なぜ今、AIによる仮説生成が注目されるのか
科学研究や医療診断、法的推論において、「なぜそれが起こったのか」を合理的に説明する力は不可欠です。この「もっともらしい説明を導き出す推論」こそがアブダクション(仮説生成)であり、近年AIがこの領域を支援できるかどうかに世界的な注目が集まっています。
本記事では、アブダクションの定義と歴史から始まり、現在進行中の技術動向、実証評価の実態、人間とAIの役割分担、そして倫理・法的課題までを体系的に解説します。AIを活用した仮説推論の可能性と限界を正確に把握したい研究者・エンジニア・医療従事者の方に向けた内容です。
アブダクション(仮説生成)とは何か
演繹・帰納と何が違うのか
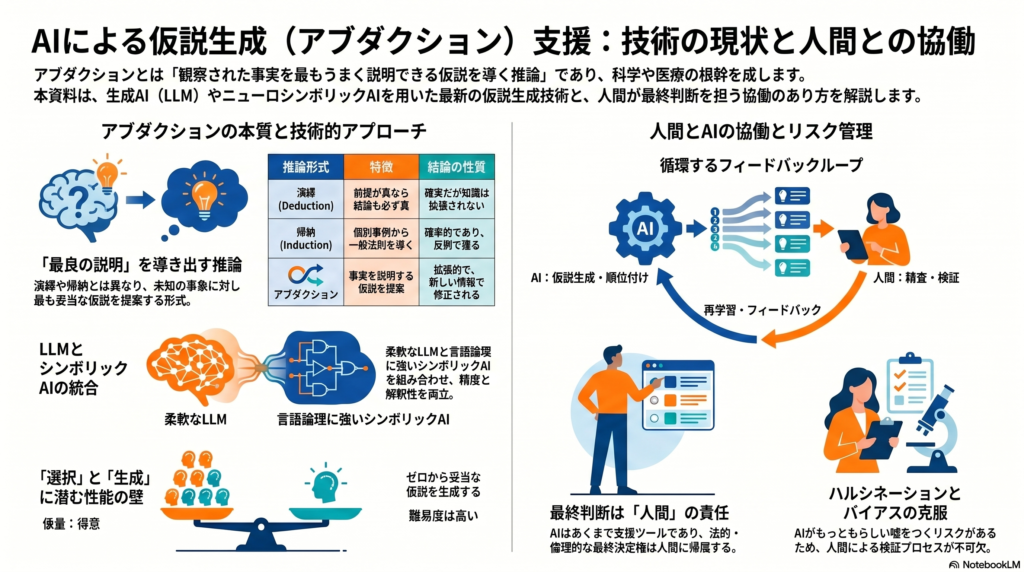
アブダクションは、19世紀の哲学者チャールズ・サンダース・パースが提唱した推論形式です。彼はこれを「最良の説明への推論(Inference to the Best Explanation)」と定義し、演繹や帰納とは本質的に区別しました。
三つの推論形式を簡単に整理すると次のようになります。
演繹は「前提が真ならば結論も必然的に真」となる論理的推論です。例えば「すべての金属は電気を通す、銅は金属である、したがって銅は電気を通す」というように、結論の確実性が保証されます。
帰納は個別の観察事例から一般的な法則を導く推論です。「これまでに観察した白鳥はすべて白かった、したがって白鳥は白い」という形式ですが、あくまで確率的な命題であり、後から反例が現れれば覆り得ます。
アブダクションはこれとは異なり、「観察された事実を最もうまく説明できる仮説を提案する」行為です。例えば「コンピュータにエラーが表示された」という観察に対し、「無線アクセスポイントが故障したのかもしれない」と仮説を生成するのがアブダクションの典型です。アブダクションは「拡張的(ampliative)」かつ「非単調的(non-monotonic)」な性質を持ち、新たな情報によって仮説は修正・撤回される可能性を常に含んでいます。
因果推論・説明可能性(XAI)との関係
アブダクションは因果推論とも深く関連しています。「症状の原因となった病気は何か」を推定する診断的推論は、アブダクションの一形態と捉えることができます。また、AIの説明可能性(XAI)の文脈でも、アブダクション能力を備えたAIは「なぜその判断をしたのか」を人間に納得感のある形で提示できる点が期待されています。現行のXAIの多くは「どの特徴量が寄与したか(帰属)」を示すに留まり、真の「なぜ」に答えられていないという批判もあり、アブダクションを軸にした次世代XAIへの期待が高まっています。
現在の技術動向:主要アーキテクチャと代表的システム
大規模言語モデル(LLM)による生成型アプローチ
現在の仮説生成AIの主流は、GPTシリーズやLlama、Qwenなどの大規模言語モデル(LLM)を活用した生成型アプローチです。これらは大量のテキストデータから自然言語の仮説を柔軟に生成できる一方、「ハルシネーション(幻覚)」と呼ばれる誤情報を生成するリスクが課題として残ります。
LLMの強みは「大量の知識を柔軟に適用する汎化力」にありますが、推論の内部プロセスがブラックボックス化しやすく、なぜその仮説が生成されたかを説明することが困難な場合があります。
因果モデル・ベイズモデルとの統合
確率的因果モデルやベイズネットワークは、アブダクション推論の基盤技術として以前から研究されてきました。不確実性の定量化が得意であり、医療診断などの確率的因果推論が重要な領域で活用されています。近年はこれらの手法と深層生成モデルを組み合わせる研究が進んでおり、精度と解釈性を両立させるアプローチが模索されています。
ニューロシンボリックAI(シンボリック統合)の可能性
注目を集めているのが、LLMとシンボリック推論を融合させたニューロシンボリックAIです。代表的な研究としてLiangらのNeSTRモデルがあります。このシステムは時系列データをまず論理記号として表現し、その上でLLMに逐次的に推論させることでアブダクションを実現しています。
シンボリックAIは「明示的な論理式による高い説明性」を持ちますが、静的なルールに縛られる柔軟性の低さという弱点があります。一方LLMは柔軟ですが不透明です。この二つを組み合わせることで、正確性と適応性を同時に実現しようとするのがニューロシンボリックアプローチの本質です。
代表的な実装システム
**化学仮説生成AI(JSTムーンショット)**は、研究者と対話しながら候補化合物を提案するシステムです。研究論文をベクトル化した基盤モデルや、研究者の意図に沿った分子生成を軸とし、チャットボット形式で仮説探索を支援しています。
**DiagramNet(医療XAI)**は心雑音診断において、アブダクションに基づき診断仮説を選択し、臨床的に意味のある図式的説明を提示するシステムです。医学生を対象としたユーザー評価において、従来の機械学習可視化手法よりも信頼性・理解度が高く評価されたと報告されています。
**NeSTR(時系列QA)**は、質問や文脈から時間情報を論理記号として抽出し、LLMへ入力して推論・検証を行う手法です。シンボリック表現による矛盾チェックとLLMの多段アブダクションを組み合わせ、正確かつ解釈可能な回答の実現を目指しています。
実証的評価:ベンチマークが示す現状と限界
評価指標と主要ベンチマーク
仮説生成AIの性能は主に正答率(Accuracy)やF1スコアなどの定量指標で評価されます。代表的なベンチマークとしては以下のものがあります。
Abductive NLI(αNLI)・ARTは日常的なストーリーから最適な説明を選ぶタスクです。DDXPlusは医療文書から鑑別診断を生成する高難度タスクで、Top-Kヒット率やSet-F1が指標として使われます。AbductionRulesは論理法則の補完問題、UNcommonsenseは候補説明の相対的優劣を競うWin Rateで評価されます。
大規模モデルが示す性能格差
最新のLLM(GPT-5世代相当)は、形式化されたルール補完タスク(AbductionRulesなど)でほぼ100%に近い精度を達成することも報告されています。これはモデル内部に膨大なルール知識が蓄積されていることを示唆しています。
一方、複雑な常識推論や医療系タスクでは性能が大きく落ちる傾向があります。医療診断の生成タスク(DDXPlus)ではSet-F1が約60%台、常識説明タスク(UNcommonsense)ではWin Rateが約60%台に留まったとする報告があります。
もう一つ重要な性能ギャップが「選択式 vs. 生成式」の差です。与えられた候補から正解を選ぶ選択式タスクは相対的に容易ですが、仮説を自由に生成する生成式タスクでは性能が著しく低下します。この「Stage I(選択)とStage II(生成)のギャップ」は、現行モデルの本質的な限界として指摘されています。
静的ベンチマークの限界
既存の評価基盤にも課題があります。現行の静的・単発ベンチマークは、実際の仮説推論に必要な「複数ステップの検証」や「人間との対話的な仮説更新」を十分に反映できていません。真のアブダクション能力を測るには、複合的・対話的な評価設計が不可欠であると研究者たちは指摘しています。
人間とAIの役割分担:協働ワークフローの設計
理想的な役割分担とは
AIと人間が協働する仮説探索のワークフローは、おおむね次のような流れで設計されます。
まず研究者や医師が観察データや課題を提示します(問題定義・データ提示)。次にAIが知識ベースや文献データから初期仮説候補を複数生成し(仮説生成)、妥当性や一貫性に基づいてランク付けを行います(仮説選択・順位付け)。その後、人間が上位の仮説を精査・検証し(評価・実験)、その結果をAIにフィードバックして再提案を促します(フィードバックループ)。
このプロセスにおいて、AIは「データ処理・迅速な仮説探索」を担い、人間は「最終的な意思決定・倫理的判断・創造的な洞察の補完」を担うという分担が基本となります。
認知負荷軽減と過信のトレードオフ
生成AIが情報過多や不確実性の高い状況で人間の認知負荷を軽減し、ヒューリスティックなバイアスを減らす効果があることは、いくつかの研究で示されています。一方で、AIへの過度な依存や「AIが出した仮説にはクリエイティブな飛躍が少ない」という課題も同時に報告されています。
したがって、AIの判断を透明化する仕組み——すなわち、「なぜその仮説を生成したのか」を可視化する説明可能性(XAI)機構——の整備が、健全な人間–AI協働の前提となります。
信頼性と説明責任の枠組み
医療分野を例に取ると、米国FDAはAIを「診断支援機器(SaMD)」と位置付け、最終的な診断責任は医師に帰属するという枠組みを採用しています。EUや日本においても、AIはあくまで支援ツールとして位置付け、人間による最終検証を求めるガイドラインが整備されつつあります。
信頼関係の構築には、AIの説明の分かりやすさと継続的なキャリブレーション(CHAI-Tフレームワークなど)が鍵であるとされています。チェーン・オブ・ソート(Chain-of-Thought)による段階的な説明提供や、「なぜ?」に対する回答をサポートするインターフェース設計が有効なアプローチとして検討されています。
倫理・法的・社会的課題
ハルシネーションとバイアスの問題
生成AIの最大のリスクの一つが、もっともらしいが誤った情報を生成する「ハルシネーション」です。仮説生成においてこのリスクは特に深刻であり、誤った仮説が検証なく採用されれば、研究の方向性や医療判断に重大な影響を及ぼす可能性があります。人間による検証・承認プロセスの義務化が不可欠です。
また、学習データの偏りによるバイアスも見過ごせません。特定の属性に対して偏った仮説ばかりが生成されるリスクは、医療・法務の分野では取り返しのつかない結果につながりかねません。FAT(Fairness, Accountability, Transparency)の原則に基づいたデータ品質管理とモデル評価が求められます。
プライバシー保護と法制度
医療データや個人情報を含む学習データの取り扱いには、日本の個人情報保護法やEU GDPRに基づく厳格な規制が適用されます。データの匿名化や同意取得はもちろん、近年では連合学習(各機関が生データを共有せずにモデルを協調学習させる技術)や差分プライバシーといった先進的なプライバシー保護技術の導入も進んでいます。
責任帰属については法制度の整備がまだ追いついていない部分も多く、誰がAIの誤判断に法的責任を負うかという問題は、今後の重要な議題です。
AIへの依存文化への懸念
仮説生成AIが研究や医療で広く活用されれば、意思決定のスピード向上という恩恵がある一方、「AIの仮説に依存する文化」が根付くリスクもあります。教育現場ではAI依存を防ぐ学習設計が、法務では「AI生成提案はあくまで参考情報」という規範がそれぞれ模索されています。
まとめ:AIと人間が「なぜ」を共に解き明かす時代へ
AIによる仮説生成(アブダクション)支援は、大規模言語モデルの発展とともに急速に進化しています。しかし、形式的なルール補完タスクでは高い精度を示す一方で、複雑な医療推論や常識的な説明生成では依然として大きな課題が残っています。静的ベンチマークによる評価の限界、選択式と生成式の性能ギャップ、ハルシネーションやバイアスのリスクは、現実の応用展開における重要な障壁です。
人間とAIの理想的な関係は、AIが定量的なデータ処理と初期仮説の提案を担い、人間が最終判断・倫理確認・創造的洞察を補完する協働モデルにあります。その実現には、推論過程を可視化する説明可能性技術の充実と、透明性・責任所在を明確にした法制度の整備が欠かせません。
コメント