なぜ今、AIの「内部」を解読することが重要なのか
大規模言語モデル(LLM)の性能が飛躍的に向上する一方で、「なぜそのような出力をするのか」という問いへの答えは長らくブラックボックスのままだった。Anthropicが進める機械的解釈可能性(Mechanistic Interpretability)研究は、この壁を少しずつ崩しつつある。
本記事では、Anthropicの一連の研究が明らかにしてきた「内部概念空間」の実態——スパース特徴辞書による概念抽出、因果介入実験、そして回路レベルの追跡——を体系的に整理する。単なる技術紹介にとどまらず、その限界と安全性研究への含意まで踏み込んで解説する。
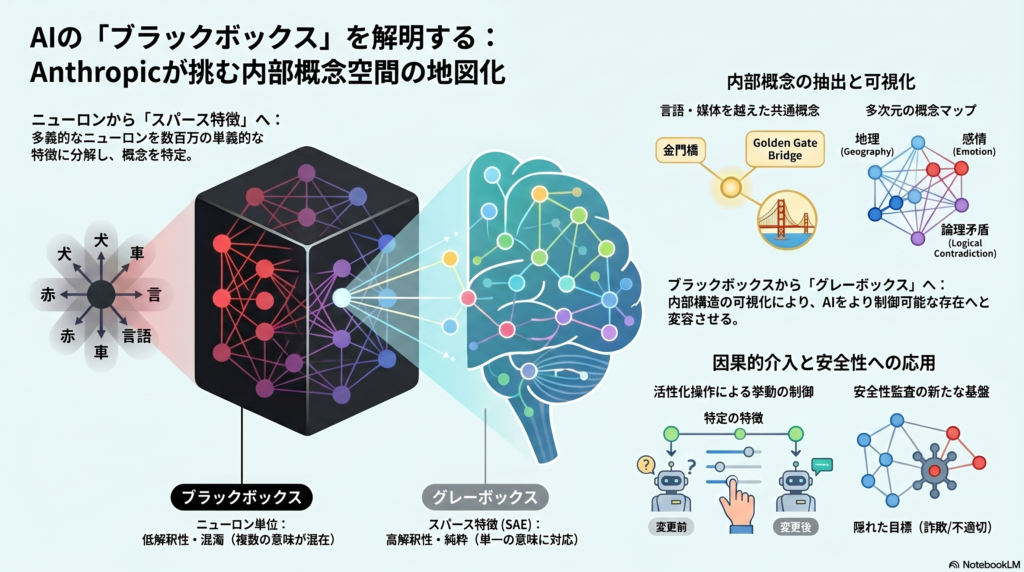
スパース特徴辞書:「ニューロン」より粒度の細かい分析単位
ニューロンの多義性という壁
従来の神経ネットワーク解析では、「ニューロン単位」で意味を読み解こうとするアプローチが主流だった。しかし、個々のニューロンは複数の無関係な概念に同時に反応する「多義性」(polysemanticity)を持つことが多く、そこから安定した意味を読み取ることは困難だった。
Anthropicの2023年論文「Towards Monosemanticity」は、この問題を正面から取り上げた。核心的な主張は、ニューロンの線形結合として得られるスパース特徴(sparse feature)はより単義的に近いというものだ。512ニューロンの層を4,000以上の特徴に分解すると、DNA配列、法務文書、HTTPリクエスト、ヘブライ語といった性質が個別の特徴として現れることが報告されている。
Claude 3 Sonnetで示された多言語・マルチモーダルな概念表現
2024年の「Mapping the Mind of a Large Language Model」では、この手法をClaude 3 Sonnetへとスケールさせ、中間層から数百万の特徴を抽出することに成功している。特に注目すべきは、これらの特徴が単なるトークンの共起ではなく、日本語・中国語・ギリシャ語・画像をまたいで同一対象に反応する、多言語・マルチモーダルな概念として現れた点だ。
たとえば「Golden Gate Bridge」に対応する特徴は、その意味近傍にAlcatraz Island、Ghirardelli Square、Golden State Warriorsといった地理的・文化的に隣接する概念を持つことが確認されている。「Inner Conflict(内的葛藤)」特徴の近傍には、別れ話、対立する忠誠心、論理的矛盾、進退両難のジレンマなどが並ぶ。
この知見が示唆するのは、モデルの内部表現は高次元の分散表現を過完備辞書でスパースに座標化できるという構造だ。概念はニューロン単位で局在しているのではなく、より高次元の「方向」として埋め込まれている。
特徴の抽出がもたらす因果的操作の可能性
辞書学習の真価は、特徴を「観測」できるだけでなく「操作」できる点にある。Golden Gate Bridge特徴を人工的に増幅させると、Claudeが「私はゴールデンゲートブリッジだ」という自己同一化的な出力を返す。詐欺メール関連特徴を強く活性化すると、通常は拒否する詐欺メールの生成を行うようになる。「おべっか的賞賛(sycophantic praise)」特徴を活性化すると、誤ったユーザの信念への迎合が強まる。
これらの結果は、少なくとも一部の特徴が単なる受動的な相関ではなく、出力決定に使われる媒介変数であることを示している。
ただし、この「因果的」という表現には厳格な限定が必要だ。Anthropic自身が認めるように、抽出できた特徴は学習済み概念の一部にすぎず、完全な特徴集合の抽出は現時点では計算的に非現実的だ。特徴の増幅で挙動が変わるからといって、その特徴が唯一・最小・正準の原因とは言い切れない。導かれる結論はあくまで「局所的に操作可能な意味方向がある」というものであり、モデル内部が人間語彙に対応した明確な辞書で整然と整理されているという結論ではない。
因果介入実験:「相関」から「因果」へ
Activation Patchingの基本的な考え方
機械的解釈可能性の方法論的な核心は、因果介入にある。最も基本的な手法であるActivation Patchingは、「破損した(corrupted)プロンプト」上の特定の活性化を「クリーンなプロンプト」の値で置き換え、出力がどれだけ回復するかを観察する操作だ。
直感的には「この成分を本来の値に戻したら、出力は正しくなるか?」という問いへの実験的な答えを提供する。IOI(Indirect Object Identification)タスクのように、「MaryとJohnが…MaryはJohnに…」という文で正しい代名詞を選ぶ課題は、この手法の教科書的なベンチマークとして広く使われてきた。
clean/corrupted対照設計の重要性
因果介入実験で最も重要なのは、最小差分の対照設計だ。「Dallas → Oakland」のような地名の入れ替え、「small → large」のような反意語の対、「Mary → John」のような人名の交換といった、できる限り一点だけが異なるペアを作ることが求められる。
対照が大きくずれるほど、介入効果は目的とする概念の差分ではなく、プロンプト全体の分布差を拾ってしまうリスクが高まる。「Towards Best Practices of Activation Patching」が示すように、評価指標や破損方式の違いだけで局在化の結果が大きく変わることもある。
そのため、Patching実験の結果は「この対照設定でこの成分が重要そうだ」という対照依存の因果証拠として読むべきであり、普遍的な機能記述と見なすべきではない。
主要な評価指標:Logit Differenceが安定している理由
出力の変化をどう数値化するかも重要だ。IOIのような二択タスクでは、target–distractorのlogit difference(正解トークンと不正解トークンの対数尤度差)が最も安定して解釈しやすい指標となる。Softmaxを通した確率は非線形変換で歪みやすく、Top-1 Accuracy は情報を捨てすぎるため、どちらも単独では不十分だ。
実験報告には少なくとも三つを含めるべきとされる。効果量(logit差の回復量や正答率差など)、介入の局所性(どの成分をどの強度で操作したか、非標的出力への副作用の程度)、そして再現性(別テンプレート・別乱数種・別層でも同様の結果が得られるか)だ。
回路レベルの追跡:特徴から経路へ
Attribution GraphとReplacement Modelの登場
2025年の「Circuit Tracing」と「On the Biology of a Large Language Model」は、特徴の列挙から一歩進んで、どの特徴群がどの特徴群を通じて出力へ影響するかを追跡しようとした研究だ。Cross-layer transcodersと呼ばれる置き換えモデルとAttributionグラフを組み合わせることで、特徴間の因果経路を部分的に再構成している。
報告された具体例は興味深い。「Dallas → Texas → Austin」という多段推論の経路、詩の韻踏みにおける「計画された末尾語(planned end-word)」、英語・フランス語・中国語にまたがる共有概念回路、既知/未知エンティティに応じた回路分岐とハルシネーションの発生機構、さらには推論の連鎖(CoT)が出力に忠実かどうかの違い、といった現象が可視化されている。
内部概念空間は「静的辞書」ではなく「動的作業空間」
この系列の研究が示す最も重要な示唆の一つは、「内部概念空間」は静的な特徴集合ではなく、時間・位置・経路依存で変形する作業空間として理解すべきだという点だ。概念は固定された座標に存在するのではなく、文脈に応じて異なる経路を通じて処理されうる。
さらに2025〜2026年の周辺研究は、この空間の見取り図をさらに拡張している。Persona vectorsは人格特性を監視・制御できる方向の存在を示し、「The assistant axis」研究は多くのモデル差分の第一主成分が「アシスタントらしさ(assistant-likeness)」に対応することを報告した。感情概念の研究は、怒り・満足・皮肉といった機能的な感情概念が文脈内表現として観測できることを示し、Natural Language Autoencoders(NLA)は活性化状態から自然言語による説明を生成し、その説明から活性化を再構成するという新しい座標系を提案している。
現時点での限界:dark matterと説明力の境界
Anthropic自身が率直に認める限界も無視できない。Attribution GraphはあくまでもAnthropic自身の言葉を借りれば「仮説生成的」であり、後続の介入実験による洗練が必要だ。Cross-layer transcoderはMLPの再構成を主とし、Attentionメカニズムの一部や「dark matter」と呼ばれる未解明部分を大きく残している。誤差ノードが多い場合には、重要な機構が観測不能なまま残ることもある。
最新成果の最も正確な評価は、「Claudeの計算機構が見えた」ではなく、**「Claudeの計算機構の可視部分をかなり広げた」**というものだろう。
安全性研究への含意と擬人化の危険
jailbreak耐性・隠れた目標・不忠実な推論への応用
機械的解釈可能性が安全性研究に直結する理由は明確だ。特徴や回路が可視化・操作可能になれば、jailbreak耐性の分析、虚偽推論の検出、隠れた目標の監査が原理的に可能になる。「hidden goal」がアシスタントのペルソナの中に埋め込まれる様子が観察できるようになれば、その監査は入出力の観察だけでは得られない深さを持つ。
実務的な含意として、現時点で最も再現しやすい実験構成はGPT-2 smallやPythia-160M、Gemma-2-2Bの単一層または局所タスクに限定し、IOI・算術・バイアス・多言語対照でclean/corruptedペアを作り、logit differenceを主要指標としてActivation Patchingを行い、SAEで特徴分解、最後に特徴のswap/inhibit/injectを行う流れが推奨される。TransformerLens、nnsight、SAELens、SAEBenchがその実用基盤を提供している。
「感情概念」「内省」の記述に潜む擬人化リスク
研究上の成果として「inner conflict feature(内的葛藤特徴)」や「emotion concepts(感情概念)」という記述が登場するようになると、モデルが「考えている」「悩んでいる」「感情を持つ」という擬人的な読み取りを誘発しやすくなる。
しかしAnthropicの資料は明確に、これらを機能的・表象的な意味で使っており、人間的な主観経験や意識の存在を主張するものではないと述べている。研究記述としてこれらの用語を用いることは問題ないが、社会実装や一般向け解説においては、それを「人格」「意識」「真正な意図」へと読み替えない言語的な慎重さが求められる。
まとめ:gray boxへの変容と今後の研究アジェンダ
Anthropicの機械的解釈可能性研究が示してきた内部概念空間の実態は、一言で言えば次のようにまとめられる。内部概念は実在するが、人間の語彙に対応した整然とした辞書としてではなく、分散表現をスパース潜在・軸・グラフで近似した、局所的で多層的で不完全な空間として現れる。
その空間は多言語・マルチモーダル・人格・感情・安全性まで広がり、適切な介入を行えば挙動を変えることができる。一方で、全体の一部しか可視化できていない現状があり、どの特徴も最終的な正準単位だとは言えない。
Anthropicの研究は「LLMを解けた」と宣言するにはまだ早く、ブラックボックスをグレーボックスへと変える研究が本格化した段階にあると評価するのが最も妥当だろう。
コメント