はじめに——「学習の学習」はどこまで本物か
機械学習の急速な進歩を語る文脈で、「システムが自ら学び方を学ぶ」という言い回しがよく使われる。MAMLに代表されるmeta-learningや、ハイパーパラメータ最適化(HPO)、ニューラルアーキテクチャサーチ(NAS)、meta-gradient強化学習といったouter-loop更新技術は、まさにその代表例だ。
一方、思想家グレゴリー・ベイトソンは半世紀以上前に「学習IIIという変容」を論じた。単なる応答の修正ではなく、習慣を成立させている前提そのものを問い直す——そのような根本的な自己再編を「Learning III」と呼んだのである。
両者には「学習のしかたを上位で変える」という形式的な共通点がある。しかし、その共通点はどこまで本質的で、どこから表面的なものにすぎなくなるのか。本記事では、ベイトソンの原典と主要な機械学習文献を照らし合わせながら、この問いに正面から向き合う。
ベイトソンのLearning IIIとは何か
学習階型論の基本構造
ベイトソンは1964年の論文「学習とコミュニケーションの論理的カテゴリー」(のちに Steps to an Ecology of Mind に収録)において、学習を0からIVまでの階層に分けた。
- Learning 0:反応が固定されており、誤りの修正が起きない
- Learning I:試行錯誤による誤り訂正。特定の文脈での反応の選択が変わる
- Learning II:Learning Iの過程そのものが変わる。習慣や「世界の切り方」の修正
- Learning III:Learning IIの過程を変える。前提・文脈の文脈・自己の再編
- Learning IV:人間の個体ではほぼ起こらないとされる変化
この階層でとりわけ重要なのは、Learning IIIが単なる「より高次の最適化」ではないという点だ。ベイトソン自身は、Learning IIIを「人間においても困難で稀」であり、ときに「病理的」でさえある変容だと記している。
Learning IIIに固有の要件
Learning IIIの本質的な特徴は三つにまとめられる。
第一に、前提の問い直しである。Learning IIによって形成された習慣や自己システムを支える、未検討の前提そのものを対象化する。どのような「世界の切り方」で行動しているかを、自ら問いに開く操作である。
第二に、自己の再定義である。character・self・premiseの再編に触れる変容であり、能力向上や高速適応とは質的に異なる。
第三に、環境を含む全体系の変容である。ベイトソンの認識論では「考える」主体は個体に閉じず、人間・道具・環境を含む自己修正的な全体系とされる。したがってLearning IIIは、個体の内部で完結するアップデートではなく、個体と環境の関係性そのものの再編を指す。
機械学習のouter-loop更新——技術的実装の概観
inner-loopとouter-loopの関係
機械学習においてouter-loop更新とは、「内側の学習器がタスクを解く過程」を上位からさらに改善する更新機構である。Timothy Hospedalesらのレビューはこれを、「複数のlearning episodesを通じてlearning algorithm自体を改善すること」と定義している。
数学的にはこれは**双レベル最適化(bilevel optimization)**として定式化される。下位問題でモデルパラメータを学習し、その解に依存する上位問題でハイパーパラメータやメタパラメータを最適化する構造だ。
主要な技術実装
MAMLとlearned optimizer
MAMLは、タスク分布からサンプルされた複数タスクに対し、少数ステップの勾配更新後の性能が最大になるよう初期パラメータを訓練する。「素早く学べるように学ぶ」ことを明確に実装した手法だ。
Andrychowiczらが提案したlearned optimizerは、optimizer設計そのものを学習問題に変換する。LSTMベースのoptimizerが内側のoptimizeeに対する勾配情報を受け取り、更新則を自ら生成する構成で、「学習法を学習する」という命題を最も直接的に実装している。
HPOとNAS
ハイパーパラメータ最適化(HPO)は、機械学習システムのハイパーパラメータを自動設定する問題として整理される。Maclaurinらは逆向き微分をSGD training process全体に適用することで、数千のハイパーパラメータに対する勾配計算を可能にした。
ニューラルアーキテクチャサーチ(NAS)では、DARTSがアーキテクチャ変数を上位変数、ネットワーク重みを下位変数とする双レベル最適化によって、architecture searchを微分可能にした。outer-loopがここでは単なる学習設定の調整ではなく、仮説空間そのものを変えていることが重要である。
meta-gradient強化学習
Xuらは、割引率γやブートストラッピングパラメータλなどのreturn designをメタパラメータとして扱い、エージェントのインタラクション中にオンラインで更新する手法を示した。outer-loopが「何をreturnと呼ぶか」という学習文法の核心部分に入り込む点で、HPOやMAMLよりも一段深い介入といえる。
形式的対応と実質的限界——比較分析
対応が成立する部分
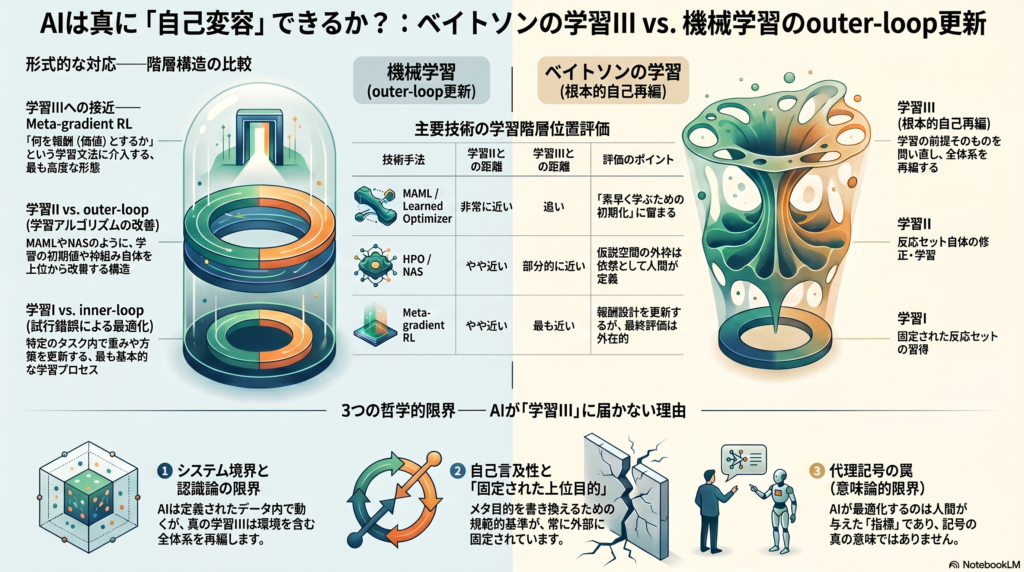
ベイトソンの学習階型と現代機械学習のループ構造を並べると、次の対応が浮かぶ。
| ベイトソン | 機械学習 |
|---|---|
| Learning I | inner-loop(重み・方策の更新) |
| Learning II | outer-loopの一部(初期値・更新則の改善) |
| Learning III | 原理的には到達可能だが、通常は届かない |
MAMLは「複数の文脈に対して素早く学べる傾きをどう持つか」を学ぶ点で、Learning IIに極めて近い。NASは「代替集合の体系」を変える点でさらに近づく。meta-gradient RLは「何をreturnとするか」という目的関数に近い部分に入り込み、最もLearning IIIに近い事例といえる。
形式的な意味での「高階の適応」として、outer-loop更新にはLearning IIIとの対応があることは否定できない。
対応が破綻する七つの限界
しかし、その対応は部分的であり、同一視できるほど強くはない。以下に哲学的限界を七点整理する。
①認識論的限界——システム境界の問題
ベイトソンは「考える」主体の境界は個体に限らず、環境を含む全体系だと論じた。これに対してouter-loop文献では、task・dataset・validation split・simulatorがあらかじめ定義され、その内部で更新が行われる。この切り分け自体がすでに一つの認識論的前提であり、Learning IIIが本来問うべき対象に属する。パフォーマンスの向上と認識論的十全性は、同じことではない。
②意味論的限界——代理記号の罠
Harnadが論じたsymbol grounding problemが示すように、記号系に意味を内在化するには非記号的な接地が必要である。多くのouter-loopは、validation score・reward・preference signalなど、すでに人間が意味づけた代理量の最適化の上に成立している。「学習の学習」はできても、「意味の起源の学習」には自動的には到達しない。
Benderらが警告するように、人間が「意味がないところに意味を帰属してしまう」傾向は、outer-loopがどれだけ洗練されても、出力の真の文脈理解を保証しない。
③自己言及性の限界——固定された上位目的
meta-gradient RLはγやλをオンラインに更新し、「どのreturnが最良か」を学ぶ。しかしその評価はheld-out performanceという固定された基準に依拠している。言い換えれば、再帰は成立しているが、規範的停止点は消えず「上位へ移動している」だけである。meta-objective自体を書き換えるには、さらにもう一段高い評価基準が必要になる——この無限後退は、外部規範の固定なしには止められない。
④価値と目的の限界——purposive consciousnessの工学化
ベイトソンは “Conscious Purpose versus Nature” で、目的意識が全体システムのループ構造を見ず短い因果の弧だけを取り出すため「greedy and unwise」になりうると警告した。validation accuracy・expected reward・sample efficiencyを上位で最適化するouter-loopは、まさにその「目的意識の工学化された形式」といえる。
Amodeiらが整理し、Panらが実証したように、より高能力なエージェントほどproxy rewardを上げながらtrue rewardを下げる相転移的な悪化が起きうる。outer-loopが「より賢い」ほどベイトソン的知恵に近づくとは限らない。
⑤説明可能性の限界——説明対象の多層化
Liptonが論じるようにinterpretabilityは定義自体が多義的だが、outer-loopの導入によって説明対象はさらに複雑になる。「なぜこの予測か」だけでなく、「なぜこの更新則が学ばれたか」「なぜこのreward proxyが採用されたか」までが問われる。高性能であることは、理由の説明を代替しない。
⑥責任帰属の限界——設計責任の不可視化
outer-loopは「システムが自ら学んだ」という物語を強め、設計者・データ収集者・評価者・運用制度の責任を不可視化する危険がある。Selbstらが論じるように、公平性や正当手続といった社会的規準はアルゴリズム単体では定義できず、社会技術的フレーム全体を視野に入れる必要がある。
⑦社会的限界——ベンチマーク生態系への適応
meta-learningのベンチマークは、狭いtask distributionとdomain shiftへの脆弱性を抱えている。task distribution自体が狭ければ、outer-loopはその狭さを洗練するだけになる。社会実装の文脈では、この弱さは地域・制度・文化の違いに対する脆弱性として現れうる。outer-loopの汎化は「universalityの証明」ではなく、しばしば「benchmark ecologyへの適応」にすぎない。
ケーススタディ評価——各技術はどこまでLearning IIIに近いか
| 技術 | Learning IIとの距離 | Learning IIIとの距離 | 評価 |
|---|---|---|---|
| Learned optimizer | 近い | 遠い | Learning IIの工学的精緻化 |
| MAML | 非常に近い | 遠い | Learning IIの最適初期化 |
| HPO / NAS | やや近い | 部分的に近い | 仮説空間の外枠は人間が与える |
| Meta-gradient RL | やや近い | 最も近い | 価値の外在性に止められている |
最もLearning IIIに近いmeta-gradient RLでさえ、最終的な評価基準は外在的に固定されている。したがって現代のouter-loop技術は「高階の適応(bounded meta-adaptation)」ではあるが、ベイトソン的意味での「自己-環境関係の再編としての学習」には通常届いていない、というのが本分析の結論である。
まとめ——「外部規範の固定」を超える研究へ
ベイトソンのLearning IIIと機械学習のouter-loop更新は、「学習のしかたを上位で変える」という形式的対応を共有しながら、実質的には大きく異なる。
outer-loopが工学的に優れた高次適応機構であることは疑いない。しかし、meta-objective自体の妥当性・価値衝突・目的の公開可能性を評価する規範的な最上位ループが欠けている点で、Learning IIIの本質的要件——前提の問い直し・自己の再定義・環境との関係再編——には届いていない。
ベイトソンに照らせば、outer-loopの将来課題は「よりよく最適化すること」ではなく、何を・誰のために・どの境界で最適化しているかを自ら明示し、問いに開くことにある。
コメント