RAGにおけるコンテキスト干渉問題とは何か
Retrieval-Augmented Generation(RAG)は、言語モデルが持つパラメトリック知識と、外部コーパスから動的に取得したノンパラメトリック知識を組み合わせることで、知識集約型タスクの精度と根拠性を高める枠組みです。
しかし、「取得した文書を多く入れればよい」という素朴な直感は、実際には通用しないことが繰り返し示されています。無関係な文書は精度を落とし、長文脈では重要情報の位置が性能を左右し、文書集合全体の多様性・被覆性・並び順が最終的な回答品質を決定します。
RAGの核心課題は「良い文書をk件選ぶこと」から、「相互作用する文書集合を限られたトークン予算でどう構成するか」に移っています。本記事では、この「干渉効果」の定義から検出・最適化手法まで、研究動向に沿って体系的に解説します。
干渉効果の定義:単体評価では捉えられない集合の問題
干渉効果を数式で捉える
干渉効果は「文書単体では有益でも、他文書や提示順序と組み合わさると下流生成の効用を下げる負の相互作用」として定義できます。
質問 q に対する文書集合 S の下流効用を U(S) としたとき、ある文書 di の条件付き限界貢献は次のように表せます。 Δ(di∣S)=U(S∪{di})−U(S)
この値が負であれば、その文書は集合 S に対して干渉的です。さらに二文書間の相互作用は以下で表せます。 I(di,dj∣S)=U(S∪{di,dj})−U(S∪{di})−U(S∪{dj})+U(S)
I<0 が破壊的干渉、I>0 が相補的相乗効果に相当します。この枠組みにより、集合選択・非単調効用・文書順序の重要性を一つの視点で整理できます。
干渉は「矛盾」だけを意味しない
干渉効果は単純な「矛盾」と同義ではありません。曖昧性・誤情報・ノイズ・意見対立・情報の鮮度差など、干渉の種類によって望ましい応答行動は異なります。
ある状況では複数候補を並列提示すべきであり、別の状況では古い情報を捨てて新しい情報を優先すべきです。また「不明」と答える方が正確な場合もあります。つまり、干渉検出は選択問題であると同時に、応答方針の推定問題でもあります。
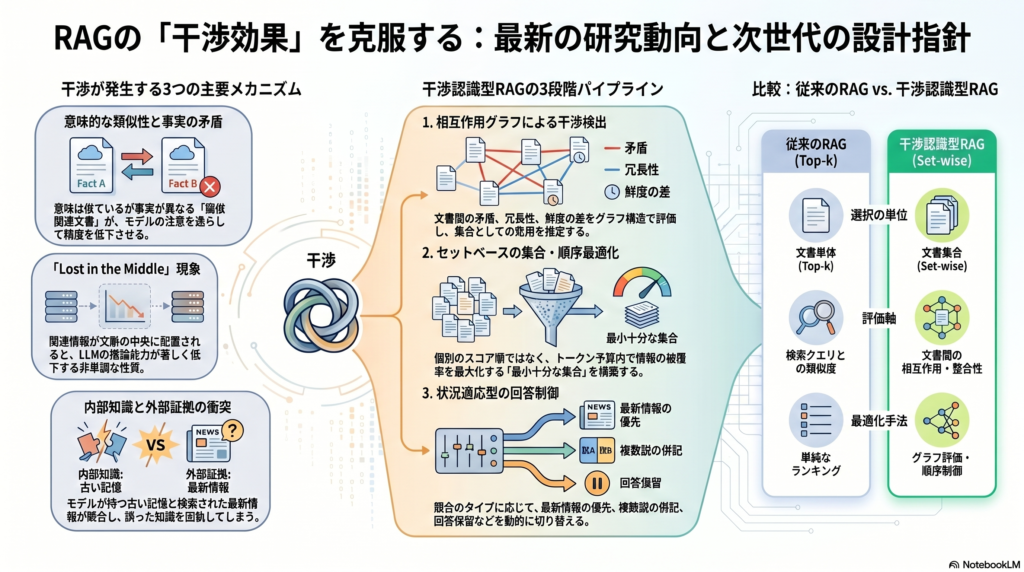
干渉が生じる4つのメカニズム
1. 無関係・擬似関連文書による注意の逸脱
最も基本的な干渉源は、意味的に類似しているが事実的には不整合な「擬似関連文書」です。単純な類似度検索はこの種の干渉を増幅しやすく、取得拡張が逆に精度を下げるケースが複数のベンチマークで確認されています。
高い意味類似度を持ちながら事実的に矛盾する文書は、特に危険な distractor として機能します。
2. 内部知識とのバイアス競合
モデルの内部記憶と外部証拠が衝突した場合、モデルは次のような問題行動を示す可能性があります。
- 誤った内部記憶を固持し続ける
- 頻出する証拠を信じる「多数決」的な挙動
- 内部知識と整合する証拠を優先する確認バイアス
とくに multi-hop 推論を要する競合では、オープンモデル・商用モデルの双方が検出に苦戦することが報告されており、干渉はモデル側の推論バイアスと複合的に発生します。
3. 文書の順序と位置による性能劣化
長文脈を扱う研究では、関連情報が文脈の先頭や末尾にあるときは性能が高い一方、中央に置かれると大きく低下するという「Lost in the Middle」現象が確認されています。
チャンク効用は非単調であり、「一つ追加すると良くなるが、さらに一つ追加すると悪くなる」というケースが存在します。貪欲な上位k選択では最適集合も最適順序も保証されません。
4. 内部知識と外部最新知識の競合(Context-Memory Conflict)
進化の速いAPI仕様などでは、最新ドキュメントを与えても、モデルの古い内部知識が優勢になって誤答する「context-memory conflict」が起きます。
この問題に対し、取得あり・なしの両方で応答を生成させ、「いつ取得文脈を無視し、いつ採用するか」を学習させるアプローチが有力な方向として浮上しています。
干渉検出のための観測量とベンチマーク
現実的な評価セットの必要性
干渉検出の研究では、合成データへの依存が大きな落とし穴です。合成データは知識競合の頻度や文脈反発を誇張しがちであり、現実のRAG失敗は文脈長や perplexity といった単独特徴だけでは説明できないことが示されています。
評価のための主要なベンチマークと観点は以下のとおりです。
DRUID:実世界のクエリと検索文脈に stance 注釈を付けたデータセット。現実のRAG失敗パターンを分析するのに適しています。
Ram Docs:曖昧性・ノイズ・誤情報が同時に現れる複合競合を導入し、競合タイプごとに必要な対処が異なることを強調しています。
MAGIC:ドキュメント間競合の multi-hop 版を対象にした評価設定。
Conflicts:競合タイプ分類と応答行動の両方を同時に評価可能にしています。
干渉検出に必要な3つの観測層
効果的な干渉検出には、少なくとも3つの異なる観測層が必要です。
第一層:文脈の実際の利用度
ACU(Attributed Context Utilization)のような指標で、生成器が選ばれた文書を本当に活用しているかを計測します。
第二層:集合内での文書の効果量
Influence Guided Context Selection が提案する CI value は、文書を一つ除いたときの性能劣化で重要度を測り、クエリ適合性・集合内の独自性・生成器との整合性を同時に取り込みます。
第三層:競合タイプの推定
競合タイプを明示することで、期待される応答行動が大幅に改善することが示されています。干渉検出器は「誤りそうかどうか」だけでなく、「どう応答すべきか」まで予測する必要があります。
相互作用グラフとしての干渉モデル
これらを統合すると、干渉検出器は文書単体スコアではなく相互作用グラフを出力するべきです。各ノードには relevance・freshness・source type・subgoal coverage・internal-memory agreement などの属性を持たせ、各辺には contradiction・redundancy・temporal mismatch・positional competition を持たせる構造が有効です。
RAGコンテキスト最適化手法の設計空間
古典的アプローチ:MMRと劣モジュラ最適化
コンテキスト最適化の古典的出発点は、Maximal Marginal Relevance(MMR) です。クエリ関連性と新規性を組み合わせ、既選択文書に似すぎた文書を抑える枠組みです。
その後の submodular summarization 研究は、代表性と多様性を同時に満たす目的関数が単調劣モジュラであれば、貪欲法に近似保証があることを示しました。カバレッジを増やしつつ冗長性を下げたいRAGの要件に、この枠組みは自然に適合します。
Set-wise Selection:集合全体を評価する新潮流
現代のRAGでは、文書を個別にランキングするのではなく、情報要件を満たす集合全体を選択するアプローチが有効であることが示されています(SETR)。
SETR は多段推論ベンチマークで set-wise selection の有効性を示しており、生成器に投入するトークンを削減しつつ、従来の再ランキング手法より高い正答性を達成する可能性が示唆されています。干渉最適化はランキングの延長ではなく、set retrieval として設計すべきという方向性です。
クエリ依存の動的多様性調整
DF-RAG は MMR をクエリ認識型に拡張し、テスト時に多様性強度を動的に調整することで、推論集約型QAでの精度向上を報告しています。固定の上位k選択・固定の多様性パラメータでは最適化できず、質問ごとに最適な多様性水準が異なることを示しており、静的ルールより条件付き最適化が必要であることの証拠となっています。
生成器認識型の効用推定
より根本的なアプローチとして、「IR上の relevance が高い」ことよりも「その読者モデルにとって実際に有用か」を重視する方向が急速に強まっています。
- CI value(Influence Guided Context Selection):inference-time での文脈品質評価
- LURE-RAG:listwise loss を使った軽量再ランキング
- RRPO:強化学習によるリランキングの逐次意思決定問題への再定式化
これらに共通するのは、selector が検索器ではなく reader-aware utility estimator である必要があるという考え方です。
コンテキスト圧縮と順序制御
選択と並行して、圧縮・順序制御も干渉低減に重要です。
LongLLMLingua はlong contextのコスト・性能・位置バイアスの三問題を同時に扱い、CompSelect は抽出・再ランキング・切り詰めを組み合わせて「最小十分手がかり集合」を構築します。
CARROT は ordered chunk combinations の探索を MCTS で行い、相関と非単調効用を明示的に扱います。これらは干渉低減で本当に効くのは「追加文書を増やすこと」ではなく、「信号密度の高い、順序づけられた最小集合を構築すること」だと示しています。
干渉認識型RAGの推奨アーキテクチャ
5段構成の処理パイプライン
現状の研究成果を統合した最も有望なアーキテクチャは、以下の5段構成です。
- 候補生成:検索器が recall を優先して広めに候補を収集
- 干渉検出:クエリ subgoal coverage・pairwise contradiction・redundancy・freshness mismatch・internal-memory disagreement を評価して集合効用を推定
- 集合・順序最適化:干渉指標に基づいて最終的な文書集合と提示順序を決定
- コンテキスト圧縮:選ばれた集合から手がかり単位の圧縮を実施
- 競合認識型回答制御:競合タイプに応じて「統合回答」「複数候補の併記」「最新情報の優先」「保留・不明」を切り替える
最適化目的関数の定式化
概念的には次のような目的関数を置くことができます。S,πmaxi∑vixi+i<j∑(sij−aij)xixj+ρ⋅Order(S,π)−λ⋅Cost(S)
subject to ∑icixi≤B
ここで vi は文書単体の有用性、sij は subgoal coverage・補完性による相乗効果、aij は矛盾・冗長・誤誘導による干渉ペナルティ、Order(S,π) は順序最適化の便益、B はトークン予算です。
実装上は「軽量代理モデルで上位m件に絞る → greedy または beam / MCTS で集合と順序を調整する」という二段階近似が現実的です。
学習信号の設計
従来の relevance label だけでは不十分です。候補集合に対する leave-one-out・swap・permutation 実験から実効 utility supervision を作り、その上で listwise 学習か逐次選択の強化学習を行うことが推奨されます。
まず reader を固定したまま selector のみを utility-aware に学習し、その後に competitor-aware response controller を追加する拡張が現実的なロードマップです。
評価計画:4つの評価環境と多面的な指標
評価すべき4つの問題設定
単一ベンチマークで全てを測ろうとすると、合成データの偏りに引きずられる可能性があります。以下の4環境を分けて評価することが推奨されます。
① 無関係・擬似関連ノイズへの頑健性:irrelevant-context 系設定や実世界の claim verification タスクで評価
② ドキュメント間の競合:MAGIC・Conflicts、および複合競合を含む Ram Docs で評価
③ 多段推論のカバレッジ:multi-hop QA ベンチマーク群で測定
④ 内部・外部知識の競合:時系列差・API更新系のタスクで鮮度競合を評価
従来指標を超えた干渉固有の評価軸
EM(完全一致)や F1 だけでは不十分です。以下の指標を組み合わせることが必要です。
- ACU(Context Utilization):文脈の実際の利用度
- Expected Behavior 遵守率:競合状況での適切な応答行動の達成率
- Token cost / latency:実運用上の効率指標
- 負の相互作用の平均強度:干渉の大きさを定量化
- Permutation Sensitivity Gap:順序変化に対する性能変動
- Subset Ablation Regret:集合からの除去に対する性能劣化
Conflicts の研究が示したように、競合状況では「正しい答えを含む」だけで不十分で、どう振る舞うべきかまで評価しなければ改善の方向を誤る可能性があります。
まとめ:「top-k検索+独立再ランキング」から干渉認識型選択へ
本記事では、RAGにおける干渉効果の定義から、発生メカニズム・検出手法・最適化アプローチ・評価方法まで体系的に解説しました。
重要な結論は以下のとおりです。
- 干渉効果は文書単体の品質問題ではなく、集合全体の相互作用として捉えるべき
- 検出器は文書単体スコアではなく相互作用グラフを出力する設計が有効
- 最適化は ranking の延長ではなく set retrieval として設計する必要がある
- 生成器認識型の selector と、競合タイプに応じた response controller の二層構造が最も実装上も研究上も妥当
- 単一ベンチマークではなく複数の評価環境と干渉固有の指標を組み合わせた評価が不可欠
「top-k検索+独立再ランキング」から「干渉を持つ文書集合の検出・最適化」へ研究軸を移す転換点は、すでに始まっています。
コメント