なぜいまポスト構造主義とLLMを接続するのか
大規模言語モデル(LLM)が日常的な道具になった現在、「モデルは本当に意味を理解しているのか」という問いはますます切実になっている。しかしこの問いは、工学的な性能指標だけでは答えられない。意味とは何か、記号はどのように機能するのか——こうした問いに正面から向き合った哲学者こそ、ジャック・デリダである。
本記事では、デリダの中心概念「差延(différance)」を手がかりに、LLMの確率的トークン生成の構造を読み解く。哲学と機械学習という一見無縁の領域を接続することで見えてくるのは、「意味は完成品として与えられるのではなく、差異と遅延の運動のなかで暫定的に生成される」という共通の構造だ。この視点は、生成AIの倫理・誤情報・責任論を考えるための新しい言語を提供する。
デリダの「差延」とは何か——定義と二重運動
差延は「語でも概念でもない」
デリダが「差延(différance)」を独立したテーマとして前面に出したのは、1968年に行った「La Différance」と題する講演である。この概念の特異な点は、フランス語の「différence(差異)」のeをaに変えた「différance」という造語にある。この異綴(いてい)は、発音上は区別がつかず、文字でしか現れない。デリダはこの事実そのものを、声の現前に優位を置く西洋哲学の伝統——「音声中心主義」——への批判として機能させる。
デリダ自身は差延を「語でも概念でもない」と定義する。これは単なる修辞ではない。差延とは、意味が自己完結した単位として成立するのではなく、他との差異の連鎖のなかでのみ暫定的に現れるという、意味作用そのものの構造を指している。
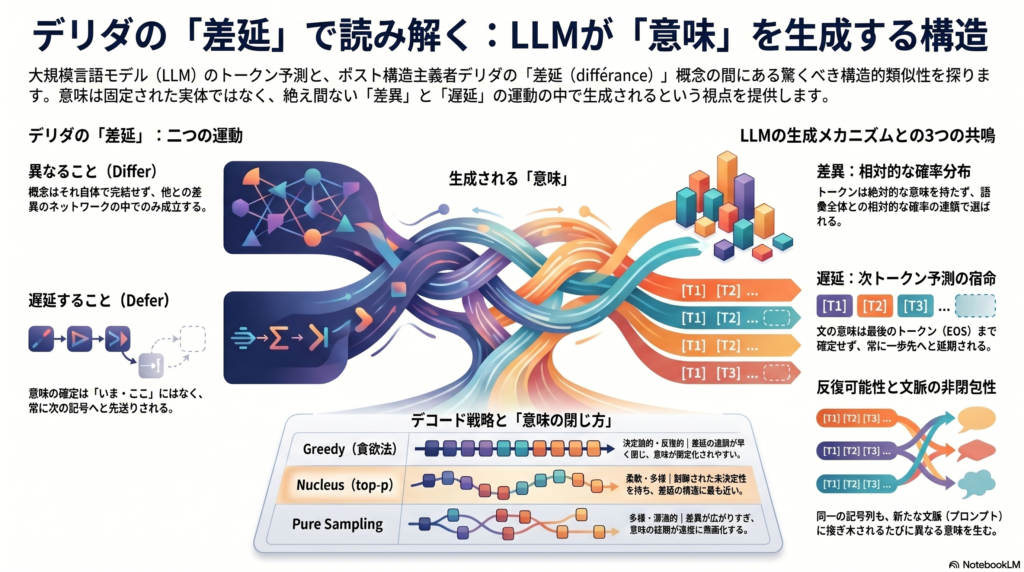
「異なること」と「延期すること」の二重運動
差延の核心は、フランス語の動詞「différer」が持つ二つの意味にある。
第一は「to differ(異なること)」。概念はそれ自体で完結せず、他の概念との差異の体系のなかでのみ位置づけられる。「犬」という語が意味を持つのは、「猫」「狼」「狐」と区別されるからであり、犬という概念に本来的な実体があるからではない。
第二は「to defer(延期すること)」。意味の決定は常に先送りされる。記号は「失われた現前」を代理するものとして機能してきたが、デリダはこの「最終的な意味の回収」という図式そのものを疑う。意味は一度も「いま・ここ」に完全に現前しない。この時間的な先送りをデリダは「temporization(時間化)」と呼ぶ。
この二重運動——差異化と遅延——の複合こそが「差延」であり、意味の静的な目録ではなく、意味作用の動的な運動を記述する概念である。
反復可能性と文脈の非閉包
差延と密接に結びつく概念として「反復可能性(iterability)」がある。デリダは「Signature, Event, Context」(1971年)において、記号は送り手や受け手が不在であっても機能しなければならないと論じた。署名が書かれた手の現前なしに読めるように、記号は不在のなかで反復可能でなければならず、その反復可能性こそが記号の同一性を構成する。
さらに重要なのは、この反復が純粋な同一性の繰り返しではないという点だ。同一の記号列が別の文脈に置かれるたびに、異なる意味効果を生む。これをデリダは「いかなる文脈もそれを囲い込めない」と表現する。記号は元の文脈から切り離され、別の連鎖へと接ぎ木(グレフ)されうる——この構造が「文脈の非閉包性」である。
LLMの生成機構——トークンから意味へ
自己回帰的な次トークン予測
LLMの基本形式は「自己回帰的言語モデル」である。入力された系列を受け取り、次に来る最も確率の高いトークンを一つずつ選び続けることで文章を生成する。数式的には、系列全体の確率を条件付き確率の積に分解し、各時点で「これまでの文脈が与えられたとき、次のトークンはどれか」を予測する構造になっている。
GPT-3やLlama 3といった代表的なモデルは、いずれもこの自己回帰的デコードを採用する高密度Transformerである。つまりLLMは「意味」を直接出力するのではなく、局所的な文脈に最も整合的なトークンを逐次選び続ける装置として機能する。
トークン化という意味の分割
自己回帰を可能にする前提として、テキストは「トークン」と呼ばれる単位に分割される。GPT系で使われるBPE(Byte Pair Encoding)、多言語対応のSentencePieceなど、各モデルには固有のトークン化方式がある。
重要なのは、この分割が語彙論的に自然な「単語」とは一致しないことだ。日本語を含む多言語テキストでは、モデルの「意味の単位」は慣れ親しんだ語の区切りではなく、訓練済みの部分語(subword)規則が切り出した可変長の記号断片である。LLMが扱う「記号」は、最初から人間の語彙単位とずれたところに存在している。
Transformerの注意機構とデコード制御
Transformerの中心にある自己注意(self-attention)機構は、文中のあらゆる位置間の関係を並列に計算することを可能にする。デコーダ側では、各トークンが未来の位置を参照しないようマスキングされることで、自己回帰性が保証される。
生成の最終段階では、モデルが出す「ロジット(各トークンへの未正規化スコア)」をどう読むかが、意味の現れ方を大きく左右する。主要なデコード戦略を整理すると以下のようになる。
| デコード戦略 | 動作 | 生成の性格 |
|---|---|---|
| Greedy(貪欲法) | 毎回top-1を選択 | 決定論的・反復しやすい |
| Beam Search | 複数仮説を保持して探索 | 高確率系列への収束・反復傾向あり |
| Temperature Sampling | 温度で分布を調整してサンプリング | 低温→収束、高温→多様化 |
| Top-k Sampling | 上位k候補に限定 | 固定幅の選択肢 |
| Nucleus Sampling(top-p) | 累積確率質量で候補を動的調整 | 文脈に応じた柔軟な選択 |
Holtzmanらの研究は、特に長文の開放型生成においてlikelihood最大化(greedy・beam)が反復的で単調な出力を生みやすく、nucleus samplingが多様性と可読性のバランスに優れると報告している。
差延とLLM——構造的アナロジーの四軸
第一軸:差異——意味は関係の効果として現れる
デリダが「概念はそれ自体で十分に現前せず、他との差異の連鎖のなかでのみ成立する」と述べるとき、彼は意味を自己完結した実体ではなく、差異的ネットワークの効果として捉えている。
LLMにおいても、あるトークンは単独で意味を持つのではなく、語彙全体との相対的な確率分布のなかで位置づけられる。次のトークンとして「犬」が選ばれるのは、「犬」が絶対的な意味を持つからではなく、その時点の文脈において「猫」「人」「鳥」といった他の候補より相対的に高い確率が割り当てられたからだ。意味の担い手は単語ではなく、差異的配列である——この点で両者の構造は強く対応する。
第二軸:遅延——文意は常に一歩先送りされる
LLMにおける文意の確定は、最後のトークンが生成されるまで完了しない。一語目でも二語目でも、文全体の意味は決まらない。各トークンはそれまでの文脈を受け取りながら、後続部分を予期させるだけで、文意の決定は次の選択へと延期される。
デリダが差延の本質として強調した「temporization(時間化)」、すなわち意味決定の先送り——この動きは、自己回帰的トークン生成の構造のもっとも鋭い哲学的記述として読める。EOSトークン(文の終端記号)は実装上の停止であって、意味論的な終止点ではない。生成後のテキストは、引用・再プロンプト・読解によって常に再文脈化に開かれている。
第三軸:反復可能性——同一列の再文脈化による意味の差異化
デリダの反復可能性概念は、LLMにおいて直感的に観察できる。同一のトークン列(プロンプト断片)は、異なるシステムプロンプト・異なるサンプリング設定・異なる後続文脈に接ぎ木されるたびに、同一でありながら同一でない意味効果を生む。トークン列は自己同一的な意味核としてではなく、反復のたびに差異化される再使用可能な記号として機能する。
この構造は、デリダが記号の同一性をその反復可能性に——しかも送り手・受け手の不在を含む反復可能性に——置いたことと深く共鳴する。
第四軸:文脈の非閉包性——生成後も意味は開かれている
デリダは「いかなる文脈もそれを囲い込めない」と主張した。これはLLM出力にも当てはまる。一度生成されたテキストは、生成時の局所文脈では一旦「閉じた」ように見えても、引用・再プロンプト・別の読者による解釈によって容易に再文脈化される。LLMの出力が誤情報や多義的解釈の温床になりうるのは、まさにこの文脈の非閉包性によると言えるだろう。
アナロジーの限界——哲学と工学の断絶
このアナロジーには重要な限界がある。最大のリスクは、差延を「確率的ゆらぎ」へと還元してしまうことだ。
デリダの差延は、西洋形而上学の現前中心主義への批判という広い哲学的布置に属する。エクリチュール、痕跡、他者性、署名の問題を含む、きわめて複雑な操作である。これに対してLLMは、Transformerによって系列確率を最適化する工学的システムであり、その目標は次トークン予測の成功であって、真理条件や意味理解そのものではない。
「temperatureを上げることが差延だ」という短絡は誤りである。適切な言い方は、「temperatureが高いほど差延的な未決定性が表面化しやすくなる」であり、差延はランダム性の別名ではなく、差異と遅延からなる意味作用の構造だ。
また、LLMには形而上学批判の自己理解がない。モデルは「意味世界」を内在的に持つのではなく、系列尤度を最適化するなかで意味らしい整合性を実現しているにすぎない。この差は消せない。
実証的な観察——デコード条件と意味の閉じ方
公開されたGPT-2の生成例(同一プロンプト「I enjoy walking with my cute dog」)を見ると、デコード戦略の違いが意味の現れ方を大きく変えることがわかる。
Greedy / Beam Search: 高確率の局所パターンに落ち着くため、同型の節が繰り返されやすい。差延の連鎖が早く閉じ、意味が反復によって擬似固定化される状態と見ることができる。
Pure Sampling: 差異の候補集合を広く残しすぎるため、意味の延期が過度に表面化し、話題が予測外の方向へ漂流しやすい。
Nucleus Sampling(top-p): 各時点の確率質量に応じて候補集合を動的に伸縮させる。差延の「際限ない散種」ではなく、「制御された未決定性」を実現する点で、差延の構造に最も忠実に近い操作と読める。
Wiherらが示すように、デコード戦略の効果はタスク依存でもある。翻訳のような出力長が予測しやすいタスクではbeam searchが有効でも、物語生成や対話では反復・単調化を引き起こしやすい。差延を「モデルが常に多義的である」と単純化するのではなく、「課題・プロンプト・デコーダ・停止規則の組み合わせが意味をどの程度開くか閉じるか」という設計可能なパラメータ空間として扱うべきだ。
生成AIの倫理と責任——差延が照らすもの
差延的な視点は、生成AIの倫理問題を新しい角度から照らす。
意味が差延的に揺れうること自体は哲学的に豊かな条件だが、プラットフォーム上で大量配信されるとき、その多義性は誤情報・もっともらしい虚偽・責任の分散という形で政治化される。問題は「意味が固定されない」ことそのものではなく、固定されない意味の流通を「誰が引き受けるか」という責任の問いだ。
記号が反復可能で文脈を超えて機能する限り、いかなる安全化ルールも完全な封じ込めにはなれない——これはデリダの文脈の非閉包性が示す論理的帰結である。これは安全化が不要だということを意味しない。むしろ安全化を「最終封印」ではなく「再文脈化リスクを減らす局所的な統治技術」として設計し直すことを要求している。
生成条件(デコード設定・プロンプト設計・サンプリング規則)のあり方も、出力内容と同等に倫理的問題として問われるべきだという含意は、LLM開発・運用の現場に向けた実践的な示唆でもある。
まとめ——差延はLLMを哲学的に読む最良のレンズのひとつ
デリダの差延は、LLMの確率的トークン生成を理解するための「洒落た比喩」ではない。意味が差異の体系のなかでのみ成立し、つねに遅延され、反復可能な記号として文脈を横断するという構造——これはLLMの自己回帰生成において工学的な形で露呈する。
同時に、この関係は「同一性」ではなく「生産的な緊張関係」として保持されるべきだ。LLMは差延の機械的実装ではない。しかし、差延はトークン生成における意味の遅延・流動性・反復可能性を読むための批判理論的レンズとして有効に機能する。
問うべきは「AIは意味を持つか」という旧い問いではなく、「意味はどこで閉じ、どこで延期され、どの条件で多義化し、その多義性を誰が引き受けるか」という問いだ。この問いの立て方そのものが、思想研究と生成AI評価を接続する新しい研究プログラムの出発点になる。
コメント