なぜ「言い回し」ではなく「行為設計」がプロンプト改善の本質なのか
ChatGPTやClaudeなどの大規模言語モデル(LLM)に指示を出す際、「なんとなく丁寧に書けばよい」「もっと具体的に」という曖昧なアドバイスで終わってしまうことはないだろうか。プロンプトエンジニアリングは、単なる「言い回しの工夫」ではなく、AIに何の行為をさせるかを明確に設計する技術である。
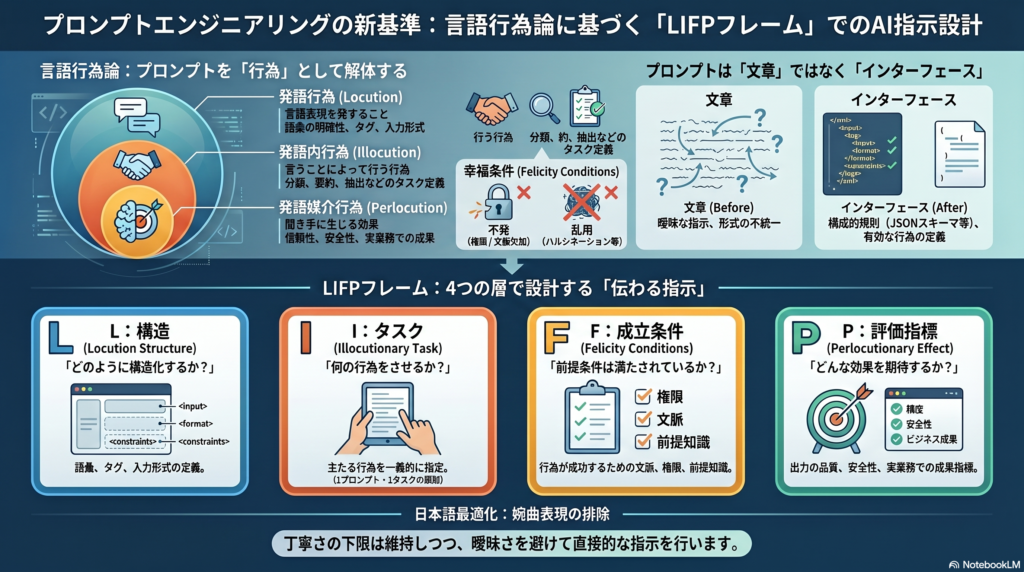
この設計を体系的に捉える枠組みとして注目されるのが、哲学者J.L.AustinとJ.R.Searleが提唱した**言語行為論(Speech Act Theory)**との接続だ。発語行為・発語内行為・幸福条件・発話効果という4つの層で考えると、プロンプトの失敗原因が「精度不足」という曖昧な診断ではなく、具体的な設計欠陥として特定できるようになる。
本記事では、この考え方をLIFPフレームとして整理し、日本語実務での応用を含めて解説する。
言語行為論の基礎|Austin と Searle が教える「発話は行為である」
Austinの幸福条件論:発話の成否は真偽ではなく「成立するか」
オックスフォードの哲学者J.L.Austinは、言語を世界の事実を記述するものとしてだけ捉える見方に異議を唱えた。「この船を〇〇号と命名する」「私は約束する」といった**行為遂行発話(performative)**は、それ自体が何かを「する」行為であり、真か偽かではなく、適切な条件のもとで成立するかどうかが問われる。
この成立条件を彼は「幸福条件(felicity conditions)」と呼んだ。条件が満たされない失敗には2種類ある。
- Misfire(不発):行為自体が成立しない。権限がない、必要な文脈がない、手続きが踏まれていないなど。
- Abuse(乱用):形式上は成立するが、不誠実・不適切な実行。捏造、過剰な確信、不適切なトーンなど。
これをプロンプト設計に置き換えると、Misfireは「パーサが壊れる、必要文脈がない、権限外の操作」に対応し、Abuseは「形式には合うが幻覚(ハルシネーション)が混じる、根拠なく断言する」に対応する。
Austinの三分法:3つの行為層
Austinが到達した発話の三層構造は、プロンプト設計を考える上での土台となる。
| 行為層 | 内容 | プロンプト設計での意味 |
|---|---|---|
| 発語行為(Locution) | 意味のある言語表現を発すること | 語彙の明確性・区切り・タグ・入力形式 |
| 発語内行為(Illocution) | 言うことによって行う行為 | 分類・要約・抽出・確認質問・拒否など |
| 発語媒介行為(Perlocution) | 聞き手に生じる効果 | 有用性・信頼・安全・業務成果 |
「何かを言う」だけでなく、「言うことで何をするか」「その結果何が起きるか」を分けて考える視点は、プロンプト設計において非常に強力だ。
Searleの構成的規則論:「Xは文脈CにおいてYとして数えられる」
Searleはこの枠組みをさらに体系化し、発話行為を**構成的規則(constitutive rules)**に従う制度的行為として捉えた。彼の有名な定式「X counts as Y in context C」(XはコンテキストCにおいてYとして数えられる)は、単なる文字列がどのような制度的効力を持つかを決める規則の仕組みを説明している。
約束を例に取ると、「私は明日までに報告書を提出します」という発話は、単なる未来の予測ではなく、義務の引き受けとして数えられる。これには命題内容規則・準備規則・誠実性規則・本質規則が揃って初めて成立する。
現代のプロンプトエンジニアリングに引き寄せると、JSONスキーマやツール呼び出しの仕様こそがこの構成的規則に相当する。「このテキストが有効な出力として数えられるか」を定める規則として、スキーマは機能している。
LIFPフレームとは何か|4層で設計するプロンプト契約
言語行為論の枠組みを実務のプロンプト設計に接続したものがLIFPフレームだ。L・I・F・Pはそれぞれ以下を表す。
| 層 | 意味 | 設計上の問い |
|---|---|---|
| L(Locution) | 発語行為 | 何を言っているか?語彙・構造・区切りは明確か? |
| I(Illocution) | 発語内行為 | AIに何をさせたいか?行為タイプは一義的に定まっているか? |
| F(Felicity) | 幸福条件 | 何が揃えば成立するか?欠損時の処理・権限・根拠範囲は明示されているか? |
| P(Perlocution) | 発話効果 | 何を成果とみなすか?評価指標は設計されているか? |
設計の順序は「何を言うか → 何をさせるか → 何が揃えば成立するか → 何を成果とみなすか」である。この4ステップで考えると、プロンプトの失敗を体系的に診断・修正できるようになる。
L層の設計:曖昧語を排除し、構造で意味を固定する
発語行為層での典型的な失敗は、語彙の曖昧さと構造の欠如だ。「整理して」「確認して」「いい感じに」といった動詞は、AIにとって解釈の余地が広すぎる。
効果的な技法として、次のものが挙げられる。
- 区切り記法の活用:
###、<task>、<context>などのXMLタグやMarkdown見出しで、指示・文脈・例・入力変数部分を物理的に分離する。 - 語彙の統一:同一概念には同一の単語を使い、類義語による混乱を避ける。
- 入力形式の明示:モデルに渡すデータの形式(JSON、プレーンテキスト、箇条書きなど)を先に宣言する。
I層の設計:タスク動詞で行為タイプを一義的に指定する
発語内行為層での最大の失敗は「行為タイプの混線」だ。同一プロンプト内に「分類する」「要約する」「もし不明なら質問する」が競合すると、モデルはどの行為を優先すべきか迷う。
設計原則としては、1プロンプトに1つの主たる発語内行為を置くことが重要だ。代替的な行為(例:「情報が不足する場合は確認質問を1件だけ返す」)は条件付きで明示する。
Searleの5分類に照らすと、プロンプトで扱う主要な行為タイプは以下のように整理できる。
- Representatives(陳述):事実を答える、要約する、説明する
- Directives(指令):分類する、抽出する、翻訳する
- Commissives(委任):計画を立てる、コードを生成する
- Declarations(宣言):状態を変更する、判定を下す
F層の設計:幸福条件を埋め込んで幻覚を防ぐ
幸福条件層の設計は、ハルシネーション(幻覚)防止の要となる。モデルに「何をすべきか」だけでなく「何をすべきでないか」「何が揃っていない場合はどうするか」を明示することで、成立条件違反(根拠なき断言、文脈外引用)を大幅に減らせる。
具体的な実装例として以下が有効だ。
- 「文脈に記載がない情報は使わない」
- 「必要情報が欠ける場合は推測せず、確認質問を1件だけ返す」
- 「答えの前に根拠箇所を引用する」
- 「出力は指定のJSONスキーマに一致させる」
JSONスキーマやツール呼び出し仕様は、Searle的には「この文字列は有効な出力として数えられる」という構成的規則そのものだ。プロンプトは文章ではなく、制度化されたインターフェースであるという視点への転換が、ここで生きてくる。
P層の設計:評価ループをプロンプトの一部として設計する
発話効果層の設計とは、何をもって「成功」とみなすかを定義し、それを測定可能にすることだ。OpenAIがeval-driven developmentを推奨し、Anthropicがprompt engineeringからcontext engineeringへの移行を論じているのも、この層の重要性を示している。
「正しい内容か」だけを測るのでは不十分で、「正しい行為タイプが選ばれたか」「形式契約は守られたか」「不足時に確認質問へ切り替えたか」まで評価軸に含める必要がある。
評価指標の例として以下が参考になる。
- 行為タイプ適合率:期待した行為ラベル(回答・確認質問・拒否など)との一致率
- 形式遵守率:JSONスキーマ妥当率、パーサ成功率
- 根拠充足率:参照文脈に支持される文の割合
- 安定性:言い換え入力や順序変更での出力一致率
具体例で学ぶ|失敗プロンプトをLIFPで改善する
事例1:JSON抽出タスク
失敗例:
履歴書を読んで必要情報を整理して。- L層の問題:「整理する」という動詞が曖昧。表形式か箇条書きか散文か不明
- I層の問題:「抽出する」という行為タイプが指定されていない
- F層の問題:欠損フィールドの処理方針がない
- P層の問題:出力形式が定まらないため自動評価も困難
改善例:
xml
あなたは採用情報抽出器です。
<task>履歴書から氏名、最終学歴、主要スキル、経験年数を抽出してください。</task>
<rules>出力はJSONのみ。欠損はnull。推測禁止。</rules>
<schema>{"name":null,"education":null,"skills":[],"years_experience":null}</schema>
<input>...入力テキスト...</input>改善のポイントは、Illocutionを「抽出」に固定し、構成的規則としてスキーマを与えている点だ。「何が有効な出力として数えられるか」を事前に定義することで、パーサエラーと幻覚を同時に防ぐ。
事例2:不足情報時の応答設計
失敗例:
わからなくても推測して答えて。これはF層(幸福条件)を完全に無効化する指示だ。自信満々のハルシネーションを積極的に誘発する。
改善例:
xml
あなたは業務アシスタントです。
<task>質問に答えてください。</task>
<rules>必要情報が欠ける場合は、まず確認質問を1件だけ返す。
十分な情報がある場合にのみ回答する。推測で埋めない。</rules>
<input>...入力...</input>ここでの設計の核心は、「答える」以外に**「確認質問する」という代替illocutionを制度化している**点だ。モデルが取りうる行為の選択肢を明示的に定義し、状況に応じて切り替えられるようにしている。
日本語プロンプト最適化の特論|婉曲性と直接性のバランス
「丁寧にすればよい」は間違い
日本語の言語行為論的特性として、敬語・婉曲表現・間接依頼が自然に発生しやすいことが挙げられる。「できれば見ていただけると助かります」という表現は人間同士では自然だが、AIに対してはillocutionary force(発語内力)の曖昧化要因になりうる。
「相談」「依頼」「指示」のどれとして受け取られるかが不明瞭になるのだ。
日本語LLMの評価から見える最適ポイント
言語処理学会での研究によれば、日本語では全モデルで最も無礼な表現が有意に性能を下げた一方で、非常に丁寧な表現が常に最適とは限らないという傾向も観察されている。
つまり、日本語プロンプトの最適化は**「礼貌の最大化」ではなく、「礼貌の下限確保と曖昧性の最小化」**として設計すべきだ。
実務原則に落とすと:
- 避けるべき表現:「もしよければ、なんとなく重要そうな点を見てもらえると助かります」 → illocutionが曖昧で、冗長な観想や雑談が混じりやすい
- 推奨する表現:「次の問い合わせをA/B/Cのいずれか1つに分類してください。出力はラベル1文字のみです。理由は不要です」 → 行為タイプ・出力形式・ラベル空間が全て明示されている
極端な粗暴さを避けながら、婉曲性を減らして直接性を高める——これが日本語における言語行為論的最適化の核心だ。
実務への応用|LIFPチェックリストで既存プロンプトを診断する
プロンプト改善の実務では、以下のチェックリストが診断ツールとして機能する。
L(Locution)チェック:
- 動詞は具体的か(「整理する」→「抽出する」「分類する」)
- 指示・文脈・例・入力変数は区切られているか
- 専門用語や略語に揺れがないか
I(Illocution)チェック:
- 主たる行為タイプは1つに絞られているか
- 代替行為(確認質問・拒否)は条件付きで明示されているか
- ロール設定はタスク動詞と整合しているか
F(Felicity)チェック:
- 欠損情報時の処理方針は明示されているか
- 根拠範囲(文脈内のみか、外部知識も可か)は指定されているか
- 出力スキーマ(構成的規則)は定義されているか
P(Perlocution)チェック:
- 何をもって成功とみなすか定義されているか
- 自動評価できる指標が設計されているか
- 失敗モードをフィードバックして改稿するループがあるか
まとめ|プロンプトは文章ではなく「制度化されたインターフェース」である
本記事の要点を整理する。
プロンプトエンジニアリングの本質は「語彙の微修正」ではなく、発話行為契約の明文化にある。AustinとSearleが示した言語行為論の枠組みを用いると、プロンプトの失敗を「精度不足」という曖昧な診断ではなく、以下の4層の設計欠陥として特定できる。
- L層(発語行為):語彙・構造・区切りの曖昧さ
- I層(発語内行為):行為タイプの未指定・混線
- F層(幸福条件):成立条件の欠落によるハルシネーション
- P層(発話効果):評価ループの未設計
特に日本語実務では、婉曲表現がillocutionary forceを曖昧にするリスクがある。「礼貌の下限確保と曖昧性の最小化」を原則とすることで、より安定したAI応答が期待できる。
JSONスキーマやツール呼び出し仕様は、Searle的には「この文字列は有効な出力として数えられる」という構成的規則そのものだ。プロンプトを「文章」から「制度化されたインターフェース」として捉え直すこと——これがLIFPフレームの核心的な提案である。
コメント