なぜ今、形式言語から自然言語への転移が注目されるのか
大規模言語モデル(LLM)の台頭により、「モデルは統語構造を本当に学んでいるのか」という問いが改めて焦点を当てられています。特に注目されるのが、フィラー–ギャップ依存(Filler-Gap Dependency: FGD) と**島制約(Island Constraints)**という二つの現象です。これらは理論言語学において長年中心的な研究課題であり、「抽出の局所性」をめぐる問いに直結します。
一方、NLP分野では近年、Dyck言語やcounter languageといった形式言語を使い、RNNやTransformerがどこまで階層構造・計数・長距離依存を学べるかが検証されてきました。さらに、形式言語を自然言語の事前学習バイアスとして活用しようとする流れも生まれています。
しかしここに重大なギャップがあります。「形式言語能力の研究」「形式言語から自然言語への転移研究」「自然言語モデルのFGD・島制約評価研究」という三系統は、それぞれ個別に進展しているものの、Dyck事前学習そのものを自然言語の島制約・FGDに直接ぶつける同一設計の研究は、主要原著群ではほぼ見当たりません。本記事では、この空白を埋めるための理論的背景、先行研究の整理、そして精密な転移実験設計の要点を解説します。
形式言語能力研究:RNNとTransformerで何がわかっているか
Dyck言語学習における各アーキテクチャの特性
形式言語能力研究の出発点は、LSTMなどのRNNがどこまでの形式言語を学習できるかという問いです。古典的には、LSTMがa^n b^n c^nのような単純なcontext-sensitive言語まで学習できると報告されており、また「Dyck-1や一部のcounter languageでは強く、Dyck-2やより複雑なスタック操作では難化する」という知見が繰り返し確認されています。
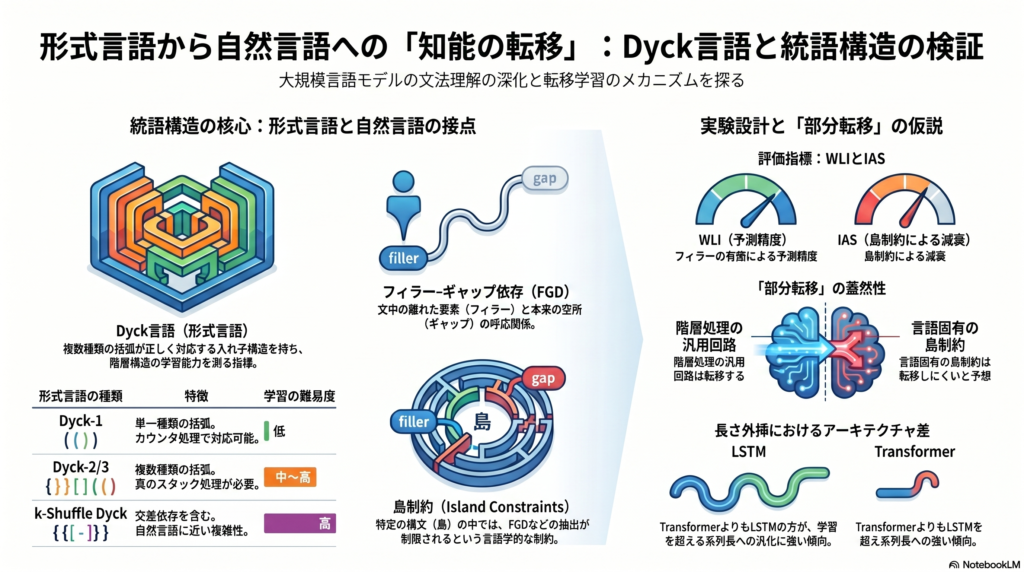
Dyck言語とは、複数種類の括弧が正しく開閉対応する文字列からなる言語です。Dyck-1は単一括弧種、Dyck-2は二種類の括弧種を含み、複数括弧種の正しいスタック整合が必要になります。LSTMはDyck-1において「カウンタ的処理」で対応できる一方、Dyck-2では真のスタック様処理が必要になり難易度が上がります。
RNNの精度には有限精度計算という理論的制約も影響します。有限精度ではLSTMとReLU-RNNが計数においてGRUより強いと指摘されており、アーキテクチャの選択が形式言語学習の成否に直結します。
TransformerのDyck言語処理能力と理論的限界
Transformerについては、工夫付きself-attentionがDyck-nをある程度扱える可能性が示されています。一方で、理論的観点からは「層数やヘッド数が入力長とともに増えない限り、階層構造表現には理論限界がある」という批判的見方も存在します。
特に重要なのが**長さ外挿(out-of-distribution length generalization)**の問題です。TransformerはIIDの設定では強い性能を示すものの、学習時の系列長を超えるケースでの性能劣化が実証的・理論的に繰り返し指摘されています。一方でLSTMは、長さ外挿においてTransformerを上回るという報告も複数あります。これはTransformerが「暗記に近い近似」で形式言語を処理している可能性を示唆し、真の階層一般化ができているかどうかを疑わせます。
自然言語への転移:先行研究が示す可能性と限界
人工言語事前学習は自然言語に有用なバイアスを与えるか
形式言語・人工言語による事前学習が自然言語に有用な帰納バイアスを注入し得るという研究は複数存在します。音楽データのような潜在構造をもつ非自然言語データの事前学習が自然言語LMに役立つという報告、また再帰・交差依存・Zipf分布を比較したところ非文脈自由な関係が最良の誘導バイアスとなったという報告は、形式言語事前学習の可能性を示す積極的証拠です。
さらに最近の研究では、形式言語によるpre-pretrainingが自然言語学習の効率を改善するという報告もあります。統計的依存と入れ子構造が自然言語転移に有効という日本語研究の知見とも整合します。
FGDと島制約:モデルは本当に学んでいるのか
自然言語モデルがFGDを学習しているかどうかについては、肯定的証拠と懐疑的証拠が併存しています。RNN言語モデルが長距離FGDと一部の島制約を学ぶ証拠があるという初期報告がある一方で、指標の修正によって結果が大きく変わること、構文頻度と学習差の相関が存在すること、モデルが共有表象を学んでいるというより表層ヒューリスティックに依存している可能性が指摘されています。
言語間での差異も重要です。ノルウェー語では一部の島非感受性パターンをモデルが学べる一方、オランダ語のwh-island制約はLSTMが十分に捉えられなかったという報告もあります。英語・ノルウェー語の比較で結果が混合的であり、「無バイアス学習を支持しない」という慎重な結論も出されています。最近のメカニズム研究では、内部表象の因果介入からFGD構文間に共有構造があるという報告もあり、行動的評価だけでなく内部メカニズムの分析も重要になっています。
三系統を統合する実験設計:何をどう測るか
主要仮説の設定
Dyck事前学習から自然言語FGD・島制約への転移を検証するためには、「転移するか否か」だけでなく、「何が転移して何が転移しないか」を分解する必要があります。以下の四つが主要仮説として設定されます。
仮説A:Dyck-2/3のような入れ子構造事前学習は、正則言語や構造の薄い人工言語よりも、自然言語の非島条件における長距離FGDを改善する。
仮説B:k-Shuffle Dyckや交差依存を持つ形式言語は、純粋なDyckよりも、構文横断の共有一般化と島内での依存減衰に有利である。
仮説C:転移は全面的ではなく、非島のFGDには見えるが、島制約そのものには弱いという部分転移になる。
仮説D:外挿ではLSTMとTransformer-XLが標準Transformerを上回る。
評価指標の設計:WLIとIAS
FGD評価の中核となるのが**Wilcox Licensing Interaction(WLI)**です。これはsurprisal差分を用いた指標で、fillerが存在するときにgapをより予測しているかどうかを測ります。具体的には、filler有無×gap有無の2×2条件でのsurprisalの交互作用として定義されます。
島制約への転移を直接評価するのが**Island Attenuation Score(IAS)**です。これは非島条件のWLIと島条件のWLIの差として定義され、島内でfiller–gap期待が適切に減衰しているかどうかを示します。IASが正で大きいほど、モデルが島制約を適切に扱っていると解釈されます。
これらに加え、形式言語認識精度、長さ外挿精度、BLiMP/SyntaxGymの最小対正答率、構文横断転移指数、サンプル効率利得といった複数の指標を組み合わせることが推奨されます。
形式言語の段階設計
事前学習に用いる形式言語は、Regular対照→Dyck-1→Dyck-2→Dyck-3→k-Shuffle Dyck→交差依存言語(a^m b^n c^m d^n型)→Copy言語という段階的な複雑度構成が望まれます。各条件のトークン予算を厳密に統一し、「構造バイアスそのもの」「単なる最適化ウォームスタート」「自然言語事前学習の絶対優位」を切り分けるための対照群設計が不可欠です。
特にk-Shuffle Dyckと交差依存言語を含めることの理論的意義は大きいです。自然言語はmildly context-sensitiveな性質を持つことが示されており(スイスドイツ語の交差依存による証拠)、Dyckのような純粋なCFLだけでなく、より広い計算クラスに対応する形式言語を使うことで、自然言語の特性により近い帰納バイアスを注入できる可能性があるからです。
評価セットと転移先設計
転移先の主軸は英語に置くことが合理的です。FGDと島制約の評価資源(BLiMP、SyntaxGymなど)が最も豊富であり、先行研究との比較も容易です。
評価セットは少なくとも以下を含む必要があります。非島FGD基本セット(実目的語抽出)、Complex NP island(複合名詞句島)、wh-island(embedded question島)、Subject island(主語島)、Adjunct island(付加詞島)、そして関係節・it-cleft・トピック化・tough構文をカバーする構文横断FGDセットです。
各テンプレートはfiller種類・述語フレーム・埋め込み深さ・語彙頻度をバランスさせて設計します。また、BLiMP等の最小対評価ではトークン化後の長さ差が確率比較を歪める可能性があるため、tokenized lengthが一致する最小対の使用、またはper-token正規化済みスコアの併記が推奨されます。
期待される結果と解釈の注意点
最も蓋然性の高い結果:部分転移
現在の研究状況から最も可能性が高いのは完全転移でも完全失敗でもなく、部分転移です。Dyck-2/3やk-Shuffle Dyckで事前学習したモデルは、ランダム初期化や正則対照よりも非島条件の長距離FGDを適切に処理できる可能性がある一方、IASの改善は限定的で、島内での依存期待減衰は弱い結果になると予想されます。
この解釈の含意は重要です。形式言語事前学習が「スタック・カウンタ・依存追跡」の汎用回路を与え得る一方で、島制約に必要な節タイプ・ライセンシング・構文特異性は与えられない可能性があります。言い換えれば、島制約は単なるスタック整合性の問題ではなく、より言語特有の知識を必要とすることを示唆します。
否定的結果の解釈:三つの可能性
もしDyck事前学習で一切転移が見られなかった場合でも、「階層構造は不要」という直接的な結論は早計です。考えられる解釈として、(1)Dyck的階層性はFGDに必要な一部条件にすぎず、自然言語の依存形成にはより豊富な抽象が必要だった可能性、(2)転移先評価が頻度やトークン化の交絡に汚染されており、構造利得が測定できなかった可能性、(3)事前学習本体は有効でも埋め込み差し替えや微調整設計が不十分だった可能性——という三点が考えられます。
限界の明示
島制約は言語によって実現が異なるため、英語だけでの一般化には限界があります。FGD評価は構文頻度やfiller typeの影響を受けやすく、表層ヒューリスティックと共有抽象を混同するリスクがあります。また、形式言語は意味や語用論を持たないため、自然言語統語が組み込む意味的・情報構造的制約を捨象することになります。日本語についてはwh-in-situが中心であり、英語型のovert filler–gapを主軸とした設計はそのままでは移植できない点も注意が必要です。
まとめ:断絶を埋める実験設計の核心
形式言語能力研究・転移研究・FGD/島制約評価研究という三系統は個別には進展しているものの、Dyck事前学習を自然言語の島制約・FGDに直接当てる同一設計の研究は現状では希薄です。この断絶面を埋めるためには、matched token budget・長さ一致最小対・四重対照設計(ランダム/対照/人工/自然)・FGDと島制約の同時評価という実装上の核心を守ることが不可欠です。
最も蓋然性の高い予測は「部分転移」であり、純粋なDyckではFGDの一部しか転移せず、交差依存やmildly context-sensitive側の人工言語の方が共有一般化で優位になる可能性があります。この研究が厳密に実施されれば、形式言語由来の階層処理能力が自然言語にどう接続されるか——そして、それがどこで接続されないか——について、現在の文献状況を一段進める成果になり得ます。
コメント