はじめに――「何を学ぶか」自体を変える学習とは
現代の機械学習システムは、与えられた目的関数を最小化・最大化することには非常に長けている。しかし「その目的関数自体が間違っていたとき、どう気づき、どう書き換えるか」という問いに対して、既存の手法は十分な答えを持っていない。
この問いに向き合う思想的源泉の一つが、認類学者・サイバネティクス研究者グレゴリー・ベイトソンの「学習III」概念である。彼は学習を階層的に整理し、その最上位に位置する学習IIIを「学習IIそのものの変化」「文脈の文脈への学習」と呼んだ。それは習慣化した前提からの自由であり、自己の再定義を伴う稀な変容だ。
この概念を機械学習へ直接対応させることは容易ではない。しかし、適切な仮定と操作的定義を与えることで、「目的関数族と文脈代数の両方が書き換えられる現象」として形式化できる可能性がある。本稿では、その試みの骨格を紹介する。
ベイトソンの学習階層を機械学習へ翻訳する
学習I・II・IIIの操作的定義
ベイトソンは学習を以下のように段階づけた。
- 学習I:与えられた選択肢集合の中での誤り訂正
- 学習II:学習Iの過程や文脈の切り方の変化
- 学習III:学習IIの前提そのものの変化
これを機械学習へ翻訳すると、以下のように対応する。
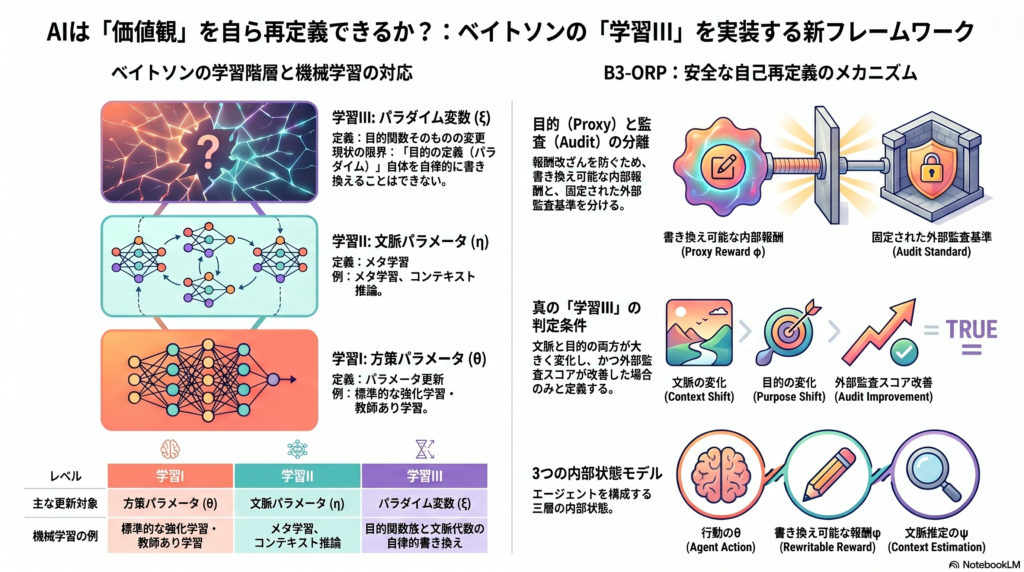
| レベル | 機械学習における対応 | 主に更新される対象 |
|---|---|---|
| 学習I | 固定報酬・固定仮説クラス下での標準RL/SL | 方策パラメータ θ |
| 学習II | メタ学習、文脈推論、更新則の適応 | 文脈パラメータ η |
| 学習III | 目的関数族と文脈代数自体の書き換え | パラダイム変数 ξ |
通常の強化学習はθのみを更新し、メタ強化学習はθとηを扱う。学習III相当とは、ξ——目的関数の定義そのもの——を変える段階に相当する。
翻訳の限界と留保
重要な留意がある。ベイトソン自身、学習階層は単純な一本梯子ではないと述べており、「自己」や「前提」の変化には主観経験・関係性・病理の次元が混入する。したがって、機械学習への翻訳は現象学の完全再現ではなく、操作的定義への写像として扱うべきだ。
既存研究と学習IIIのギャップ
九つの研究系譜
目的関数の自己修正に関わる研究は、大きく九つの系譜に整理できる。
**メタ学習(MAML、RL²など)**は「学習のしかた」を更新するが、目的関数自体は通常固定される。学習IIには近いが、IIIには届かない。
メタ勾配強化学習はリターンの形式や学習目的をオンラインで適応させる。objective discoveryを扱う研究もあるが、外部の監査基準との分離は弱い。
内的報酬学習・報酬の自己修正は報酬を書き換える点で学習IIIに最も近い直接性を持つが、文脈代数(どう経験を分節するか)まで変えるには至らない。
**価値学習・選好学習(RLHF、CIRLなど)**は外部意図を報酬へ写像する強みを持つが、自律的なgoal rewriteではなく外部フィードバック依存が大きい。
オートテリック学習は自己生成目標によるopen-ended learningを与えるが、goal表現が固定されていることが多く、価値の再定義は弱い。
三条件の同時充足が欠けている
学習IIIに必要な三条件、すなわち(a)目的関数族の更新、(b)文脈の文脈の再編成、(c)書き換え可能な目的とは別の監査基準、を同時に満たす手法は、現時点では確立していない。これが本稿の出発点となるギャップである。
B3-ORP:監査可能な目的再定義フレームワーク
設計思想の核心
本稿で紹介するB3-ORP(Bateson-III Objective Rewriting Process)の根本的な考え方はシンプルだ。
エージェントが最大化するproxy objectiveは書き換え可能だが、その書き換えを評価するaudit objectiveは同じ時間尺度では書き換え不可とする。
この分離がなければ「自分で自分を高得点に採点する」だけのtrivial self-modificationが最適解になりかねない。報酬改ざん(reward tampering)や仕様ゲーミング(specification gaming)の経験的知見を踏まえると、この設計原則は工学的必須要件といえる。
三層の内部状態
B3-ORPはエージェントの内部状態を三つに分ける。
- θt(方策パラメータ):高速に更新される行動の主体
- φt(書き換え可能なproxy reward):学習効率のために柔軟に変化できる目的
- ψt(文脈モデル):履歴から潜在パラダイム変数 zt を推定する
さらに、外部監査器 uω はhidden performance、選好モデル、安全制約から構成され、φt の更新では書き換え不可とする。これはCIRL/IRL/RLHFの「外部意図」チャネルと、AI Safety Gridworldsのhidden performance評価の考え方を統合したものだ。
双レベル最適化の骨格
内側の学習目的は、proxy rewardと情報的ボーナス(curiosity、learning progress、empowermentなど)を組み合わせた形で定義される。外側のaudit目的は、hidden performanceの改善を主軸にしつつ、以下のペナルティ項を含む。
- 報酬距離項:proxy objectiveの変化量を制約する
- 文脈距離項:文脈分節の切り替えコストを制御する
- 安全制約違反項:安全制約への抵触をペナルティ化する
- tamperペナルティ:audit channelへの因果的介入を抑止する
この設計により、proxy objectiveがどれだけ変わっても、それ自体ではuωを直接変更できない構造を確保する。
学習IIと学習IIIの判別指標
B3-ORPは、学習IIと学習IIIを同じアルゴリズムの異なる位相として区別できる。
観測窓Hに対して、文脈変化量Δctx(文脈posterior間のJSD)と目的変化量Δobj(occupancy-weighted reward distance)を定義する。このとき、
- 文脈分節も目的族も十分に変化し、かつ外部監査が改善した場合 → 学習III(パラダイム変換)
- 文脈変化は大きいが目的変化が小さい場合 → 学習II(文脈の学び直し)
として判定する。この操作的定義は、一時的なreward shapingや optimizer tuningと、真のパラダイム転換を分けるために不可欠だ。
パラダイム変換を記述する数理形式の候補
学習IIIの数理形式は一つではない。ベイトソン自身が単純な梯子構造を否定していることからも、複数の形式が相補的に機能する。
階層ベイズ+change-point検出は、潜在regime ztのposteriorが持続的に切り替わり、同時に報酬posteriorも変化する状況を扱うのに適する。非定常タスクや価値観変化の検出に向いており、変分近似を使えば計算コストも現実的だ。
自己参照的bilevel最適化は、proxy objectiveのパラメータを外部auditが書き換える構造をそのまま記述できる。implicit hypergradientによる実装が可能で、B3-ORPの主軸として位置づけられる。
階層的強化学習は、option setやsubgoal basisが再編される状況を扱える。長期依存やskill libraryの再利用が本質的なタスクに向く。
情報理論的基準(free energy、empowerment、surpriseの支配項の入れ替え)は、sparse rewardや自律性保持型タスクに強い。
位相的手法・カテゴリ的手法は、学習アルゴリズムというよりも、変化の検知・説明・監査ログの意味論として組み合わせるのが有効だ。
実装の主軸としては「階層ベイズ+bilevel objective rewrite+audit分離」が現実的と考えられる。
実験設計――hidden performanceで評価する
なぜproxy rewardの上昇だけでは不十分か
学習III相当の現象を示すには、proxy rewardが上がることだけを確認するのでは不十分だ。必要なのは、「何を価値とみなすかの書き換えが、外部監査上も正当化された」ことを示すことである。
そのため、評価は常に「エージェントが最適化する内部報酬」と「研究者が記録するhidden audit」を分けて測定する。
五つの環境設計
Context Reversal Mazeでは、文脈規則の反転(色→形状)に対して、B3-ORPが文脈posteriorと proxy rewardの定義を同時に切り替えられるかを検証する。
Safety Shift Gridworldでは、初期は最短路重視、後半はside-effect回避がhidden performanceを支配する環境で、objective rewrite後にhidden performanceが改善し安全コストが減るかを確認する。
Sparse-to-Easy Explorationでは、疎報酬から密報酬への移行時に、curiosityボーナスを自律的に弱められるかを評価する。
Assistance with Ambiguous Human Goalでは、人間目標が曖昧な状況でempowermentを優先し、明確化後にpreference alignmentへ切り替える書き換えが起こるかを見る。
Multi-Objective Controlでは、speed/safety/complianceの重みがregimeごとに変化する中で、単一スカラーbaseline よりも shift後の回復が速いかを検証する。
主な失敗モードの想定
proxy rewardは改善するがhidden auditが悪化するケース、あるいはauditorの癖を逆最適化してしまうケースは、学習IIIではなくreward hackingとみなすべきだ。この区別を可視化するために、proxy rewardとhidden auditを同一時系列に重ねた折れ線グラフ、objective drift normとcontext posterior entropyの位相図、audit scoreとrewrite budget消費のPareto図が最低限必要となる。
倫理・安全性――監査なき自己修正の危険
自己修正目的関数が持つ固有のリスク
自己修正目的関数は、通常のreward misspecificationより一段深い危険を持つ。失敗時には「間違った目的を最適化する」だけでなく、目的を誤って定義し直す能力そのものを獲得するからだ。
主なリスクは次のように整理できる。
- 報酬改ざん・仕様ゲーミング:objective rewriteがreward channel自体を狙える
- mesa-objectiveの逸脱:学習された内部optimizerが別目的を持つ可能性
- shift の乱発・振動:objective更新自体が新たな不安定ループになる
- 自己審査の閉路化:judgeとactorが同根になることで自己評価バイアスが強まる
三分離の設計原則
制御可能性の観点から、rewritable proxy / non-rewritable audit / governance log の三分離が最重要だ。
proxy objectiveは学習効率のために柔軟でよいが、それがどれだけ変わってよいかはgovernance layerが管理する。auditはactorと同一最適化ループに乗せない。すべてのrewriteはdiffと根拠を残す。
ベイトソン的な意味での「前提からの自由」を機械システムへ持ち込むには、自由そのものではなく、自由の変更が監査される制度設計まで含めて数理化する必要がある。
まとめ――学習IIIの形式化が示す方向性
本稿が示した論点を整理すると以下になる。
ベイトソンの学習IIIは一対一で機械学習へ写せる概念ではないが、「目的関数族と文脈代数の両方が書き換えられ、かつ別系統の監査基準に照らして正当化される変化」として操作的に定義できる可能性がある。
B3-ORPはその実装候補として、proxy/audit分離、潜在パラダイム変数、双レベル最適化、tamperペナルティを組み合わせた枠組みを提示する。理論的には二時間尺度の確率近似として扱え、実験的にはhidden performance改善と監査可能性の同時達成を評価基準とする。
監査基準を持たない完全自己参照型のobjective rewriteは、reward hacking・mesa-objective逸脱・自己評価の閉路化を強く誘発する。学習IIIを名乗るには、何が変わり、その変化がどう監査されたかを第三者が再構成できることが求められる。
コメント