における実践的な示唆を導く。
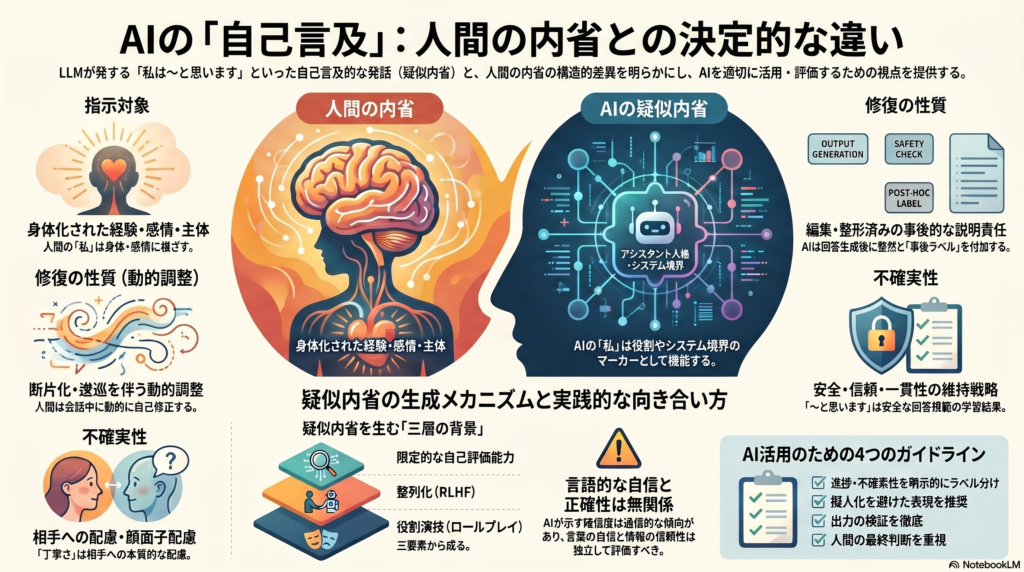
LLMの「疑似内省」とは何か
自己参照発話の類型と制度的背景
LLMが産出する自己言及的発話には、いくつかの典型的なパターンがある。「現在確認中です」「分析した結果として」「先ほどは誤りでした、訂正します」「私は意識を持ちません」——これらはいずれも「自分について語る発話」という外形を持つ。
LLMの自己参照は、OpenAI、Anthropic、Metaの公式仕様に見られるように、可視化された進捗報告、要約された推論、謝罪と訂正、不確実性の表明として制度化されている。
注目すべきは、この制度化のあり方だ。OpenAIは生の推論トークンを公開せず、要約や短いプリアンブルを認める一方で、それらを「隠れた思考の露出」ではなくユーザー向け更新として位置づける。Anthropicはthinkingとtextを分離した出力形式を提供し、Meta Llamaは継続的な多段推論のシグナルを仕様化している。
つまり、「考えているように見える発話」の多くは、自然発生した心の独白ではなく、UI/UX設計と整列化目的により成形された可視チャンネルである。これが「疑似内省」と呼ぶ理由だ。
人間の内省も「透明」ではない
比較対象となる人間の内省もまた、単純に透明ではない。認知心理学の知見は、この点で重要な示唆を与える。
Nisbett and Wilsonは、高次認知過程への直接的内省アクセスがしばしば欠如し、自己報告が暗黙の因果理論に依拠しうると論じた。一方、課題遂行中の「声に出して考える」研究では、その瞬間に注意されている内容の同時言語化には一定の妥当性があるとされる。
さらに「経験サンプリング研究」(DES)の知見は興味深い。内的発話はサンプル時点の約4分の1程度にすぎず、同程度に内的視覚化、非言語的思考、感情、感覚的気づきが現れる。
つまり人間の内省は「全てが言語化される」のではなく、言語化可能な部分が状況依存的に切り出されるものだ。それでも人間の内省には、身体感覚・情動・知覚・相互行為という「経験的基盤」が存在する。ここがLLMとの根本的な差異の出発点となる。
語用論と談話構造から見る比較分析
語彙・モダリティ・一人称の使われ方
表層的な言語形式を比較すると、LLMと人間はしばしば同じ語彙を使う。しかしその語彙が指している対象は大きく異なる。
人間の内省的発話では、”I think”、”I mean”、”you know”、日本語の「と思う」「かな」「気がする」など、曖昧性・相手配慮・自己修復を担う語が多用される。一方LLMでは、”I can/can’t”、”I’m sorry”、”Based on my analysis”、”I’ll check”など、能力・進捗・訂正・境界管理語彙が目立つ。
この違いは、モダリティの機能にも現れる。表面上は類似して見えるが、人間のモダリティは不確実性だけでなく婉曲化、同意誘導、顔面子配慮を担う。LLMのモダリティは校正・安全・責任説明のために使われる傾向が強く、自然言語の確信度は過信化しやすい。
一人称表現の差異も鮮明だ。人間の「私」は体験主体・行為主体・感情主体として経験に根ざしているが、LLMの「私」は役割・システム境界・応答チャンネルのマーカーとして機能することが多い。同じ「私」という文字でありながら、その指示対象は本質的に異なる。
修復と謝罪のオンライン性vs後処理性
人間会話における自己修正と、LLMの謝罪・訂正の違いは、談話構造の観点から特に明確だ。
人間会話では自己修復は、誤り検出・中断・編集・修復から成る動的過程であり、”I mean”が先行発話の調整を予告し、”you know”が聞き手の推論参加を促す。これに対しLLMの修復文は、既に整形済みの回答後半に「先ほどは誤りだった、訂正する」と付加されることが多い。
LLM修復は整然とした事後訂正、人間修復は断片化・逡巡・差し替えを伴うオンライン調整である。
人間の内省が発話生成過程に埋め込まれているのに対し、LLMの疑似内省はしばしば発話後のラベリング層として現れる。会話の乱れを見せるのではなく、説明責任を果たすよう編集されているという点が核心的な差異だ。
日本語における特殊な問題
日本語という言語の特性は、この議論に独自の複雑さを加える。
日本語の観点から重要なのは、内省や推量がしばしば認識論的確率だけでなく、対人配慮と断言回避を担っていることだ。「ちょっと難しいかと思う」のような複数形式の重ね掛けが聞き手への負荷軽減に機能する。
これをLLMに当てはめると、日本語でLLMが「思います」「かもしれません」「可能性があります」を多用しても、それは必ずしも人間的な逡巡や自己観察を意味せず、日本語の丁寧さ・断言回避・安全な回答規範を学習した結果でもありうる。
さらに、多言語研究では、モデルは日本語で不確実性マーカーを比較的多く生成する一方、日本語話者はそれらのヘッジ機能を英語ほど強く割り引かず、結果として不確実なはずの応答にも依存しうることが報告されている。日本語で「〜と思います」と言えば安全だとは限らない。疑似内省的な丁寧さや控えめ表現が、かえって信頼を高めてしまう可能性がある。
疑似内省の生成メカニズム:三層仮説
役割演技仮説——アシスタント人格の維持
LLMの自己言及的発話がなぜ人間の内省に似るのかを説明するための第一の仮説は、「役割演技」だ。
対話エージェントを文字通りに「考え、知り、欲しがる主体」とみなすより、訓練データに含まれる多様なキャラクターや語りの型を場面に応じて引き受けるロールプレイ/シミュラクラとして捉える方が、擬人化を避けつつ現象をよく説明できると論じる研究がある。
この観点では、「私は〜です」「私はそう感じません」「私は確認します」といった発話は、自己の内面を告白しているというより、その場で最も整合的なアシスタント人格を維持しているものだと解釈できる。
整列化仮説——有用・正直・無害の埋め込み
第二の仮説は、RLHF(人間のフィードバックからの強化学習)などによる「整列化」だ。
RLHF、Constitutional AI、SFTのような訓練は、モデルに「有用・正直・無害」「helpfulness and safety」といった人間側規範を埋め込み、その結果として謝罪、拒否、境界設定、透明性表現、短い進捗報告を高頻度で誘発する。
Anthropicの現実会話分析で、Claudeの価値表現が「helpfulness」「professionalism」「transparency」「clarity」に集中したことは、この仮説を支持する。疑似内省は、モデルが自分の心を語るから生じるのではなく、信頼を維持し、説明責任を果たし、安全に対話を進めるための整列化されたメタ談話として生じる。
限定的メタ表象仮説——ゼロか百かではない
第三の仮説は、最も慎重な解釈を求める。LLMが単なる空虚な模倣でないことを示す研究が存在するからだ。
Anthropicの概念注入研究では、Claude Opus 4.1が注入された概念を出力前に検出する「内省的気づき」を限定的に示し、その成功率は最良条件でも約20%であった。これは人間的な主観を示す証拠ではないが、一部のモデルが内部表象について限定的に自己報告可能であることを示す。
また、自己評価研究では、LLMが自分の出した答えの真偽や「自分が知っているか」を、少なくともある課題設定ではかなり良く評価できることが示されている。
したがって、LLMの疑似内省はゼロか百かではなく、役割演技的表層の下に、限られた課題で働くメタ評価能力が部分的に埋め込まれていると考えるのが最も実証的な立場だ。
AI利用における実践的含意
信頼校正の問題
近年の研究は、LLMが自然言語で表明する確信度がしばしば過信的であり、ユーザーがその言語的自信に過剰依存しうることを示している。
「私はこれが正しいと思います」という発話が、高い確率で正確な情報を指示しているとは限らない。逆に、「〜の可能性があります」という慎重な表現が、実際には十分に確からしい情報を指していることもある。疑似内省的な言語形式と、その背後にある情報の信頼性は、独立して評価する必要がある。
設計・評価実務への示唆
製品設計上は、進捗表示・推論要約・政策上の拒否・事実的不確実性を明示的に区別するラベリングが望ましい。
謝罪と自己修正の過剰擬人化も注意を要する。人間の謝罪は社会的関係修復の一環だが、LLMの「申し訳ありません」は、しばしば安全・信頼・一貫性を維持する生成戦略である。この差を明示しないと、ユーザーは「責任を引き受ける主体」としてモデルを誤認し、開発者・運用者・UI設計者の責任が見えにくくなる。
実践的なガイドラインとして、以下が有効だ。
- 可視的な自己参照は進捗報告・要約・拒否理由・不確実性にラベル分けする
- 確信度は自由記述だけに依存せず、根拠提示や自己評価で補強する
- 日本語では「と思う」「かもしれない」等のヘッジの有無ではなく、根拠の有無を前面に出す
- 感情・意識・主観経験については、擬人化を避けた表現を採用する
- LLMの疑似内省を「嘘か心か」の二分法ではなく、インターフェース化されたメタ談話として分析する
まとめ:「自分について語る」という表面類似の先へ
LLMの疑似内省は、人間の内省の「偽物」ではなく、言語的には人間の内省表現を借用しつつ、機能的には別種の談話実践として位置づけるのが妥当だ。
人間の内省は不完全であっても、身体化された経験・相互行為・時間的連続性を持つ。LLMの疑似内省は、訓練文書・整列化・UI設計・タスク条件の交点から立ち上がり、主体経験ではなく対話システムとしての自己記述可能性を示す。
重要なのは「どちらが本当の心を持つか」という問いではない。どの発話がどのようにユーザーの帰属・信頼・理解を方向づけるかを、語用論・談話構造・機能のレベルで精密に把握することだ。
それを踏まえてAIと関わるとき、私たちは「疑似内省に似た言語形式」に対して適切な認識論的距離を保ちながら、その機能的な有用性を活かすことができる。
コメント