はじめに――「長い文脈を使えば脳に近くなる」は本当か
近年、100万トークンを超えるコンテキスト窓を持つ大規模言語モデル(LLM)が登場し、「AIは人間の脳により近づいた」という言説が広まっています。確かに、GPT系モデルの文脈表現がfMRIやMEGといった脳活動データをよく予測することは、複数の研究で示されています。しかし、「コンテキスト長を延ばすほど脳との対応が単調に改善する」という単純な命題は、現時点では支持されていません。
むしろ最新の比較研究では、AIと脳とでは文脈を蓄積する戦略そのものが異なる可能性が示されており、長大なフラット注意窓は脳との整合を下げることすらあるという報告があります。本記事では、長文脈処理と脳活動アラインメントに関する研究動向を整理しながら、「何が脳アラインメントを高める本当の要因なのか」という問いに迫ります。
なぜ今、「長文脈×脳アラインメント」が重要なのか
相関から因果へ:研究が直面している課題
従来の脳アラインメント研究の多くは、相関研究に留まっていました。モデルの規模・学習量・次語予測性能・コンテキスト長が同時に変化するため、「脳アラインメントが高まった真因」を特定することが難しかったのです。
たとえば、GPT-2よりLlama 3.1の方が脳活動をよく予測できたとしても、それはコンテキスト長(1,024トークン vs 128Kトークン)の違いなのか、学習データ量の違いなのか、アーキテクチャの違いなのかが判断できません。
この問題を解決するために求められているのが、モデル介入と刺激介入を組み合わせた因果的設計です。具体的には、同一刺激に対してモデルのコンテキスト窓長だけをランダムに変えたり、人間側でも文脈の整合性を操作したりすることで、「長さ」「整合性」「圧縮方式」の効果を切り分けることができます。
脳が使う文脈と、AIが使う文脈
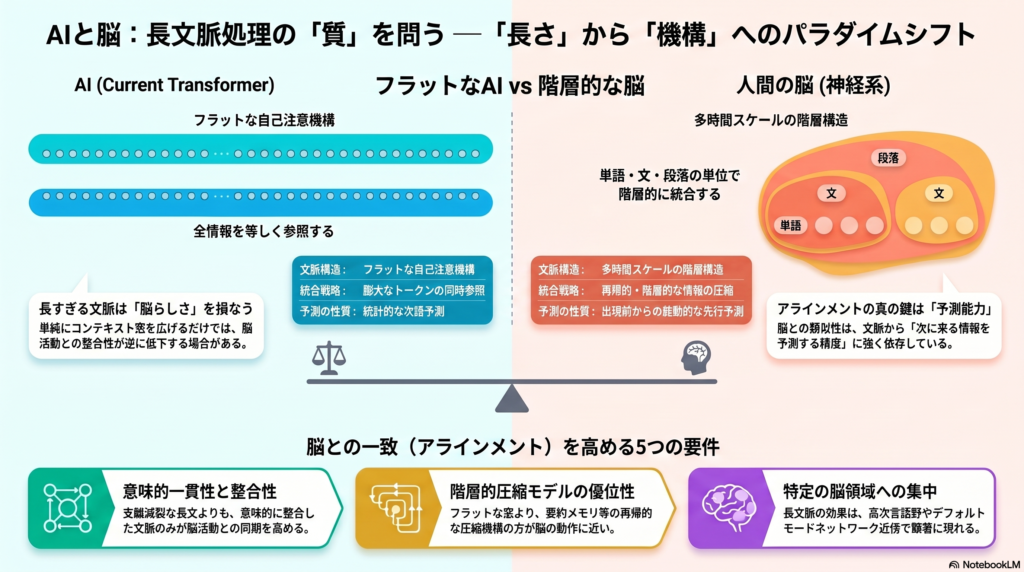
脳神経科学の知見によれば、脳は単語・文・段落といった異なる時間スケールで情報を統合しています。初期聴覚野は短時間スケールの処理を担い、前頭葉や側頭連合野、デフォルトモードネットワーク(DMN)近傍では段落レベルの長距離依存が処理される、という階層的な構造が示されています。
一方、現代のTransformerモデルが採用するフラットな自己注意機構は、膨大なトークンを等しく参照できる一方で、このような再帰的・階層的な統合とは本質的に異なる可能性があります。「脳に近いのはフラット注意よりも階層的・再帰的な圧縮である」という仮説は、今まさに検証が求められている核心的な問いです。
脳アラインメント研究の流れ:何がわかってきたか
文脈表現が静的埋め込みを超えた時代
脳アラインメント研究の大きな転換点は、LSTMやTransformerなどの文脈表現が、静的な単語埋め込みよりも脳活動を広く説明できることが示されたことです。これにより、「文脈を使うモデルほど脳に近い」という基本方針が確立されました。
さらに、次語予測能力(surprisalやentropyで測定)が高いモデルほど脳アラインメントが高い傾向も繰り返し報告されています。Caucheteux & King(2022)の研究では、100名規模の被験者データを用いて、「脳との類似性は主として文脈から単語を予測する能力に依存する」という興味深い知見が示されました。
予測処理と時間構造の発見
Goldstein et al.(2022)は臨床ECoGデータを使い、単語出現前から予測関連の神経信号が現れることを示しました。これは、脳が常に「次に何が来るか」を先読みしており、文脈モデルの長期予測能力がその仕組みに対応している可能性を示唆します。
また、Caucheteux et al.(2023)では、多時間スケールの予測を加えることで脳との対応が改善され、前頭頭頂領域ではより高次・長距離の予測を担うことが示されています。こうした発見は、「予測性能の向上」が脳アラインメント改善の重要な媒介経路である可能性を強く支持します。
「コンテキスト長を延ばせば良い」という単純図式への疑問
ところが最近の比較研究では、AIの単純な長大コンテキストは脳との整合を下げ得るという報告が出てきています。脳は段落規模の再帰的・階層的な統合に近い動作をしており、トークン数を増やすだけでは不十分——むしろ逆効果になりうるということです。
これは研究者にとって重要な示唆であり、「1Mトークンだから脳に近い」という単純な図式が崩れることを意味します。重要なのはどのような機構で遠距離文脈を圧縮・選択・予測に変換するかであり、「長さ」そのものではないということが見えてきました。
因果的検証に向けた実験設計の要点
モデル側と人間側を独立に操作する
最も堅い研究設計は、モデル側のコンテキスト長・整合性と人間側の文脈整合性を独立かつランダムに操作することです。
モデル側では、32〜64トークン(短)、256〜512トークン(中)、2,048〜8,192トークン(長)といった窓長に加え、文脈をシャッフルした条件・無関連プレフィクス・要約メモリ・メモリリセットなどを設けます。人間側では、同一の音声刺激に対して「intact(そのまま)」「段落シャッフル」「文シャッフル」といった文脈破壊条件を用意します。
この二軸を完全に交差させることで、「長さ」と「意味的整合性」を初めて分離できます。たとえば「同じ長さでもシャッフルされた文脈では脳アラインメントが下がるか」を検証することが可能になります。
検証すべき5つの仮説
この研究設計で検証すべき主要な仮説を整理すると、以下の5つになります。
仮説1(媒介効果): 文脈長拡大の効果は、次語予測性能の改善(surprisal/entropyの低下)によって媒介される。文脈を長くしても予測性能が上がらなければ、脳アラインメントも上がらないはずです。
仮説2(領域選択性): 効果は長い時間受容窓を持つ高次言語野(IFG、pSTS/MTG、角回、DMN近傍)に集中する。逆に初期聴覚野では効果が弱いはずです。
仮説3(整合性依存性): 生の長さではなく、整合した遠距離文脈が必要である。意味的に一貫したコンテキストのみが改善を生み、無関連な長いプレフィクスでは改善しないと予測されます。
仮説4(階層的圧縮の優位性): フラットな長大注意よりも、階層的・再帰的な圧縮の方が脳に近い。要約メモリや再帰メモリが、同じ長さのフラット窓より高い脳対応を示すかどうかが焦点です。
仮説5(予測先行性): 長文脈表現は単語出現前から神経活動を先行予測する。MEGやECoGで負のlag(単語出現前の予測信号)が長文脈条件で増大するかを確認します。
計測モダリティの選び方
脳計測には複数の手法があり、それぞれ長所が異なります。
fMRIは高い空間分解能を持ち、IFGや側頭連合野、DMN近傍といった高次言語野の局在を詳細に捉えられます。MEGは高い時間分解能を持ち、単語出現前後の予測関連信号の時系列構造を解析するのに適しています。**ECoG(頭蓋内電極)**は空間・時間の両方で優れますが、臨床患者が対象となるため一般化には限界があります。
最もバランスの良い設計は、同一被験者でfMRIとMEGを別日に計測する主案を中心に、臨床ECoGを外的妥当性の確認に使う三層設計です。
モデル選定と中間表現の抽出戦略
比較対象モデルの役割分担
脳アラインメント研究で使用するモデルは、役割を明確に分けることが重要です。
GPT-2は既存研究との比較軸として不可欠です。fMRI・ECoG・行動データを用いた多数の先行研究がGPT-2を基準にしており、新しい研究もこれとの対比なしには評価できません。
AWD-LSTMとTransformer-XLは「再帰型 vs 注意型」という構造的な差を検証するための比較対象です。再帰型は情報ボトルネックを通じた圧縮を行い、Transformer-XLはセグメント再帰による長距離依存を実装しています。これらと脳の比較は、「脳はどちらの戦略に近いか」を問う仮説4に直結します。
**Llama 3.1(128Kトークン)**は高性能オープンモデルとして、Qwen2.5(128Kトークン、日本語対応)は日本語刺激を使う場合の主力候補として位置づけられます。
GPT-4.1のような大規模クローズドモデルは、中間層の表現を直接抽出できないため、surprisalの参照や要約生成の補助に限定するのが現実的です。
中間表現の効率的な抽出
7〜8Bクラスのオープンモデルでも、128Kトークン全体の全層hidden stateを保存しようとすると、ストレージと計算コストが非現実的になる可能性があります。実務的には、各単語のオンセットに対応するトークンのhidden state、およびsurprisal・entropy・rank entropyを一次的に保存し、必要に応じてhead別のattentionを追加する設計が堅実です。
fMRI用にはHRF(血流動態応答関数)で畳み込む前のword-aligned feature、MEG・EEG用には25〜50msごとのlagged feature matrixを別途生成することも重要です。
解析パイプラインと統計戦略
一次指標としてのEncoding Model
主解析指標はcross-validated encoding modelによる予測相関(Pearson相関、CC_norm)が最も標準的です。各ボクセルや電極について、モデルの中間表現から脳活動を予測する線形回帰を組み、クロスバリデーションで汎化性能を評価します。
補助的には**RSA(表現類似性解析)**で表現幾何の一致を、zero-shot decodingで「未見語への一般化」を検証します。特にzero-shot decoding(Goldstein et al. 2024でIFGを用いて示された)は、単なる回帰フィットとは異なり、表現空間そのものの対応を問う強力な証拠になります。
ランダム化介入による因果識別
因果識別の核心は、ランダム化された文脈介入です。同一の刺激(upcoming segment)を固定したまま、モデルへの入力文脈だけをランダムに変えることで、局所的な語彙・音響・内容の影響を排除できます。
さらに人間側でもintactとscramble条件をランダム割付することで、difference-in-differences(DiD)設計が可能になります。「長窓の効果はintactなコンテキストでのみ現れ、シャッフル条件では消える」というパターンが見られれば、仮説3の強力な支持になります。
多重比較補正はfMRIではROI事前登録+Benjamini–HochbergのFDR、探索解析ではpermutationベースのcluster correctionを基本とします。
まとめ――長文脈研究の核心は「長さ」ではなく「機構」にある
本記事で整理した研究動向の結論を端的に言えば、**「long contextが脳らしさを高める条件の切り分け」**こそが今の研究フロンティアです。
文脈を使うモデルが静的モデルより脳に近いことは確立されつつあります。しかし「何トークン使うか」よりも「どのように遠距離文脈を圧縮・統合・予測に変換するか」の方が本質的である可能性が高まっています。特に、脳が段落規模の再帰的・階層的統合を行うという知見は、フラットな超長窓よりも要約メモリや再帰的圧縮の方が脳に近い可能性を示唆しています。
次の研究の一手として最も合理的なのは、既存の公開fMRI・ECoGデータでコンテキスト切り詰め・要約メモリ・シャッフル条件の再解析を先に実施し、最も感度の高い指標と脳領域を特定してから、新規コホートのfMRI+MEG計測に進むという二段階アプローチです。単純な「長さ至上主義」から離れ、機構の因果的な識別へと研究の焦点を移すことが、AIと脳の本質的な類似性と相違性を解明する鍵になるでしょう。
コメント