導入:なぜ「人間とAIの意味生成の違い」を理解する必要があるのか
生成AIの評価というと、正確性や有用性を人が採点する「HITL評価」を思い浮かべる人が多いのではないでしょうか。しかし、同じテキストを見ていても、人間がそこから受け取る「意味」と、AIがその文を出力するに至った「過程」は、そもそも同じ土台の上にはありません。人間は既有知識や状況モデル、対話の目的を使って意味を再構成しますが、AIは訓練データの分布や文脈に基づいて次の言葉を予測しているに過ぎない可能性があります。この構造的なズレを理解せずに評価設計を行うと、「モデルの性能が低い」のか「人間に難しい解釈を強いている」のかを取り違えてしまうおそれがあります。本記事では、人間の意味生成プロセスとAIの出力生成プロセスを比較する視点を整理し、HITL評価をどう設計すべきかを解説します。
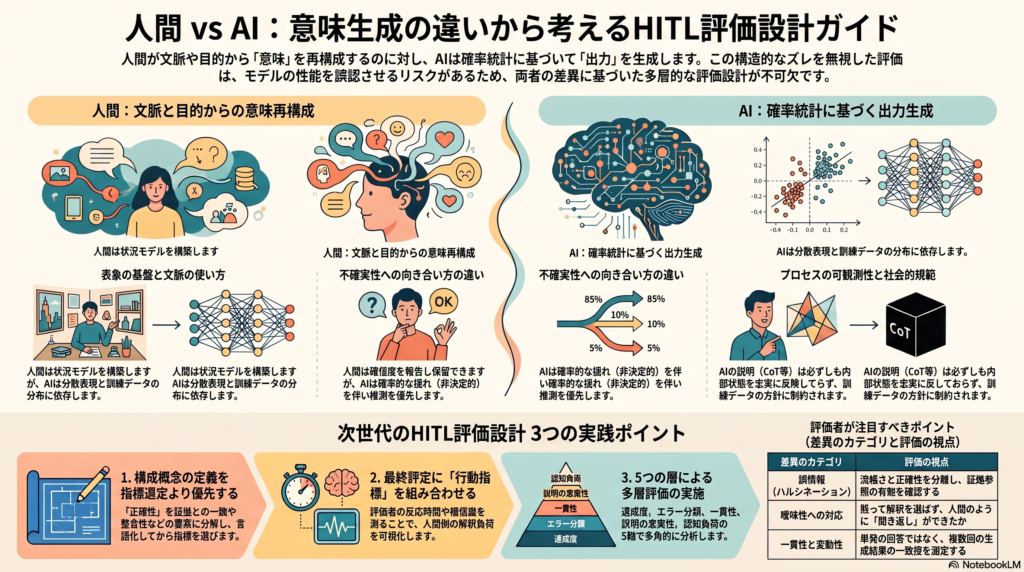
人間の意味生成プロセスとは何か
テキストベースから状況モデルへ
人間の理解は、文字列をそのまま記憶する作業ではないと考えられています。読み手は、表層的な文の情報(テキストベース)を土台にしつつ、時間・空間・因果関係・登場人物の目的などを統合した「状況モデル」を頭の中に構築していくプロセスだと整理されています。さらに近年の研究では、読み手が文脈から次に来る情報をある程度予測し、その予測とのズレを手がかりに理解を更新していくという見方も広がっています。
プラグマティクスと共通基盤
もう一つ重要なのが、人間の意味理解が本質的に「プラグマティック」である点です。対話における理解は、話し手と聞き手が互いの知識を確認し合いながら進む協調的なプロセスだと捉えられており、人は「相手が知っているはずのこと」を前提に、言葉の裏にある意図や含意を補って解釈しています。婉曲表現や非言語的な示唆の理解には、こうした社会的な文脈の読み取りが欠かせません。
人間の解釈を測る指標
HITL評価において、人間の意味生成プロセスを扱う際は、正誤の判定だけでなく、反応時間や自己確信度、判断保留の有無、明確化を求めたかどうかといった行動指標を併せて観察することが有効だと考えられます。評価者の反応が遅かったり確信度が低かったりする場合、それは単に「回答の質が低い」ことを意味するのではなく、解釈の負荷や文脈の競合が生じているサインである可能性があるためです。
AIの出力生成プロセスとは何か
Transformerと自己回帰生成の基本構図
大規模言語モデル(LLM)の中心にあるのは、自己注意機構によって系列内の依存関係を処理し、直前までの文脈から次のトークンを予測し続ける自己回帰的な生成の仕組みです。モデルごとの能力差は、主にモデル規模や訓練データ、最適化手法、そして人間フィードバックなどによるポストトレーニングの違いから生じると考えられています。
出力は確率的で非決定的である
HITL評価で見落とされがちなポイントとして、LLMの出力があくまで確率分布からのサンプリングであり、同じ入力でも出力が揺れうるという性質が挙げられます。公式のガイドラインでも、生成AIの出力は非決定的であり、モデルのバージョンやファミリーが変わることで挙動が変化しうるため、継続的な測定が必要だと明記されています。したがって、一度きりの応答を見て良し悪しを判断するのではなく、複数回生成した際の一致度や安定性まで観察することが望ましいと考えられます。
内部表現と「説明できること」は別問題
近年の解釈可能性研究では、LLMの内部の隠れ状態には語彙や構文だけでなく、真実性や世界の状態に関する情報が部分的に符号化されている可能性が示されています。ただし重要なのは、モデルが外に出す説明文(Chain-of-Thought など)が、その内部状態を忠実に反映しているとは限らないという点です。つまり、モデルが「言わなかった」ことと、内部に「その情報を持っていなかった」ことは、必ずしもイコールではありません。
人間とAIの意味生成プロセス比較:5つの軸
両者の違いを整理する際は、次の5つの軸で捉えると評価設計に落とし込みやすくなります。
- 表象の基盤:人間は状況モデルを構築するのに対し、AIは分散表現上での生成に依拠する
- 文脈の使い方:人間は共通基盤や対話目的を用いるが、AIはプロンプトや訓練分布、デコーディング設定に依存する
- 不確実性処理:人間は確信度を報告し保留や質問ができる一方、AIは訓練・評価設定次第で推測を優先する傾向がありうる
- プロセスの可観測性:人間は反応時間や視線などで間接的に観測できるが、AIはログ確率や説明文で部分的にしか観測できず、説明の忠実性には限界がある
- 社会的規範との関係:人間の理解は常に相手や場面、価値観の影響を受けるが、AIは訓練データの規範やアラインメント方針を反映するにとどまる
この比較軸を意識すると、「同じ出力を見ても、人が再構成した意味とモデル内部の生成メカニズムは一致しない可能性が高い」という前提に立って評価を組み立てられるようになります。
HITL評価で見るべき差異の構造的分類
人間とAIの差異は、単なる誤情報の有無だけにとどまらず、複数の構造的なクラスターとして捉えると評価が安定しやすくなります。
誤情報(ハルシネーション)
人間は世界知識や社会的な責任感から誤りを訂正しやすい一方、AIは流暢でありながら事実と異なる内容を出力してしまうことがあります。この現象は自然言語生成の分野で広く議論されており、定義や評価方法自体もまだ揺れがあるとされています。評価の際は、流暢さと正確性を分けて捉え、根拠となる証拠を参照しているかどうかを評価単位に据えることが重要です。
曖昧性への対応
人間は曖昧な入力に対して明確化を求めたり、共通基盤を頼りに解釈したりできますが、AIは黙って一つの解釈を選んでしまいがちだと指摘されています。評価においては、単に正誤だけを見るのではなく、「そもそも質問を返せたか」という観点を加えることが有効です。
推論過程の可視化と忠実性
Chain-of-Thoughtのような推論の可視化は性能向上に役立つとされる一方で、介入実験によって、モデルが実際に依拠した要因を過少にしか説明していない場合があることが示されています。したがって、推論の説明文をそのまま監査の根拠にするのではなく、説明を変えたときに最終的な回答がどう変化するかを確認する介入的な検証と組み合わせる必要があります。
一貫性と創造性、価値判断
出力の一貫性については、AIは温度設定やプロンプト、バージョンの違いによって揺れる可能性があるため、単発の回答ではなく複数回生成した際の一致・不一致を安全弁として測ることが望ましいとされています。創造性の面では、発散的な課題においてAIが平均的な人間の水準に近づく、あるいは上回る例が報告される一方で、突出した創造性を持つ人間との差は依然として残るとされています。価値判断が絡む場面では、AIが表層的なパターンに寄ってしまう可能性があるため、一般の評価者だけでなく専門家や文化的背景の異なる評価者を交えた検証が推奨されます。
HITL評価設計の実践ポイント
構成概念を先に定義し、指標は後から選ぶ
「正確性」や「有用性」といった言葉は一見シンプルですが、その中身は証拠との一致、世界知識との一致、説明の整合性など複数の要素に分かれます。評価対象となる構成概念をまず明確に言語化し、そのあとで具体的な指標を選ぶという順序が推奨されます。
最終評定だけで終わらせない
正誤の判定だけでなく、反応時間や確信度、判断保留の有無、明確化要求、修正前後の変化、自由記述といった情報を合わせて収集することで、人間側の解釈過程そのものを可視化できます。これにより、AIが「悪い答え」を出したのか、それとも「人間に難しい解釈を要求した」のかを区別しやすくなります。
説明文を唯一の監査根拠にしない
推論の説明やChain-of-Thoughtは有用な手がかりにはなりますが、それが実際の推論を裏づけているかどうかは、介入的な検証を経てはじめて確かめられるものです。回答のみを求めた場合と、説明を付けさせた場合とで結果が変わるようであれば、説明を生成させること自体が出力の分布に影響を与えている可能性があります。
変動性そのものを測定対象にする
生成AIの出力が非決定的であることを踏まえると、単発の応答だけを評価するのではなく、複数回の生成結果の一致度や、プロンプト・バージョンごとの差異を記録し、安定している領域と不安定な領域を切り分けて可視化することが望ましいと考えられます。
多層評価を基本にする
実務では、①タスク達成度、②構造化されたエラー分類、③不確実性と一貫性、④説明の忠実性、⑤人間側の認知負荷と解釈のばらつき、という5つの層を組み合わせて評価する多層的なアプローチが有効だと考えられます。単一のスコアに集約するのではなく、差異のタイプごとに分析することで、評価結果の解像度が高まります。
まとめと次に掘り下げるべき研究テーマ
人間とAIの意味生成プロセスは、表象の基盤から文脈の使い方、不確実性への向き合い方まで、根本的に異なる仕組みの上に成り立っている可能性があります。この違いを踏まえずにHITL評価を設計すると、AIの性能と人間の解釈負荷を混同してしまうリスクがあります。本記事で紹介したように、人間側の解釈過程(確信度・反応時間・明確化要求など)とAI側の生成条件(モデル版・プロンプト・サンプル数など)を分けて記録し、誤情報・曖昧性・推論過程・一貫性・創造性・価値判断といった差異のタイプごとに測定することで、より解像度の高い評価が可能になります。重要なのは、人間かAIのどちらかを絶対的な基準とするのではなく、両者の差異がどのような条件で、どの程度顕在化するのかを継続的に捉え、評価設計自体を改訂し続ける姿勢だといえるでしょう。
コメント