身体性AIが注目される理由:「物理世界に対応する知能」という根本的な問い
大規模言語モデルの普及が加速する一方で、ロボットや仮想エージェントが「物理世界で自律的に行動する」ための知能設計は、依然として未解決の課題が山積している。日本の科学技術政策においても「生成AIの急速な発展に対し、実環境・物理世界での社会実装は十分でない」という認識が明示されており、ロボティクスとAIの融合、すなわち”身体性の付与”が戦略的課題として位置づけられている。
この文脈で再注目されているのが、フランスの哲学者モーリス・メルロ=ポンティの身体論だ。彼の主著『知覚の現象学』が示す「知覚の先行性」「身体図式」「運動的志向性」といった概念は、現代の身体性AI(Embodied AI)研究に対して、単なる思想的背景にとどまらず、設計原則としての実践的示唆を与えうる。
本記事では、メルロ=ポンティ身体論の主要概念を整理したうえで、現代の身体性AI研究の実装動向を概観し、「人工主観性(artificial subjectivity)」を工学的にモデル化する2つの設計アーキテクチャを紹介する。さらに、倫理・ガバナンスの視点と今後の研究展望についても触れる。
メルロ=ポンティ身体論の核心:AIに問いかける4つの概念
「知覚の先行性」——表象より行為が先にある
メルロ=ポンティは「世界は私が思うものではなく、私が生きとおすものである」という定式で知られるように、世界理解は論理的推論や内的表象の構築に先立って、知覚と行為の場で成立すると論じた。これは身体性AI設計への重要な示唆を含む。「表象を構築してから行動する」という従来型のAIアーキテクチャへの批判的問いかけとして読めるからだ。
センサ情報を解析して内部モデルを構築し、そのモデルをもとに行動計画を生成するという「認識→計画→実行」の流れは、直感的に合理的に見える。しかし現実の物理環境では、変化の速さ・不確実性・接触の複雑さにより、この逐次処理は容易に破綻する。知覚と行動を分離せず、「行動を含む知覚」そのものを中心に据えることが、現象学的観点から求められる設計の方向性となる。
「I can」としての運動的志向性——「できる」が意識の基底にある
メルロ=ポンティは意識の基底を「I think(私は考える)」ではなく「I can(私はできる)」に見出した。これは命題的・言語的表象を意識の中心に置く主知主義を批判し、環境への働きかけ可能性(アフォーダンスとの接続)を知覚の組織原理として位置づけるものだ。
ロボット研究における「身体性が最重要」という経験則——たとえば「画像だけでは把持に必要な情報が得られない」という現場知——は、まさにこの「I can」の論点と工学的に接続する。視覚は単独で完結する感覚ではなく、運動の一変種として機能するという理解は、VLA(Vision-Language-Action)モデルの設計において言語層と運動層の明確な分離を要請する理論的根拠にもなりうる。
「身体図式」——前反省的な行為可能性の体系
身体図式とは、身体の空間的位置を座標として表象する枠組みではなく、状況に応じて姿勢や運動可能性が前反省的に組織される体系として論じられる。これは「状況的空間性」と呼ばれ、「対象的空間性(固定座標系)」とは根本的に異なる。
ロボット工学への含意として重要なのは、身体図式が「工具の使用」や「身体の変化」に応じて動的に更新される点だ。義手を使う人が、やがてその義手を自己身体として感じるようになる現象は、身体図式の可塑性を示す典型例として引かれる。これをロボットに適用すれば、アームの交換・センサの欠損・工具の装着といった身体変化に適応する自己モデルの設計が求められることになる。
「完全な現象学的還元の不可能性」——方法の自己修正を求める態度
メルロ=ポンティはフッサール的な現象学的還元(エポケー)を継承しつつも、「完全な現象学的還元は不可能である」と明言した。身体がすでに世界に関与しているという事実は、自然的態度を全面的に括弧に入れることを不可能にする。
これをAI研究方法として捉え直すと、内部状態の完全な”説明”を追求するより、学習の歴史・環境依存性・失敗と回復のプロセスといった「現象」を記述するログ設計を重視すべきという示唆が得られる。評価指標をタスク成功率に一元化せず、過程の多層的記述を制度化する研究姿勢が求められる。
身体性AIの現状:基盤モデル化と実環境実装の加速
シミュレーション環境によるベンチマーク整備
Habitat(Facebookが開発したナビゲーションベンチマーク)やBEHAVIOR-1Kに代表されるシミュレーション環境では、「未知の環境でコードを提出して評価する」という汎化重視の評価体制が整備されつつある。BEHAVIOR-1Kは1,000種の日常行為タスクを定義し、長時間・多物体操作を含む複雑なシナリオでの評価を可能にしている。ただし現実の物理接触を含む作業には別設計が必要であり、シミュレーションと実環境のギャップ(sim-to-real gap)は依然として主要な課題だ。
実機ロボットへの基盤モデル統合
Google DeepMindが開発したRT-1は、13台のロボット・13万エピソード以上・700種以上のタスクという大規模データで学習した模倣学習型の基盤モデルだ。その後継となるRT-2は、Webスケールの視覚言語モデルとロボットデータを共同ファインチューニングすることで、概念知識をロボット行動へ転移するVLA(Vision-Language-Action)のアーキテクチャを提示した。RoboCatは異なるロボット経験を統合し、自己生成データによる反復的改善(自己改善ループ)という方向性を示している。
また、拡散モデルを方策表現に用いるDiffusion Policyは、行動分布の多峰性(同じ観測に対して複数の合理的行動が存在する状況)を扱える生成モデルとして注目されている。
触覚・マルチモーダル統合の潮流
接触リッチな作業において視覚情報だけでは不足するという認識が高まり、触覚センサと言語・視覚を統合するTactile-Language-Action(TLA)系の研究が台頭している。これはメルロ=ポンティが論じた「触る/触られる」という相互性、すなわち触覚の独自性に対応する工学的取り組みとして位置づけられる可能性がある。
日本国内では、理化学研究所AIPや産業技術総合研究所(産総研)による研究基盤整備が進み、産総研のRoboManipBaselinesのように「比較・再現性」を前面化したフレームワーク構築も重要な動きだ。
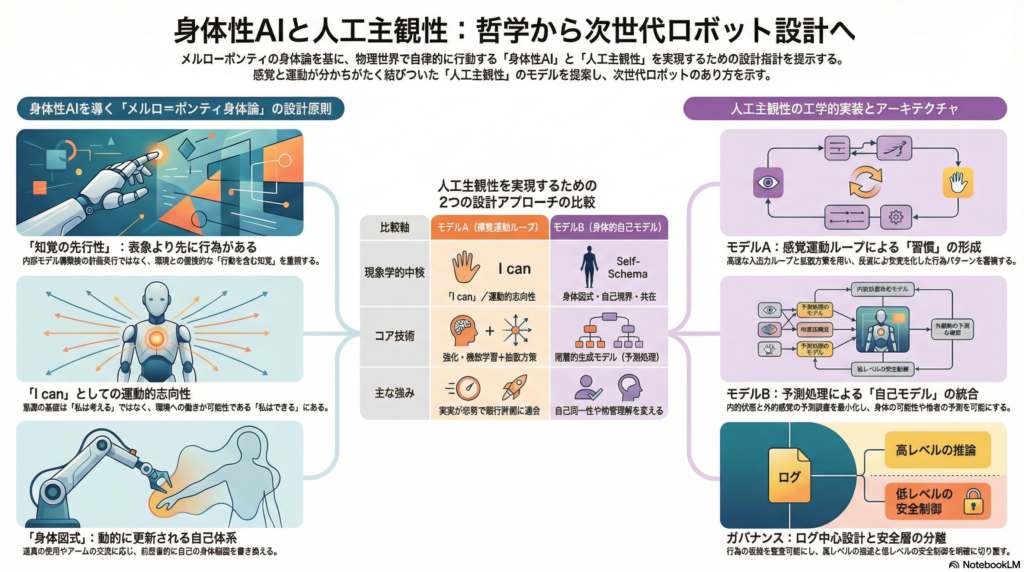
人工主観性の2つのモデル:設計アーキテクチャの比較
「人工主観性」の研究は、クオリアや現象的意識のハードプロブレムを「解決した」と主張するものではない。むしろ、現象学が強調する構成条件——「I can」としての行為可能性、身体図式による自己境界の形成、他者との共在、学習史による差異化——を工学的に構成(construct)し、第三者が検証できる形で評価指標化する試みだ。
モデルA:感覚運動ループ重視モデル
現象学的中核:「I can」/運動的志向性を最小核に置く
モデルAは、主観性の最小核を「環境との閉ループ相互作用」に置く。観測→行為→環境変化→再観測という高速ループを基盤とし、このループ自体から意味や行為の組織化が立ち上がることを狙う設計思想だ。模倣学習や強化学習に加え、行動分布の多峰性を扱える拡散方策を採用可能な構成で、「習慣層」として反復で安定化した行為パターンをタスク横断で再利用できるライブラリを持つ。
評価は3層構造で行う。第一層はタスク成功率などの外的成功指標。第二層は外乱・未知配置への回復力(閉ループ頑健性)。第三層は「主観的効力プロキシ」として、意図した行為が環境にどの程度一貫して作用したかを可観測ログとして指標化する。
強みと限界: 実装の現実性が高く、既存のベンチマーク環境に適合しやすい反面、自己境界や他者性の表現が後付けになりがちという課題がある。
モデルB:身体的自己モデル重視モデル
現象学的中核:身体図式・自己境界・共在(他者性)を統合的に扱う
モデルBは、予測処理(predictive processing)やアクティブインフェレンス(active inference)を中心に据えた階層的生成モデルを核とする。外受容感覚(視覚等)・自己受容感覚・内受容感覚(バッテリー残量・温度などのロボット内部状態に相当するもの)を統合し、予測誤差の最小化を通じて学習と行為の両方を駆動する。
特徴的なのは「身体図式アップデータ」の存在だ。工具装着時や特定センサ欠損時の身体変化に適応し、「身体拡張」や「部分的欠損」にも対応できる可塑的な自己モデルを維持する。さらに「自己/他者モデル」として、他者の行為を自己モデルで予測し、視点獲得や模倣学習へ接続する機構を持つ。これは発達ロボティクスの知見と親和性が高い。
評価指標には、タスク成功率・予測誤差の収束に加え、身体変化後の自己同定時間(身体図式適応指標)、行為→結果の因果的寄与の内部推定(エージェンシー指標)、共同注意・視点取得・協調行動(他者性指標)が含まれる。
強みと限界: 自己同一性・故障適応・他者理解を設計上明示的に扱える点で現象学的主観性に接近できるが、モデルの複雑さゆえに評価設計が難しく、過剰モデル化のリスクも抱える。
2モデルの比較まとめ
| 比較軸 | モデルA(感覚運動ループ) | モデルB(身体的自己モデル) |
|---|---|---|
| 現象学的中核 | I can/運動的志向性 | 身体図式・自己境界・共在 |
| コアアーキテクチャ | RL/IL+拡散方策+習慣ライブラリ | 階層生成モデル+自己他者モデル |
| 主な強み | 実装容易・ベンチマーク適合 | 自己同一性・適応・他者理解を扱える |
| 主な弱み | 他者性・自己境界が後付けになりやすい | 複雑で評価が難しい |
| 主要評価指標 | 成功率・頑健性・主観的効力プロキシ | 成功率・予測誤差・身体図式適応・他者性 |
哲学的課題:主観性の検証はなぜ難しいのか
人工主観性研究が直面する根本的困難は、第三者が観察可能なデータ(行動・ログ)と第一人称的経験(クオリアなど)のギャップだ。機能主義的アプローチは「外部から観察可能な機能」を中心に据えるため検証可能性は高いが、現象学的主題である「生きられた経験」が脱落しやすい。逆に現象学的厳密さを追求するほど検証が難しくなる。この二重拘束は人工主観性研究の構造的困難として認識しておく必要がある。
また、メルロ=ポンティが論じた他者性の問題も重要だ。彼は「共存は両者の側で生きられなければならない」という条件を提示した。これをAIに移すと、主観性を「単体エージェントの内部状態」として閉じるほど他者性がモデルから脱落する可能性がある。人間‐ロボット‐環境の三項関係に主観性の条件を分散させる立場では、「主観性の帰属先」が曖昧になるという別の問題も生じる。
倫理・ガバナンス:人工主観性が問い直す責任の所在
身体性AIが家庭・医療・介護といった生活空間に実装されるにつれ、いくつかの倫理的問いが避けられなくなる。道徳的地位(苦痛や利益の担い手になりうるか)、責任帰属(事故時の責任は誰が負うか)、説明可能性(なぜその行為に至ったかを人間が理解できるか)、擬人化リスク(人格や依存関係の形成)の4点が主要な論点だ。
日本では、内閣府の「人間中心のAI社会原則」が透明性・説明責任・安全性・人間の尊厳といった規範軸を提供しており、経済産業省・総務省の「AI事業者ガイドライン」は提供者・利用者の責務として情報提供・安全配慮を具体的に要求している。EUのAI Actは高リスクAIへの義務を強化する方向で施行が進んでいるが、具体的な適用時期・運用は政治状況により変動しうるため、国際展開を想定する研究チームには継続的な情報収集が求められる。
設計レベルでの対応として、以下の3点が実践的なガバナンス原則として導出される。
ログ中心設計: 行為決定の根拠(知覚・推論・安全制約・エラー回復)を監査可能な形で保存し、説明可能性の最小条件とする。
安全層の明示的分離: 高レベルの推論・計画機能と、低レベルの安全制御(力制限・衝突回避)を明確に分離し、後者を独立して検証可能にする。
関係性リスク評価: 擬人化・依存・他者性の錯誤をHRI(ヒューマン・ロボット・インタラクション)指標で継続評価し、利用環境ごとに介入方針を策定する。
まとめ:「身体を加えれば知能が生まれる」という素朴な期待を超えて
メルロ=ポンティ身体論が身体性AIに与える問いかけは、「身体を加えれば知能が生まれる」という素朴な期待への批判的問いかけだ。知覚の先行性、I canとしての運動的志向性、身体図式の動態性、完全還元不可能性と方法の自己修正——これら4つの論点は、身体性AI設計において実質的な制約条件として機能しうる。
現在の身体性AI研究(基盤モデル×ロボット制御・触覚統合・ベンチマーク整備)は、メルロ=ポンティが批判した「世界を座標化し尽くせば理解したことになる」という客観主義の罠を再生産するリスクと背中合わせだ。一方で、大量ログ・安全層・シミュレーション・自律学習という工学的道具立ては、「身体‐世界の相互性」を手続きとして実装するための基盤ともなりうる。
今後の焦点は、人工主観性を単一指標に還元しない多層的評価体制の確立、自己モデル・他者モデル・安全制御の統合設計、そしてガバナンス要件(ログ・説明・リスク低減)を研究要件として内在化した研究体制の構築にある。
コメント