はじめに:なぜ「抽象語」の神経基盤が重要なのか
「りんご」という言葉を聞いたとき、多くの人は赤い実の色や甘い香りを思い浮かべるかもしれません。しかし「自由」や「正義」という言葉を聞いたとき、脳は何を手がかりに意味を構築しているのでしょうか。
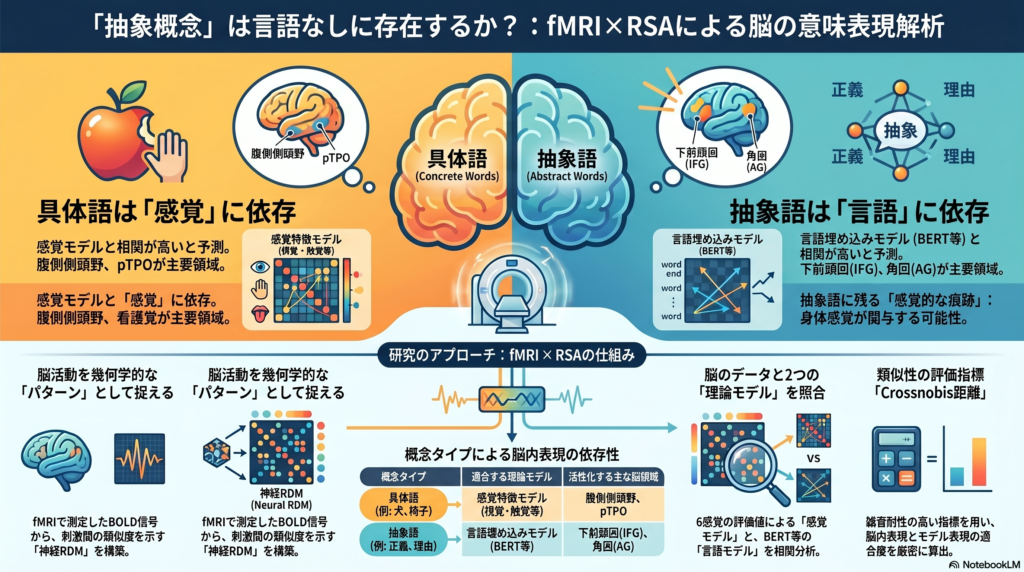
具体語は感覚・運動システムとの結びつきによって意味が構成されるという「身体化認知(Embodied Cognition)」の観点は広く支持されています。一方で抽象概念については、感覚経験だけでは説明が難しく、言語システム――すなわち他の語彙との関係性や文脈――が意味の骨格を形成する可能性が有力視されています。
この問いに答えるため、近年注目されているのが**fMRI(機能的磁気共鳴画像法)とRSA(表現類似性分析)**を組み合わせたアプローチです。本記事では、抽象概念の言語依存性をターゲットにした研究設計の全体像を解説するとともに、使用されるモデルや統計手法、期待される知見について詳しく掘り下げます。
fMRI × RSAとは何か——研究アプローチの基礎知識
fMRIで「意味処理」を可視化する
fMRIは、神経活動に伴う血流変化(BOLD信号)を測定することで脳の活動パターンを非侵襲的に記録できるツールです。言語研究においては、単語や文を提示したときにどの脳領域が活性化するかを調べるだけでなく、**活動パターンの形(マルチボクセルパターン)**を使って「脳がどのように情報を表現しているか」を解読することが可能になっています。
単純な「活性化・非活性化」の二値的分析から、パターンそのものの幾何学的構造を分析するアプローチへ——この転換を象徴するのがRSAです。
RSA(表現類似性分析)の仕組み
RSAは、2つの「表現構造」を比較する手法です。
まず脳側では、N種類の刺激に対するマルチボクセルパターンを取得し、刺激同士の類似度(または距離)を行列として整理します。これを**神経RDM(Representational Dissimilarity Matrix)**と呼びます。
次にモデル側では、理論的な仮定に基づいてモデルRDMを構築します。たとえば「word2vecで近い語は脳でも類似した活動パターンを示すはず」という仮説であれば、word2vecのベクトル間のコサイン距離でモデルRDMを作成します。
最後に、神経RDMとモデルRDMの相関(主にSpearman相関)を算出することで、「どのモデルが脳の表現構造をより良く説明するか」を評価します。
この枠組みによって、感覚特徴モデルvs言語埋め込みモデルのどちらが、具体語・抽象語それぞれの脳表現をより良く説明するかを直接検定することが可能になります。
研究の中心仮説——語彙タイプとモデルの交互作用
本研究の核心は、次の交互作用仮説にあります。
- 具体語では、「感覚特徴モデル(6感覚次元の評定値)」の説明力が相対的に高い
- 抽象語では、「言語埋め込みモデル(BERT・word2vecなど)」の説明力が相対的に高い
これは「具体語の意味は感覚経験に依存し、抽象語の意味は言語システムに依存する」という理論的予測を神経表現レベルで検証しようとするものです。
ただし、研究上の重要な留保点として、抽象語であっても感覚的な痕跡が残る可能性も同時に検討します。たとえば「自由」は身体的な解放感と結びついている可能性があり、完全に感覚から切り離されているとは言い切れません。
先行研究では、具体語vs抽象語の神経的な差異として、**下前頭回(IFG)と後部側頭頭頂後頭野(pTPO)**での処理の違いが報告されており、言語-視覚境界において両種類の情報が統合されている可能性も示されています。本研究はそれをRSAを用いてより精緻に検証しようとするものです。
語彙の選定と刺激統制——日本語データを用いた設計
なぜ日本語なのか
本研究が日本語を主言語として採用するのは、これまでの概念表現研究の多くが英語圏のデータに基づいていることへの問題意識からです。英語と日本語では語彙の抽象度カテゴリが一致しない場合があり、汎言語的な知見の妥当性を検証するためにも日本語データの蓄積は重要です。
また、日本語の公開fMRIデータは現状では乏しいため、自前での被験者収集を主軸に据えています。
H3:語彙選定の基準
語彙は大きく60語条件と120語条件の2種が想定されます。
具体語の例としては「りんご」「犬」「椅子」のような、視覚的・触覚的にイメージしやすい語が選ばれます。抽象語の例としては「自由」「正義」「理由」のような、感覚的イメージに直接結びつきにくい語が選ばれます。
語彙選定の際には以下の心理言語学的属性をマッチングさせることで交絡を防ぎます。
- 語頻度(NTT親密度データベースなどを参照)
- 心像性(頭の中でイメージしやすいか)
- 語の長さ(モーラ数)
- 習得年齢(AoA)
- 具象性・抽象性評定
これらが両群で統計的に均等になるよう慎重に選定することで、「具体語か抽象語か」以外の変数が結果に影響しないよう設計します。
また、語義の曖昧性(ポリセミー)は大きな潜在的交絡因子です。たとえば「光」という語は具体的でもあり比喩的・抽象的な使われ方もするため、語義ラベル付きの評定調査によって刺激の質を事前に確認する予定です。
使用するモデル群——脳表現との比較対象
言語埋め込みモデル
脳のRDMと比較するモデルRDMの素材として、複数の言語モデルが採用されます。
word2vec / fastTextは、大規模コーパスから統計的に学習された静的な単語ベクトルです。「似た文脈に現れる語は近いベクトルを持つ」という分布仮説に基づいており、語の意味的類似性をある程度反映します。これらはPCAで次元圧縮したうえでモデルRDMとして使用します。
Japanese BERT / mBERTは、Transformerアーキテクチャに基づく文脈化言語モデルです。同じ語でも出現文脈によって異なるベクトルが生成されるため、多義語の表現に柔軟に対応できます。実験では語を「これは[語]です」というテンプレートに埋め込み、最終4層の平均ベクトルを取得・PCA後にモデルRDMを構成します。
感覚特徴モデル
感覚特徴は、**6感覚(視覚・聴覚・触覚・嗅覚・味覚・運動感覚)**の評定値によって構成されます。これは「りんご」であれば赤い視覚的特徴や甘い味覚が高い値を取り、「正義」であれば全般的に低い値になることが予想されます。
必要に応じてBinder et al.の感覚・運動・情動の多次元特徴量システムへの拡張も検討されます。
実験デザインとfMRI前処理
イベント関連デザインと反復計測
実験はイベント関連デザインで実施され、各語は最低3回以上提示されます。これにより、単一試行レベルでのβ推定(single-trial beta estimation)が可能になり、RSAに必要な試行ごとの脳活動パターンを得ることができます。
fMRIデータの前処理パイプライン
前処理には標準的なfMRIPrep(BIDSに準拠した前処理パイプライン)を採用し、非アグレッシブなICA-AROMAによる運動・生理ノイズの除去を行います。このアプローチは空間的滑らかさを保ちつつ、ノイズ除去の精度を高めるとされています。
その後、単一試行β推定によって各語・各試行の多ボクセルパターンを算出し、RSAの入力とします。
ROI(関心領域)とSearchlight分析
ROI分析では、先行研究で言語・概念処理との関連が指摘されている4領域に焦点を当てます。
- IFG(下前頭回):語彙・統語処理、抽象概念の処理で報告あり
- AG(角回):意味統合、抽象語との関連が指摘される
- pTPO(後部側頭頭頂後頭野):具体語と抽象語の境界処理
- 腹側側頭野(ventral temporal):物体認識・具体語処理に関与
Searchlight分析では、半径3ボクセルの球形領域を脳全体で移動させながらRSA値を算出し、脳全体での空間的なマッピングを行います。これにより、ROIで見逃す可能性のある領域を見つけることができます。
統計設計——厳密な推論のための多層的アプローチ
RSAの距離指標と相関指標
神経RDMの算出にはcrossnobis距離が使用されます。これは交差検証に基づく雑音耐性の高い手法で、多ボクセルパターンの類似度をバイアスなく推定できます。
モデルRDMとの比較にはSpearman順位相関を基本とし、カテゴリ型の補助仮説検定にはKendall τaを用います。
統計的推論の手順
統計的推論は以下の流れで行います。
- 被験者内置換検定(1万回):各被験者ごとにランダムラベルシャッフルで帰無分布を構成し、RSA値の有意性を評価
- 群レベル検定:Sign-flip検定またはPermutation検定で群全体の効果を推定
- 多重比較補正:ROI分析ではFDR(偽発見率)q < .05、Searchlightでは空間的クラスタリングを考慮したTFCE-FWE(Family-Wise Error)補正を適用
主検定モデルは線形混合モデル形式で設定されます。
RSA ~ 語彙タイプ × モデル + (1|被験者)語彙タイプ(具体語/抽象語)とモデル種(感覚特徴/言語埋め込み)の交互作用項が主要な関心です。補助的に、群ベイズモデル選択も実施し、頻度論的検定と収束する場合に知見の信頼性が高まることを確認します。
期待される結果と解釈上の留意点
予測パターン
本研究で期待される主結果は以下のとおりです。
- 具体語:感覚特徴モデルとのRSA相関が言語モデルより高い(とくに腹側側頭野・pTPOで)
- 抽象語:言語埋め込みモデル(BERTなど)とのRSA相関が感覚特徴モデルより高い(とくにIFG・AGで)
- 抽象語の感覚的痕跡:感覚特徴モデルでも一定の説明力が残る可能性(完全分離ではない)
この結果パターンは「二重符号化理論(Dual Coding Theory)」的な観点とも整合しており、抽象概念であっても感覚モダリティと無縁ではないという見解と相補的な位置づけになります。
主要な方法論的課題
研究を進める上での主な課題として以下が挙げられます。
語義曖昧性:同一の語が複数の意味を持つ場合(例:「光」)、提示条件によって被験者の解釈が異なる可能性があります。これは語義ラベル付き評定調査によって事前確認します。
語頻度・親密度の共変量問題:たとえば低頻度の具体語と高頻度の抽象語を比較すると、純粋な具体性/抽象性の効果を測定できません。選定段階での徹底したマッチングと、分析段階での共変量投入で対処します。
日本語言語資源の不足:英語と比べ、日本語の規範データや公開fMRIデータは限られています。自前収集を主軸とし、英語・中国語などの他言語データを用いた再現確認を補助的に実施することで外的妥当性を担保します。
計算資源:BERT系モデルのファインチューニング等にはGPU 1枚程度、RSA・前処理にはCPU 32〜64コア・RAM 128GB程度が目安として想定されます。
まとめ:抽象概念の神経基盤研究が切り開く地平
本記事では、抽象概念の言語依存性を検証するfMRI × RSA研究の設計を詳しく解説しました。
中心仮説は「具体語では感覚特徴モデル、抽象語では言語埋め込みモデルの説明力が相対的に高い」というものであり、これを検証するためにROI分析とSearchlight RSAを組み合わせ、語彙タイプ×モデルの交互作用を統計的に検定します。
日本語データを主軸に据え、word2vec・fastText・Japanese BERT・mBERTと感覚特徴モデルを比較対象として、厳密な刺激統制と多層的な統計推論によって「言語なしに抽象概念は存在しうるか」という根本的な問いへの一つの答えを目指します。
この研究が将来的に明らかにする知見は、言語・認知・神経科学の境界領域に新たな視座をもたらすだけでなく、自然言語処理における意味表現モデルの改善にも貢献する可能性があります。
コメント