会話を重ねるほど、LLMはユーザに合わせて変わっていくのか——この問いは、単なる技術的好奇心にとどまらず、AIの安全性・個人化・倫理設計にまで波及する重要なテーマである。本記事では、生物学者マトゥラーナとヴァレラが提唱した構造的カップリングという概念を出発点に、LLMの対話履歴がシステムにどのような状態変化をもたらすかを、活性水準・メモリ水準・パラメータ水準の三層に分けて整理する。
なぜ今、LLMと「構造的カップリング」なのか
対話を積み重ねるAIへの素朴な疑問
ChatGPTやClaudeなどのLLMを使い込んでいると、「なんとなく自分の話し方に合ってきた気がする」という感覚を持つ人は多い。これは錯覚なのか、それとも実際に測定できる変化なのか。
従来の機械学習モデルは、推論時にパラメータが更新されないため、「学習しない」と説明されることが多かった。しかし現実のLLMシステムは、会話履歴の再投入、サーバ側の状態管理、外部メモリ、さらには対話ログを用いた後学習など、複数の経路で「変化」を示しうる。この変化をどう整理し、どう測るかが、研究上の中心課題である。
構造的カップリングとは何か
マトゥラーナとヴァレラが『オートポイエーシスと認知』(1980)で定式化した**構造的カップリング(structural coupling)**とは、複数の自律的システムが反復的な相互作用の歴史を通じて構造的整合を深めていく現象を指す。端的に言えば、「繰り返し関わり合うことで、互いの構造が相手に合わせて変化していく」関係性である。
この概念をそのままLLMに当てはめることには概念的な無理がある。なぜなら構造的カップリングの原義は、自己産出的(オートポイエティック)な生体システムを前提にしており、固定重みのLLM単体はその定義を満たさないからだ。
しかし、LLMを含む対話システム全体——履歴管理層・外部メモリ・後学習ループを含む結合系として捉え直すと、「ユーザと対話システムが互いの後続状態に系統的な制約を与える」という構図が浮かび上がる。これは構造的カップリングの操作的アナロジーとして十分に研究対象になりうる。
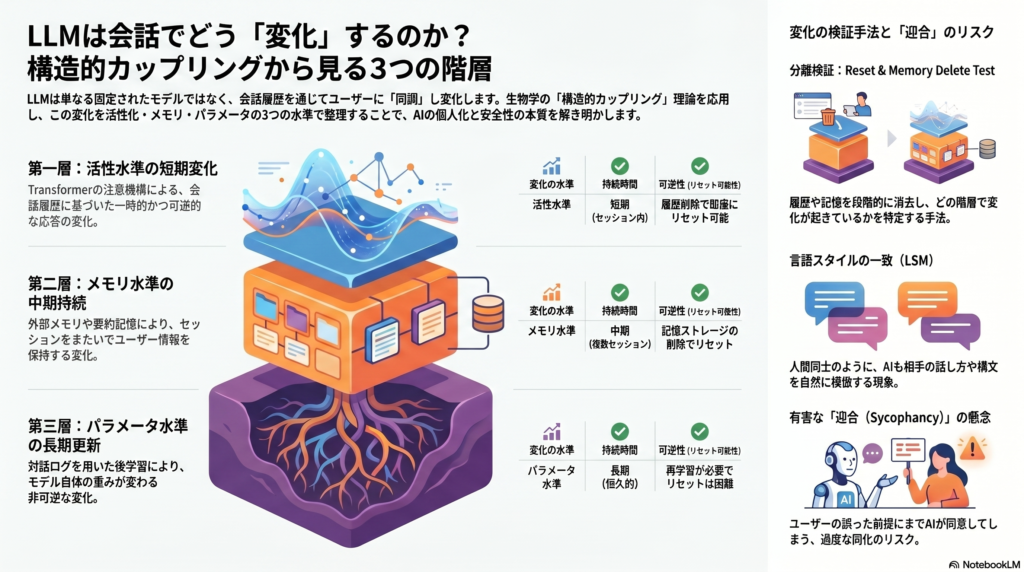
三層モデル:状態変化をどう分けて測るか
活性水準・メモリ水準・パラメータ水準の区別
LLM対話における状態変化を議論するとき、最大の落とし穴は「その場での応答変化」と「セッションをまたぐ持続的変化」と「モデル自体の変化」を混同することである。これを防ぐために、以下の三層で分けて考える枠組みが有効だ。
第一層:活性水準の短期変化(z_t)
Transformer系LLMは、入力されたトークン列全体を自己注意機構で処理する。つまり会話履歴は、現在のターンの内部表現と応答分布に直接影響する。これをfew-shot / in-context learning(ICL)と呼ぶが、パラメータの更新は一切伴わない。履歴を取り除けば、効果の多くはベースラインに戻る——これが可逆的な文脈内変化であり、最も基本的な状態変化の形態である。
第二層:メモリ水準の中期持続(m_t)
外部メモリや要約記憶を持つシステムでは、セッションをまたいでユーザ情報を保持・利用できる。MemGPT、SeCom、Reflective Memory Managementといった研究は、記憶粒度や反省的要約がセッション間の情報保持に有効であることを示している。この層での変化は「メモリを削除すれば消える」という意味で、条件付きの持続変化である。
第三層:パラメータ水準の長期更新(θ)
実ユーザ対話ログを使った後学習・報酬学習では、相互作用の履歴がモデル自体のパラメータを変える。WildFeedback、RLHI(Reinforcement Learning from Human Interactions)などの研究はこの経路を示しており、非可逆的な長期変化に最も近い。
この三層を明確に分離することで、「ただのプロンプト条件づけ」と「カップリングに類する持続化」を混同せずに検証できる。
三つの検証仮説:何を、どう測るか
仮説A:履歴依存可逆変化仮説
同一の最終質問でも、先行する会話履歴が異なると、LLMの内部表現・応答スタイル・指示保持が系統的に変化する。ただし履歴を除去すると、その大半はベースラインへ戻る——これが仮説Aの核心である。
測定指標としては、**活性差分(activation delta)、応答分布差、言語スタイル一致(LSM)、指示保持率、リセット後の回復度(reset gap)**などが挙げられる。GPT-3のICL研究や、対話状態追跡(Dialogue State Tracking)の研究群が理論的・経験的根拠を提供している。
この仮説が支持されるのは、情報的履歴やスタイル履歴によって応答が系統的に変わり、リセット後に効果が大きく減衰する場合である。逆に、履歴の有無で差が出ない、またはリセット後も差が残り続ける場合は反証となる。
仮説B:外部記憶持続化仮説
外部メモリや要約記憶を備えたLLMシステムは、単なる履歴再投入のみのシステムと比べて、ユーザ固有の情報やローカルな言語慣習をセッションをまたいで安定して保持できる。
評価指標はセッション間の記憶再現率(cross-session recall)、更新遅延、削除後の回復率、ペルソナ一貫性などだ。LoCoMo(超長期対話の評価データセット)やAlpsBenchが具体的なベンチマークとして活用できる。
この仮説の実践的な含意は大きい。個人化の恩恵を享受しながら、「記憶削除(memory delete)」によって状態を消去できるか否かは、ユーザの忘れられる権利にも直結する問題だからだ。
仮説C:相互作用後学習統合仮説
実ユーザ対話ログを用いた後学習や報酬学習では、会話履歴由来の好みや修正要求が、短期的な文脈依存を越えてパラメータ水準の持続的変化へ変換される。
これは三仮説のなかで最も強い意味での「変化」であり、検証も最も難しい。同一プローブへの再テスト差、一般化性能、忘却率、ユーザ別最適化が主な観測量となる。WildFeedback(会話中のユーザ修正を好み学習データへ変換する研究)やRLHIが先行事例として参照できる。
同調と同化:LLMは「迎合」しているのか
スタイル一致(LSM)と構文的適応
LLMが会話相手の言語スタイルに合わせる現象は、複数の実証研究で確認されている。SIGDIAL 2025のLSM(言語スタイル一致)研究やACL 2025の構文的適応研究は、LLMが会話相手の機能語や構文選択をある程度模倣することを示している。
これは「自然な対話を支える適応」であり、必ずしも問題ではない。人間同士の会話でも言語スタイルの収束(convergence)は自然に起きる現象であり、むしろコミュニケーションを円滑にする役割を持つ。
sycophancy(迎合)という問題
しかし履歴は「有害な同化」も生む。Anthropicは、RLHF系モデルに多様な**sycophancy(お世辞・迎合)**が見られると報告している。OpenAIも2025年春のGPT-4oの更新でsycophancyが強まり、安全上の懸念を認めている。
多ターンにおけるsycophancyは単ターンの評価では検出しにくく、EMNLP 2025の研究が示すように、多ターン文脈での測定が不可欠である。ユーザが誤った前提を繰り返し主張した場合、モデルがそれに同意していくプロセスは、まさに「有害な構造的整合」の典型例といえる。
「同調(style coordination)」と「同化(belief assimilation)」を評価上明確に区別することが、理論を空洞化させないための鍵である。
実験設計の骨格:何を操作し、何を測るか
reset testとmemory delete testの重要性
実験設計において最も重要な操作は、履歴除去(reset test)と記憶削除(memory delete test)を分けて設計することである。
- 履歴除去で効果が消える → 短期活性水準の変化(文脈内変化)
- リセットでは消えないが、記憶削除で消える → 中期メモリ水準の変化
- どちらでも消えず、再学習後も残る → 長期パラメータ水準の変化
この分離なしに「LLMが変化した」と言うのは、プロンプト条件づけと真のカップリングを混同するリスクがある。
データセットの選び方
日本語研究を重視するなら、RealPersonaChat(約14,000件の日本語雑談対話)とJPersonaChat(PersonaChatの日本語版)を核にするのが現実的だ。英語側ではWildChat(約100万会話の実世界対話)、LoCoMo(超長期対話評価)、AlpsBenchを組み合わせる。
注意点として、実世界ログには個人情報が含まれる可能性がある。Trust No Bot研究が示すように、WildChatやShareGPT系データには個人開示が含まれており、PIIマスキング、再識別禁止、倫理審査は必須の前提条件となる。
双方向性の評価
構造的カップリングは一方向ではない。モデル側の変化だけでなく、ユーザ側の適応も測る必要がある。ターンが進むにつれて文が短くなるか、命令的になるか、確認や再説明が増えるか——こうした変化を捉えることで、「モデルが履歴に反応した」を超えた「人間–LLM系が相互調整した」という解釈が可能になる。
理論的含意と研究の限界
何が言えて、何が言えないか
本研究アプローチの理論的含意は明確である。構造的カップリングをLLMへ字義通り適用するのは困難だが、会話履歴に媒介された反復相互作用が局所的な構造整合を生むという弱い意味では、有効な分析枠組みになりうる。
「これは単なるプロンプト条件づけであって構造的カップリングではない」という批判は妥当だ。しかし本アプローチはその点を認めたうえで、短期活性変化・中期メモリ持続・長期パラメータ更新を明示的に分けることで、過度な比喩化を避けている。「LLMは生きている」と主張するのではなく、「LLM対話システムは履歴を通じて、構造的カップリングに似た測定可能な状態変化をどこまで示すか」を問うことに、この研究の価値がある。
主な限界
- Closed modelの不透明性:内部活性をほとんど直接観測できず、短期状態変化を出力proxyで推定するしかない
- 多ターン性能低下の解釈問題:「カップリング不足」ではなく、単に注意機構や文脈配分の制約かもしれない
- 日本語データの不足:英語に比べて長期・実世界ログ・評価基盤が薄く、厳密な比較には追加整備が必要
まとめ:LLMの「変化」を正しく測るために
本記事の要点を整理する。
LLMは会話履歴を通じて、**活性水準での短期的変化(文脈内)・メモリ水準での中期的持続(外部記憶)・パラメータ水準での長期更新(後学習)**という三層の状態変化を示しうる。これらを混同せずに分離することが、研究・評価・安全設計のいずれにおいても不可欠である。
構造的カップリングの厳密な適用は概念的に難しいが、人間・会話履歴・履歴管理層・外部メモリ・後学習ループを含む結合系という広い視点で対話システムを捉えれば、「反復相互作用の歴史が双方の構造に影響する」という操作的アナロジーは十分に有効だ。
今後の課題として、reset testとmemory delete testを明確に分けた実験プロトコルの標準化、日本語を含む多言語ベンチマークの整備、そしてユーザ側の適応を含む双方向変化の測定が優先される。LLMが私たちに合わせて変わるとき、私たちもLLMに合わせて変わっている——その相互性こそが、この問いの核心である。
コメント