階層的予測処理における注意機構の実装:精度の動的調整をアルゴリズム化する方法
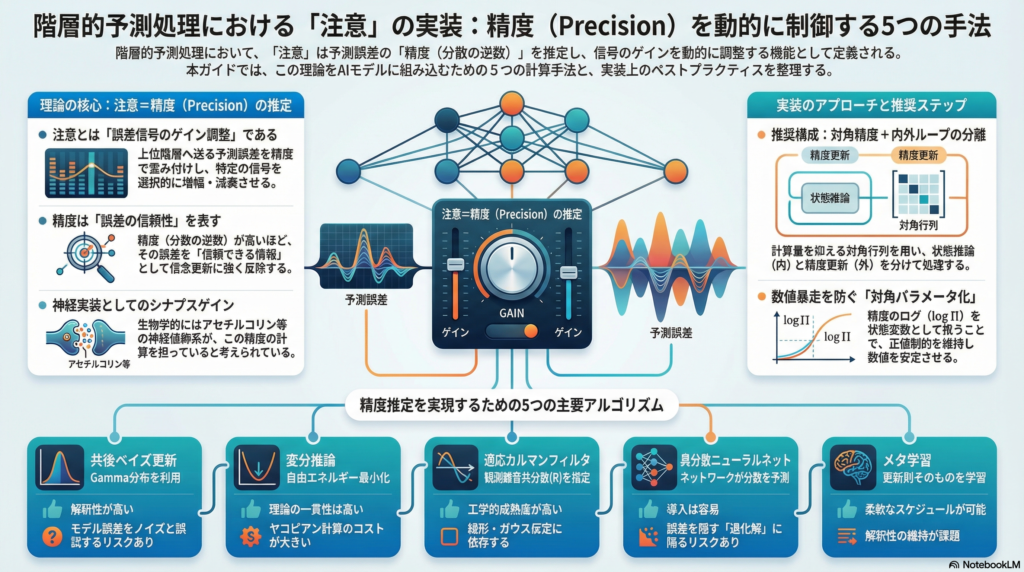
階層的予測処理(Hierarchical Predictive Processing / Predictive Coding)は、脳の知覚・認知を「予測と誤差の往復」として記述する有力な計算論的枠組みである。この枠組みにおいて「注意」とは何か——その問いへの現在有力な答えが「精度(precision)推定」であり、精度を誤差信号のゲインとして動的に制御することで注意現象を説明しようとする立場だ。
本記事では、この「注意=精度推定」という定式化を、具体的なアルゴリズムへ落とし込む方法を体系的に整理する。設計の核心は「精度をどの確率変数として置くか」「更新則をどの推論手続きに同期させるか」「階層と時間へどう伝播させるか」の三点に集約される。実装の選択肢としては、共役ベイズ更新・変分推論・カルマンフィルタ系・ニューラルネットによる異分散学習・メタ学習の五つが主要な方法群となる。さらに、ニューラル実装の生物学的妥当性や、実験設計・評価プロトコルまでをカバーする。
注意と精度:理論的な出発点
予測符号化における精度の役割
予測処理モデルの基本構造は、上位階層が「予測」を生成し、下位階層がその予測との「誤差」を上位へ返すループとして成立する。しかし重要なのは、この誤差信号がそのまま信念の更新へ使われるのではないという点だ。誤差がどれほど信頼できるか——つまり、誤差の信頼性=精度(precision、分散の逆数)——が更新量を決定する。
数式で整理すると、観測 y と潜在状態 z の生成モデルを p(y∣z,Σ)=N(y;g(z),Σ),Π=Σ−1
と置いたとき、負の対数尤度はL(z,Π)∝21(y−g(z))⊤Π(y−g(z))−21log∣Π∣
となる。ここで精度行列 Π が予測誤差 e=y−g(z) に直接係数として入ることがわかる。注意を精度の変化として表現するということは、この係数=ゲインを動的に調整することと同型になる。
精度が誤差ゲインとして機能するという対応づけ
階層的な生成モデルでは各レベル l に誤差 el と精度 Πl が立ち、精度で重み付けされた誤差 δl=Πlel
が上向きメッセージとして機能する。注意とは、この Πl を動的に増減させることによって、特定の誤差信号を選択的に増幅・減衰させる機構として理解できる。神経実装的には「精度は誤差ユニットのシナプスゲインとしてコードされる」という対応づけが明示されており、これが注意=精度推定という主張の具体的な中身となる。
精度推定のアルゴリズム:5つの主要パターン
共役ベイズ更新:解釈性と制約のバランスに優れた基本実装
最もシンプルかつ解釈性の高い実装として、ガウス尤度に対する精度の共役事前分布であるGamma分布を利用したベイズ更新が挙げられる。各レベル l・各次元 i について el,i∣τl,i∼N(0,τl,i−1),τl,i∼Gamma(a0,b0)
と置けば、N サンプルからの事後更新は a=a0+2N,b=b0+21t=1∑Nel,i(t)2
となり、期待精度 E[τl,i]=a/b をゲインとして利用できる。オンライン化は忘却係数付きの十分統計更新によって実現できる。
設計上の重要点は二つある。一つは、事前パラメータ (a0,b0) が精度の下限(floor)として機能し、数値暴走を防ぐ役割を果たすこと。もう一つは、誤差にモデルの系統誤差が混入すると精度推定がノイズの増大として誤解釈してしまう「同定性問題」が生じる点で、この場合はEM的にモデル更新と精度更新を分離する設計が有効になる。
変分推論・一般化フィルタリング:原理的一貫性を重視した統合実装
変分自由エネルギー最小化の枠組みでは、潜在状態・生成モデルパラメータ・精度の三者を一括して推定対象として扱える。一般化フィルタリング(Generalised Filtering)がその代表例であり、非線形状態空間モデルに対してオンラインに近い形で事後密度を更新しながら、精度に相当する揺らぎ振幅も同時に推定できる。
実装上は、精度 Π を直接更新するより、logΠ を状態変数として置いて勾配降下で更新する方が数値的に安定しやすい。正の制約を対数変換によって自動で満たせるためだ。また、精度自体を「上位が予測し、下位の誤差で修正する」対象にできる点が理論上の強みであり、注意がトップダウン制御され得るという現象を、推論の論理として実装できる。
一方で、実装の複雑さとヤコビアン計算のコストが課題となり、数値安定化の設計に相当な注意が必要となる。
適応カルマンフィルタ:工学的成熟度の高い精度追跡
線形ガウス状態空間の文脈では、観測雑音共分散 R が実質的に観測の信頼性=精度を規定する。この Rt をオンラインで推定することは、注意=精度の動的調整と数学的に同型になる。革新(イノベーション)分散整合やMAP推定を用いた適応カルマンフィルタは、工学分野で豊富な研究蓄積があり実装の信頼性が高い。
非定常観測ノイズを持つ1次元ランダムウォークの簡易シミュレーションでは、固定 R のフィルタより Rt を推定する版の方が平均二乗誤差(MSE)が改善する傾向が見られる。低ノイズ区間では精度を高く設定して誤差を積極的に反映し、高ノイズ区間では精度を下げて外れ値の影響を抑えるという、注意=精度の直観と一致した動作になる。
カルマン系の課題は、線形・ガウス仮定への依存と、階層化した場合の設計コストにある。なお、予測符号化ネットワークが線形システムでカルマンフィルタに近い性能を示す一方、「主観的な事後分散を追跡しない変種」はカルマンフィルタとの乖離が生じるという指摘があり、明示的な精度追跡モジュールの工学的意義を示唆している。
異分散ニューラルネット:最も導入しやすい実装
深層学習の文脈では、入力依存の観測ノイズ(aleatoric uncertainty)を学習する異分散(heteroscedastic)モデルが実用的な選択肢になる。ネットワークが σ2(x) を予測して負の対数尤度 L=2σ2(x)(y−y^)2+21logσ2(x)
を最小化することで、学習された σ2(x) の逆数が精度として誤差の重み付けを担う構造になる。予測符号化的には「精度で重み付けした予測誤差を最小化する」機構を損失関数から実現していると解釈できる。
導入コストが最も低い一方、「モデルが σ2 を過大化することで誤差を隠す」退化解(分散膨張)に陥るリスクがある。正則化・分散の下限設定・校正(calibration)評価をセットで実施することが重要になる。
メタ学習:精度更新則そのものを学習する先進的アプローチ
変分推論アルゴリズム自体をタスク分布上でメタ学習する研究では、精度更新則を手動で設計せず、誤差系列やコンテキストから適切な精度スケジュールを少数ステップで生成することが原理的に可能と示されている。解釈性を維持するには、メタ学習の対象をGamma事後のパラメータや log-precision に限定するアプローチが安全とされる。
階層構造と情報フロー:設計上の核心
設計軸と主要なトレードオフ
精度の動的調整をアルゴリズム化する際、実装は四つの軸で分岐する。
精度の表現形式については、スカラー・対角・低ランク+対角・フル行列の選択肢がある。対角精度は軽量で安定しており、まず対角からはじめるのが推奨される。フル行列は表現力が高いが行列反転の計算量(O(dl3))が高次元で問題になる。
推定対象については、観測ノイズ(aleatory uncertainty)なのか、モデルの認識不確実性(epistemic uncertainty)なのか、あるいは両者なのかを明示することが重要となる。
更新タイミングについては、推論(状態更新)と同時に行うか、EM的に状態推論(内ループ)と精度更新(外ループ)を分離するかの選択がある。数値安定性の観点から、内外ループの分離を推奨する先行研究が多い。
時間適応については、逐次・オンライン処理をどう担保するかが実用上のポイントになる。
推奨実装ステップ
最初の実装として「対角精度+内外ループ分離」を推奨する。手順の骨格は以下のとおりだ。
for each time step t:
set bottom input x_0 = y_t
# --- 内ループ:状態推論 ---
for k = 1..K: # 推論反復
for l = 0..L-1:
xhat_l = g_l(μ_{l+1}) # トップダウン予測
e_l = x_l - xhat_l # 予測誤差
Π_l = softplus(λ_l) + ε # 正値制約
δ_l = Π_l ⊙ e_l # 精度重み付き誤差
μ_{l+1} = μ_{l+1} + η * (J^T δ_l - prior_term)
# --- 外ループ:精度更新 ---
for l = 0..L-1:
λ_l = clip(λ_l + ρ * (0.5*(Π_l ⊙ e_l ⊙ e_l - 1)), λ_min, λ_max)
# --- 任意:生成モデルパラメータ学習(安定後に有効化) ---
θ = θ - α * ∂F/∂θ精度パラメータは λl∈R をsoftplusで変換することで正値制約を自動的に満たし、クリッピングによって暴走を防ぐ。
ニューラル実装と生物学的妥当性
シナプスゲインと神経修飾系
精度=誤差ゲインという計算論的要請に対し、神経回路レベルではアセチルコリンやノルアドレナリンなどの神経修飾系が「不確実性計算」を担う候補として挙げられている。注意が有効結合(effective connectivity)を変えるという観点では、ガンマ帯域の同期を介した情報伝達効率の変調が、精度によるシナプスゲイン制御の実装候補として議論されてきた。
これらは「精度を誰がどう変えるか」という神経実装上の問いに対し、単一の答えではなく複数の候補機構(修飾系・同期・抑制性回路など)が競合する状況を示しており、計算論的な枠組みと実験的検証をつなぐ研究が進行中といえる。
反証可能性の問題
「何でも精度の変化として説明できてしまう」という可反証性の問題は重要な批判として認識されている。精度上昇は応答の周波数・潜時・ゲインなど複数の指標へ同時に影響するため、観測可能な予測を複数立てることで反証可能条件を整理する試みがある。実装者はこの点を念頭に置き、精度推定が本当に分散の逆数として機能しているかを校正評価も含めて確認する姿勢が求められる。
評価プロトコルと実験設計
精度機構の評価は「予測誤差が小さい」だけでは不十分で、不確実性の正確な表現と誤差の適切な重み付けが同時に成立しているかを確認する必要がある。
主要な評価指標は以下の通りだ。予測誤差(MSE・MAE)は基本指標として使いやすいが、異分散モデルでは対数尤度(NLL)が第一級の指標となる。精度機構の有無を比較するにはベイズ因子が有効で、近似モデル証拠(変分自由エネルギー=ELBO)も重要な参照値となる。実用的には外れ値耐性(PR/ROC)、計算効率、精度推定の収束性も合わせて評価すべきだ。
実験設計としては、まず合成データ(非定常ノイズの切替・ドリフト・外れ値混入)でアルゴリズムの挙動を検証し、固定精度のベースラインと比較する。次いで音・視覚・生体信号などの実データで入力依存精度の学習が成立するかを確認し、最終的に部分観測強化学習(POMDP環境)で行動価値推定の安定化への寄与を評価する構成が推奨される。
実装上の落とし穴と対策
精度実装の失敗の多くは「数値暴走」か「同定性の破れ」に由来する。以下に主要な落とし穴と対策をまとめる。
**精度の暴走(発散)**については、精度が大きくなると誤差が過大に増幅され推論が振動・発散しやすい。対策はlog精度パラメータ化・クリッピング・上下限の設定・精度更新学習率を小さくとること、そして状態推論が収束してから精度更新を行う順序の徹底だ。
モデル誤差とノイズの混同については、生成モデルが不十分な場合、誤差の原因をノイズと誤解釈して精度が下がり続ける可能性がある。情報的な事前分布を精度に置くこと、モデル改善を先行させること、変化点検知を補助指標として導入することが有効な対策となる。
異分散NNの退化解については、分散を過大化することで誤差を隠す退化解を防ぐために、正則化・分散下限・校正評価のセット対応が必要となる。
まとめ:注意=精度の工学実装に向けた要点
本記事の主要な論点を整理する。「注意=精度推定」という定式化は、予測処理の理論的核心であり、精度が誤差ユニットのシナプスゲインとして機能するという対応づけが工学・神経科学を橋渡しする。実装の中心は、精度をどう表現し、どの推論手続きで更新し、階層・時間へどう伝播させるかの三点にある。
まず「対角精度+内外ループ分離」でスタートし、log精度パラメータ化で暴走を防ぎながら段階的に複雑化するアプローチが、安定性と拡張性の両面で合理的だ。評価は予測誤差・NLL・ベイズ因子・校正・計算効率を組み合わせて行うべきであり、精度が「本当に分散の逆数として機能しているか」を継続的に確認する姿勢が重要となる。
コメント