なぜ今、AIの「意味生成」を評価しなければならないのか
現代のAIシステム——大規模言語モデル(LLM)、画像生成モデル、ロボット制御エージェント——は、精度・流暢さ・汎用性において目覚ましい進歩を遂げている。しかし、GLUEやImageNetといった既存ベンチマークが主に「タスク達成率」を測る設計であるのに対し、AIが本当に「意味を理解している」かどうかを問う評価軸は、いまだ十分に整備されていない。
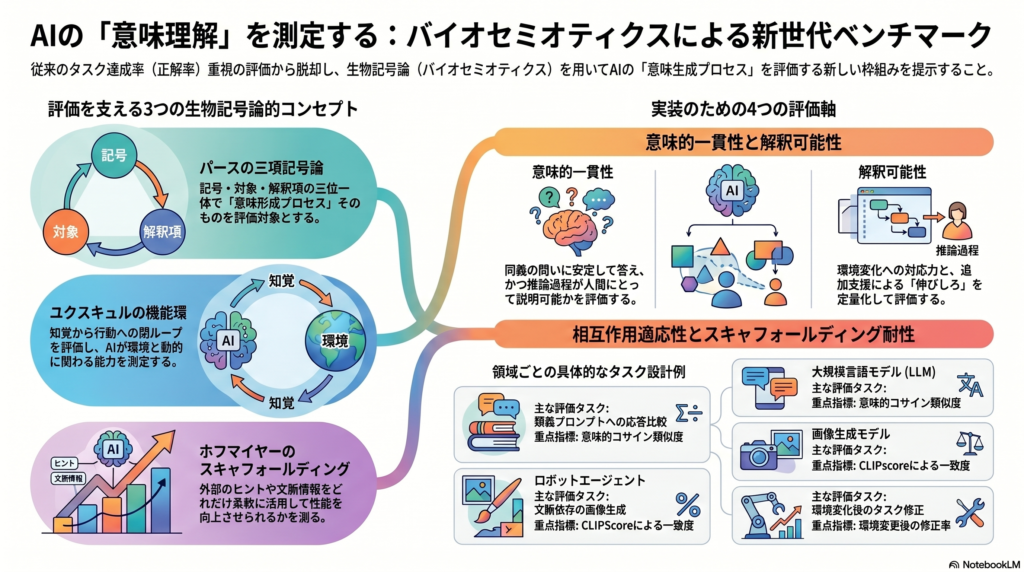
この問いに正面から向き合う枠組みとして注目されているのが、バイオセミオティクス(生物記号論) の概念体系をAI評価へ応用するアプローチである。パース(C.S. Peirce)の三項記号論、ユクスキュル(Jakob von Uexküll)の「機能環(Funktionskreis)」、ホフマイヤー(Jesper Hoffmeyer)らの「スキャフォールディング」——これら三つの概念を共通語彙として形式化し、LLM・画像モデル・ロボットに横断的に適用する評価プロトコルの標準化が提案されている。
本記事では、この新しいベンチマーク設計の理論的背景・評価軸・タスク設計・実装ロードマップを体系的に解説する。
バイオセミオティクスとは何か——三つの中核概念を理解する
パースの三項記号論——記号・対象・解釈項の関係
バイオセミオティクスの基礎となるのは、アメリカの哲学者チャールズ・サンダース・パースが提唱した三項記号(Triadic Sign) の枠組みである。
従来の記号論が「記号」と「指示対象(意味)」の二項関係に留まっていたのに対し、パースは「記号(Representamen)」「対象(Object)」「解釈項(Interpretant)」という三つの要素が不可分に結びついて初めて意味が生成されると論じた。
- 記号(Representamen):何かを表象するシンボルや信号
- 対象(Object):記号が指し示す実体や概念
- 解釈項(Interpretant):記号と対象の関係から主体の中に生まれる意味・効果
重要なのは、「解釈項」が単なる「読み手の解釈」ではなく、記号プロセスそのものによって生成される概念的効果だという点である。形式的には、解釈項 I は記号 S と対象 O の関数として表現でき、さらに解釈項が次の記号プロセスの出発点となる自己再帰的な構造(Iₙ = F(S, O, Iₙ₋₁))が想定される。
AIの評価にこの枠組みを適用すると、「モデルが生成した出力(記号)が、入力(対象)との関係においてどのような解釈項を生成しているか」を問えるようになる。単なる正解率ではなく、意味形成のプロセスそのものを評価対象にできる点が、この枠組みの核心的な意義である。
ユクスキュルの機能環——閉ループとしての意味生成
エストニア出身の生物学者ヤコプ・フォン・ユクスキュルが提唱した機能環(Funktionskreis) は、生物が環境と意味的に関わる仕組みを説明する概念である。
機能環の構造は以下の閉ループとして説明できる。
知覚 → 内的状態(意味付け)→ 行動 → 環境変化 → 再知覚
この閉回路により、生物は外界の刺激を単なる物理信号としてではなく、自らの「環世界(Umwelt)」に固有の意味として解釈する。有名な例として挙げられるのがマダニである——マダニは視覚をほぼ持たず、酪酸のにおいと温度という限られた知覚信号だけで宿主(哺乳類)を認識し、血を吸い、再び信号を感知するループを完成させる。その「世界」は人間のそれとは全く異なる意味構造を持つ。
AI評価における機能環の意義は、「入力→処理→出力」という一方向的なモデルに対し、フィードバックループとしての意味生成という視点を加える点にある。形式的には、状態遷移モデル(xₜ₊₁ = f(xₜ, aₜ))として表現でき、知覚情報と内部状態の組み合わせが行動を生み、その行動が環境を変え、新たな知覚へとつながる閉ループが構成される。
ロボットエージェントに機能環の評価を適用すれば、「センサー情報を受け取り→意味付けし→行動し→環境変化を再知覚する」というサイクルがどれだけ適切に機能しているかを定量化できる可能性がある。LLMに適用すれば、対話の文脈変化に応じて出力が適切に更新されるかどうかを、単一の応答品質ではなく動的な閉ループとして評価できる。
ホフマイヤーのスキャフォールディング——段階的意味制御の仕組み
バイオセミオティクスの第三の核心概念は、ヨアン・ホフマイヤーらが提唱したスキャフォールディング(Scaffolding) である。
生物システムにおけるスキャフォールディングとは、遺伝子コード(デジタル情報)と細胞・神経系によるアナログな解釈・行動をつなぐ、多層的な記号制御のネットワークを指す。この仕組みにより、生物は局所的な文脈情報や先行知識を参照しながら、段階的かつ柔軟な意味生成を実現している。ホフマイヤーの言葉を借りれば、「生物システムの目的志向的性質は解釈を誘導する半符号的制御のネットワークから生じ、そのネットワークがスキャフォールディングを形成する」。
AI評価においては、学習や推論の過程で外部からの補助情報(ヒント・マルチモーダル情報・文脈追加など)をどれだけ適切に活用できるかを測る概念としてスキャフォールディングを位置づける。たとえば、チャットボットに段階的に追加情報を与えていった際に性能がどの程度向上するか、その「伸びしろ」と「堅牢性」を「スキャフォールディング耐性」として定量化する。
バイオセミオティクス的AI評価の四つの評価軸
提案されたベンチマーク設計では、LLM・画像生成モデル・ロボットの三領域に共通適用できる四つの評価軸が定義されている。
評価軸①——意味的一貫性(Semantic Consistency)
同義語や類似した文脈での入力に対して、モデルの出力が意味的に整合しているかを評価する軸である。
LLMの場合、「犬とは何か?」と「いぬとは何か?」のように意味的に等価な質問に対し、生成されたテキストの意味的類似度(コサイン類似度など)を測定する。画像生成モデルの場合は、本質的に同じ内容を指す異なる指示文に対して生成された画像が意味的に一致するかどうかをCLIPscoreなどで評価する。
この指標の特徴は、「正解率」ではなく「一貫性」を問う点にある。モデルが常に同じ答えを出すだけでは不十分で、同じ意味の異なる表現に対して安定した意味応答を返せるかが問われる。
評価軸②——解釈可能性(Interpretability)
モデル内部の符号表現や推論過程が、人間にとってどれだけ説明可能かを評価する軸である。
生成テキストの論理的一貫性、概念クラスタの明瞭さ、アテンションマップの妥当性などが指標として活用される。外部評価者による可読性・整合性スコアや、概念頻度のランキングも補助指標として採用される。
この評価軸はパースの「解釈項」概念と直接対応しており、モデルがどのような意味付けのプロセスを経て出力を生成しているかを外部から検証しようとするものである。
評価軸③——相互作用適応性(Interaction Adaptability)
モデルが環境や入力の変化に応じて出力を動的に修正できる能力を評価する。ユクスキュルの機能環と最も直接的に対応する軸である。
ロボット評価では、障害物配置が変化した後のタスク成功率や行動修正率を測定する。LLM評価では、対話の文脈が変化した際に応答がどの程度適切に変化するかを定量化する。この軸では複数試行による統計的有意差の検定も重要な要件として挙げられている。
評価軸④——スキャフォールディング耐性(Scaffolding Robustness)
追加ヒントや文脈情報が与えられた際の性能向上度を、「スキャフォールディング耐性」として定量化する評価軸である。
ヒントなし条件とヒントあり条件を比較し、改善率をメトリクス化する。たとえば、段階的に情報を追加するタスクを設計し、各段階での正答率の変化を追うことで、モデルが外部支援をどれだけ有効活用できるかを評価する。複数のヒントレベルで繰り返し実験し、被験者間差や標準偏差を算出することで信頼性を担保する設計となっている。
三領域を横断するタスク設計——LLM・画像・ロボット
提案ベンチマークの特徴の一つは、LLM・画像生成・ロボットという異なる領域に対して、共通の評価フレームワークを適用しようとしている点にある。
LLM向けタスクの設計方針
LLM向けには主に二種類のタスクが提案されている。
意味一貫性テストは、同義の質問ペアに対する出力の意味的整合性を評価するタスクである。GLUEライクな構成を持ちつつ、答えの正確さだけでなく意味の整合性を重視する点で既存ベンチマークと差別化される。類義プロンプト間の出力類似度(意味コサイン類似度)を主指標とし、GPT-4等の最先端LLMをベースラインとして設定している。
解釈生成タスクは、曖昧表現に対する解釈(意味解説)生成能力を評価するものである。「細胞がリンパ節で何をする?」のような背景文脈を必要とする質問に対し、生成された解釈の妥当性をヒューマン評価や事前定義解釈との一致率で測定する。
画像モデル向けタスクの設計方針
画像生成モデルと画像認識モデルのそれぞれに対応するタスクが設計されている。
文脈依存画像生成タスクでは、テキストプロンプトと環境条件(例:「赤いボールが机上にある室内」)を入力とし、生成画像の意味的一致度をCLIPscoreで評価する。
画像意味評価タスクでは、画像と複数の意味候補を提示し、モデルが正しいラベルやキャプションを選択・生成できるかを評価する。正解率をヒューマン同意割合と比較することで、モデルの意味解釈能力の妥当性を検証する。
ロボット向けタスクの設計方針
ロボット評価では、機能環に基づく二種類のタスクが提案されている。
環境適応タスクは、センサー情報とタスク指示を入力とし、障害物配置などの環境変化後にロボットがどれだけ適切に行動を修正できるかをタスク成功率と環境変更後の修正率で測定する。
規範シフトタスクは、報酬や目的が変更された際の行動適応能力を評価するもので、「通常の行動」から「省エネ行動」への切り替えを求めるなど、規範そのものの変化に対する適応力を問う設計である。
既存ベンチマークとの差異——何が補完・拡張されるのか
提案ベンチマークは既存の主要ベンチマークを置き換えるものではなく、補完・拡張を意図している。
GLUEは多様なNLUタスクを提供するが、深い意味生成過程を直接測定する設計にはなっていない。提案ベンチマークは意味的一貫性や解釈過程を指標化し、LLMの文脈的解釈強度を評価軸に加える。
ImageNetは視覚認識性能の基準を提供するが、画像と意味の整合性や環境文脈は考慮されていない。提案ベンチマークでは生成画像や視覚認識に対して意味的一貫性を求め、画像中の対象・記号の「意味」を評価できる拡張性を持つ。
RoboBenchはロボットの計画・知覚・失敗検出を評価するが、主にタスク遂行能力に着目している。提案ベンチマークはそこに機能環に基づく意味的適応性と規範変化への対応能力を加え、ロボットの「記号論的認知」を総合評価しようとするものである。
実装ロードマップ——短期・中期・長期の展開
提案されたロードマップは三段階で構成されている。
短期(0〜6ヶ月) では、三項記号・機能環・スキャフォールディングの形式モデルを固め、プロトタイプ評価指標を実装・試験する段階である。必要なデータセットの収集とアノテーションも開始される。
中期(1〜2年) では、LLM・画像・ロボット各領域でパイロットベンチマークを構築・公開し、複数モデルによる評価実験と指標チューニングを進める。学会発表を通じてコミュニティとの対話も行い、データ・コードの整備が進められる。
長期(3〜5年) では、大規模ベンチマークスイートとして完成させ、企業・研究機関との連携で広範な評価を実施する。定期大会や評価報告基盤の整備を通じた標準化促進と、ヒューマン・イン・ザ・ループ評価の導入も視野に入れられている。
実装上のリスクとしては、記号概念の実装難度、マルチモーダル評価の複雑性、評価指標の妥当性検証の困難さが挙げられており、学際的チームによる反復的検証と柔軟なタスク調整による対処が計画されている。
まとめ——意味生成評価の地平を開く
バイオセミオティクスの三項記号論・機能環・スキャフォールディングという概念体系をAI評価に導入するこの提案は、既存ベンチマークが見逃してきた「意味をどう生成するか」という問いに向き合う試みである。
意味的一貫性・解釈可能性・相互作用適応性・スキャフォールディング耐性という四つの評価軸は、LLM・画像生成・ロボットという異なる領域に横断的に適用可能な共通語彙を提供する可能性を持つ。これにより、AIシステムが「正解を出せるか」だけでなく「どのように意味を形成しているか」を問う新たな評価の地平が開かれる可能性がある。
この研究が目指すのは、AIがどの要素で生物的意味生成を模倣できているか——あるいはどこに根本的な差異があるか——を解析し、次世代AIシステムの設計指針へとつなげることである。
コメント