なぜ今、ベイトソンとマルチエージェント学習を結ぶのか
AIが教育・医療・都市インフラに浸透しつつある現代、「誰が・何を・どう学んでいるのか」という問いは根本から問い直されている。人間個人が情報を蓄積するという古典的な学習観では、人とAIと物理環境が互いに影響しながら変化していくプロセスを十分に記述できない。
そこで本稿が注目するのが、グレゴリー・ベイトソン(Gregory Bateson)の全体系観(エコロジー)と、マルチエージェント強化学習(MARL)の理論的接続である。ベイトソンは学習を「個体の皮膚の内側」ではなく「関係とパターンのシステム」として捉えた。一方MARLは、複数のエージェントが協調・競合しながら環境に適応する学習を扱う。両者を組み合わせることで、「人間+AI+環境」を一体の学習主体と見なす記述論的枠組みが生まれる可能性がある。
本稿では、①ベイトソンの主要概念、②MARLの理論と手法、③「人間+AI+環境」系の統合枠組み、④記述論的研究手法、⑤倫理・設計上の課題、という順で論を進める。
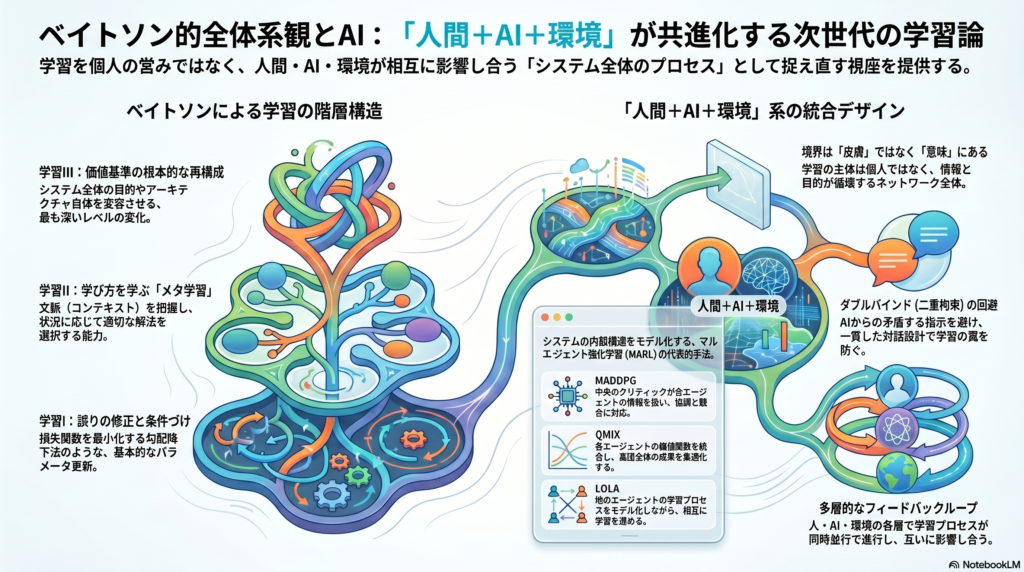
ベイトソンの全体系観|学習は「関係のパターン」の中で起きる
学習階層:ゼロ学習からLearning IIIまで
ベイトソンは学習を四つの階層に分類した。この学習階層の考えは、現代のAI研究における階層学習・メタ学習と深い親和性を持つ。
ゼロ学習(Learning 0) は、環境への反応が固定されており、誤り修正が行われない段階である。単純な反射がその典型で、「入力→出力」の関係がほぼ変化しない。
学習I(Learning I) は、誤りのフィードバックによって行動の特異性が変化する、いわゆる条件づけ型の学習である。機械学習に置き換えれば、損失関数を最小化するようにパラメータを更新する基本的な勾配降下法に相当すると考えられる。
学習II(Deutero-learning) は、「学び方を学ぶ」段階である。学習Iが起きるコンテキストそのものを変える能力に相当し、例えばある問題の解き方だけでなく「どういう状況でどの解法を選ぶか」という判断枠組みを獲得することを指す。AIの文脈では、メタ学習(Meta-Learning)やカリキュラム学習がこれに類似する。
学習III は、さらにその上位で価値基準や目的そのものを再構成するような変容を指す。AIにおけるアーキテクチャの根本的な再設計やアルゴリズム選択の変更に対応し得る、最も深いレベルの変化である。
ダブルバインド:矛盾したコミュニケーションが生む学習の罠
ベイトソンが家族療法の文脈で提唱した**ダブルバインド(Double Bind)**は、「矛盾したメッセージが繰り返し与えられ、逃れも説明もできない関係」を指す。例えば口頭では「落ち着いて」と言われながら、態度や表情で不安を伝えられるような状況では、どの反応も「間違い」とされるパラドックスに陥る。ベイトソンはこれを「病的な第二段階の学習」と呼んだ。
現代のAIシステムに引き寄せれば、AIが人間に矛盾する指示を与え続ける設計は、ユーザーをダブルバインド状況に置くリスクがある。UI/UXや対話設計において、このパラドックスを回避することは重要な倫理的課題となる。
情報と意味:「違い」が「違い」を生み出すとき
ベイトソンは情報を「違い(差異)が違いを生じさせるもの」と定義した。単なるデータ量(情報量)とは別に、文脈の中でその違いがどう解釈されるかという「意味」の次元を区別したのである。この視点は、現代のデータサイエンスが「データから知見・意味を見出す」という営みに深く通じており、単なる統計的パターン抽出を超えた文脈解釈の重要性を示唆している。
パターンのパターン(メタパターン):つながりを結ぶもの
ベイトソンは著書『Mind and Nature』(1979年)で、「つながりを結ぶパターンはメタパターンであり、パターンのパターンである」と述べた。この「メタパターン」概念は、個別現象を超えた相互関連性を重視するベイトソンの方法論の核心であり、生態系・社会・認知にまたがる普遍的な構造を捉えようとするものだ。
現代の認知科学では、この視点が**拡張認知(Extended Mind)や認知生態学(Cognitive Ecology)**として受け継がれている。Clark & Chalmersの拡張心理論では、AIツールや環境を用いた認知活動は「心の外部化」の一形態とされ、AIアプリとの協働そのものが心的プロセスの一部と見なされる。Hutchinsの認知生態学もまた、「認知は脳内だけでなく身体や世界に分散している」とし、ベイトソンの「心は個体内に限られない」という洞察と合致する。
マルチエージェント強化学習(MARL)の理論と代表手法
MARLの基本構造:マーコフゲームと協調・競合の設定
マルチエージェント強化学習(MARL)は、複数のエージェントが協調・競合しながら行動を学習する設定を扱う強化学習の拡張である。単一エージェントの場合のマルコフ決定過程(MDP)を拡張した**マーコフゲーム(Markov Game)**によってエージェント間の相互作用がモデル化される。
MARLには大きく「中央集権型学習/分散実行」と「独立学習」の二つの方向性がある。前者では学習時に他エージェントの情報を共有しながら協調的な方策を学び、実行時は各エージェントが独立して行動する。後者では各エージェントが独立して学習し、他エージェントを環境の一部として扱う。
代表的な手法
MADDPG(Multi-Agent Deep Deterministic Policy Gradient)は、各エージェントにアクター・クリティックを割り当て、中央のクリティックが全エージェントの情報を扱う設計で、協調・競合の両環境に対応する。
VDN(Value-Decomposition Networks)は協調問題に特化し、各エージェントのQ関数を加算して全体のQ値とするシンプルな値分解方式である。
QMIX はVDNの拡張で、個別Q値をモノトニックな関数で結合することで表現力を高めている。StarCraft Multi-Agent Challenge(SMAC)などのベンチマークで高い性能を示す。
LOLA(Learning with Opponent-Learning Awareness)は、他エージェントの学習プロセスをモデル化しながら自身も学習するという相互学習の視点を持ち、協力ゲームと競争ゲームの双方に適用可能である。
MAPPO はProximal Policy Optimization(PPO)をマルチエージェントに拡張したもので、協力ゲームで安定した高性能を示している。
これらの手法はStarCraft IIのAI対戦(DeepMindのAlphaStar)、Dota2エージェント(OpenAI)、交通制御、ロボット群制御など多様な応用環境で評価されている。
MARLの主要な課題
MARLには固有の困難が伴う。他エージェントの学習により環境が常に変化する非定常性、各エージェントが環境全体を観測できない部分観測問題、エージェント数の増加に伴うスケーラビリティ、そして集団の成果を各エージェントの貢献に分解するクレジット割当問題が代表的である。これらへの対応として、グラフニューラルネットワークを用いた通信制御や、階層的学習アーキテクチャが研究されている。
「人間+AI+環境」を一体の学習主体とする統合枠組み
システムの境界を「意味の領域」として再定義する
ベイトソンの洞察を踏まえると、「人間+AI+環境」の学習システムにおける境界は、個体の皮膚や機械の筐体ではなく、情報や目的によって規定される「意味の領域」として再定義できる可能性がある。学習の主体は人間個人でも、AIエージェント単独でもなく、両者と物理・情報環境が構成するネットワーク全体である。
この視点はActor-Network Theory(ANT)とも通じており、人・AI・環境が相互作用するネットワーク的実体として学習を捉える枠組みとなる。
情報フローとフィードバックループの多層構造
このシステムにおける情報フローは単線的ではなく、循環的かつ多層的である。
人間は環境に働きかけ(行動)、その結果を知覚してフィードバックを得る。AIは環境センサーから情報を取得し、学習・推論・制御出力を行う。人間とAIはインターフェース(対話・UI)を介して相互に情報を交換する。さらにこれらの相互作用の結果として環境そのものが変化し、次のサイクルの入力となる。
例えばスマートホームでは、住人が温度設定を変え(人→環境)、室内温度が変化し(環境変化)、AIがそのデータを学習して制御システムに反映する(AI→環境)という閉ループが形成される。この閉ループの中で、人間内(習慣・知識の更新)、AI内(モデルパラメータの更新)、環境変化という複数層の学習プロセスが同時並行で進行する。
ベイトソン学習階層との対応付け
この統合システムにベイトソンの学習階層を当てはめると、以下のような対応が考えられる。
レベルI相当では、人間が日々のフィードバックを受けて行動を微調整し、AIがパラメータを更新する基本的な適応が起きる。
レベルII相当では、学習者が学習方法そのものを工夫し、AIが教材や提示方法を適応的に再構成し、環境のレイアウトが学習に合わせて最適化されるといった、コンテキストレベルの変化が生じる。
レベルIII相当では、教育方針全体の見直しやAIアーキテクチャの根本的な更新など、システム全体の学習枠組みを再構成するような変革が想定される。
つまり、このシステムでは人間とAIと環境が相互に**「学び方を学び合う」**という協調的なメタ学習の場が生まれる可能性がある。
記述論(ナラティブ)としての研究手法|事例研究とデータ収集の設計
事例選定の基準
本テーマにおける研究では、定量データだけに依拠するのではなく、時間を追った現象学的・物語的記述が重要な役割を担う。事例は「人間とAIと環境の相互作用が学習変容を引き起こす可能性がある」具体例から選定する。対照事例(AI有無での比較など)を含めることが、学習変容の記述精度を高める上で有効だ。
代表的な事例候補として、教育分野の適応学習システム(AIが学習者の理解度に応じて教材を動的に調整する)、医療分野のAIリハビリコーチ(動作認識とアドバイス提供を組み合わせた患者支援)、住環境分野のスマートホーム制御(AIが生活パターンを学習して温熱・照明を最適化する)などが挙げられる。
データ収集の多層的アプローチ
観察記録(行動・ジェスチャー)、システムログ(AIの入出力データ、環境センサーデータ)、インタビュー(参加者の認知や経験の変化に関する語り)を組み合わせる多層的なデータ収集が有効である。特に時系列データが重要で、学習プロセスの転換点や「気づき」の瞬間を逃さず記録することが求められる。
分析手法:ベイトソン概念の適用
分析には質的比較分析(QCA)、叙述的因果推論、因果ループ図の作成などが有効である。各事例から「ダブルバインド状況の発生」「学習コンテキストの転換」「メタパターンの出現」といった概念を抽出し、ベイトソン的枠組みとの対応を図式化する。例えば「AIからのフィードバックが人間の認知フレームをどう変え、その変化が再びAIへの入力にどう影響したか」という因果ループを描く手法が考えられる。
倫理的・設計的課題|責任の分散と介入設計
責任とアカウンタビリティの分散
「人間+AI+環境」の統合システムでは、学習成果や失敗の責任が人間個人だけでなくシステム全体に分配される。ベイトソンが指摘したように、「心(Mind)」は個体の「皮膚」に収まらないエコロジー的実体であるならば、説明責任の所在も単一主体には帰せられない。設計者は「誰がいつどの判断をしたか」が追跡可能な透明性を確保し、AIコンポーネントの説明可能性(Explainability)を高める必要がある。
ダブルバインドを回避する対話設計
人間への指示が矛盾するとき、ユーザーは学習不可能な状況に陥る可能性がある。UI設計においては、AIが提供するメッセージの一貫性を保ち、矛盾するフィードバックが重なる場合にはメタレベルの説明(「この指示は先ほどの方針と一部異なります」など)を明示的に提供する仕組みが考えられる。
介入設計:ヒューマン・イン・ザ・ループの確保
境界を越えた学習システムでは、予期しない自己組織化が暴走するリスクに備えて、人間がシステム挙動に介入できる「ヒューマン・イン・ザ・ループ」の機構が不可欠となる。人間が学習プロセスをリセット・調整できるポイントを設計レベルで組み込むこと、またAIが状況を説明して人間の認識修正を促す「AI・イン・ザ・ループ」の仕組みも有効である。
評価指標の多層化
評価は単なるタスク達成率だけでなく、多階層の学習プロセスへのインパクトを測る必要がある。「学習者が新しい学習戦略を獲得したか(学習II相当の変化)」「システム全体のパターンシフトはどの程度か」「ユーザーの信頼度・介入容易性はどうか」といった多角的な指標の開発が今後の課題となる。
まとめ|境界を超えた学習論の可能性と次の問い
ベイトソンの全体系観は、人間・AI・環境を単なる部品の集合ではなく、意味とパターンが循環するエコロジー的学習システムとして捉え直す視座を提供する。MARLが示す複数エージェントの協調・競合ダイナミクスは、この「人間+AI+環境」系の内部構造を部分的にモデル化する手法として有望であり、両者の接続は新しい記述論的研究の方向性を開く可能性がある。
同時に、この枠組みは設計上の責任分散、ダブルバインド回避、評価指標の多層化といった実践的課題と不可分である。単なる理論的接続にとどまらず、具体的な事例研究と実験設計を通じて検証していくことが、次のステップとして求められる。
コメント