オートポイエーシスとAI——なぜ今、この問いが重要なのか
「AIは本当に意味を理解しているのか」——この問いは、人工知能研究の黎明期から繰り返し投げかけられてきた。大規模言語モデルが流暢な文章を生成し、画像認識モデルが人間の精度を超えるいま、それでもなお「意味の自己生成」という問題は未解決のまま残っている。
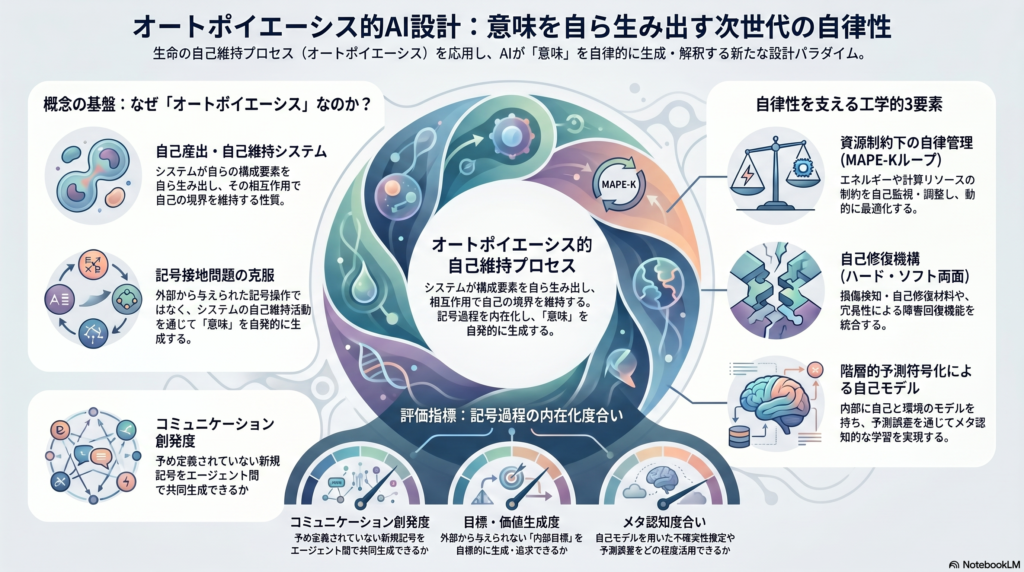
その鍵を握る一つの理論的枠組みが、**オートポイエーシス(Autopoiesis)**だ。チリの神経生物学者Humberto MaturanaとFrancisco Varelaが1970年代に提唱したこの概念は、「システムが自己の構成要素を自ら生み出し、その相互作用によって自己の構造と境界を維持する」性質を指す。生命の本質を自己維持性に求めたこの理論は、認知科学、社会システム論、そして現代のAI研究へと波及しつつある。
本記事では、オートポイエーシス理論の哲学的基盤を整理したうえで、資源制約・自己修復・自己モデルという三つの工学的要素がどのように「記号過程の内在化」に寄与しうるかを検討する。さらに具体的な実装事例、評価指標の候補、そして倫理・哲学的含意まで幅広く論じる。
オートポイエーシス理論の哲学的基盤
自己生成・自己維持システムとは何か
オートポイエーシスの核心は「自己産出性」にある。細胞を例にとれば、細胞膜は内部の化学反応によって生み出され、その膜がまた内部反応を可能にする環境を維持する——という循環的な自己参照が成立している。Maturana & Varelaはこの構造を「閉じた操作的ネットワーク」として定式化し、生物の本質はこの自己維持性にあると論じた。
この考えは認知科学へと拡張され、**エナクティブ認知(Enactive Cognition)**という概念が生まれた。Varelaらは「知覚は生物自身の内部構造によって構築される」と主張し、身体と環境の相互作用を通じた能動的な意味形成を強調した。つまり、認知とは外界をそのまま写し取る受動的なプロセスではなく、生物が自らの身体性に根ざして世界を「作り出す」能動的なプロセスであるとされる。
さらにNiklas Luhmannの社会システム論への適用では、組織や言語共同体もまたオートポイエーシス的に自己維持する集合体と見なされる。このように、この理論は生物学の枠を越えて、認知・社会・情報といった多様な現象を統一的に説明する可能性を秘めている。
AIへの適用における焦点
人工エージェント設計にこの理論を適用する場合、焦点となるのは「自己生産・自己維持を通じた自律性の実現」である。単にルールを実行するだけでなく、自己の構造や目標を維持・更新しながら環境に適応し続けるシステムをいかに設計するか——これがオートポイエーシス的AI設計の中心的問いとなる。
記号過程の内在化とは何か
記号接地問題との比較
記号過程(Semiosis)とは、対象に対する記号操作とその解釈・意味生成を含む循環的過程を指す。哲学者Charles Sanders Peirceの三項モデル(対象・記号・解釈者)に代表されるように、記号は単なる形式ではなく、その「意味」が解釈者との関係において生まれるものとされる。
従来のシンボリックAIは、記号を操作するルールを外部から与えられるが、その記号が「何を指しているか」という意味の根拠をシステム自身が獲得することは困難だった。これが**記号接地問題(Symbol Grounding Problem)**と呼ばれる古典的難問である。現行の大規模言語モデルにおいても、内部で処理される「記号」の意味は訓練データ内の統計的一貫性として表現されるにすぎず、真の意味での自己解釈には至っていないとされる。
内在化の定義と測定可能指標
本稿における「記号過程の内在化」とは、システム自身が意味づけ(意味体系)を構築・更新し、記号操作が自己指向的・自己維持的になる度合いと解釈する。
測定可能な指標の候補としては以下が考えられる。
- 意味的一貫性・概念獲得度:環境内の状態に対する内部符号の対応精度と安定性
- 概念一般化・転移能力:学習済みタスク外の状況での適応速度と正答率
- コミュニケーション創発度:マルチエージェント系において予め定義されていない新規記号を共同生成できるか
- 目標・価値生成度:外部から与えられない「内部目標」や価値尺度を自律的に生成・追求する度合い
- メタ認知度合い:自己モデルを用いた予測誤差評価や不確実性推定の活用度
これらは現段階では形式化が難しく研究途上であるが、「意味の自己生成・自己評価」という観点から体系的な研究が求められる領域である。
工学的要素:自律エージェントを支える三つの柱
資源制約下での自律性——エネルギー・計算・通信
自律ロボットや分散エージェントは、電源や計算リソースに制約がある中で安全性と効率を両立する必要がある。自律走行ロボットではバッテリ寿命や再充電スケジュールがミッション遂行に直結し、大量のセンサーデータを高速共有できない状況では分散的推論やローカル計算が不可欠となる。
こうした多様な制約を動的に管理するためのアーキテクチャとして、**MAPE-Kループ(Monitor-Analyze-Plan-Execute with Knowledge)**のような自己適応フレームワークが注目されている。エネルギー効率、計算コスト、安全性といった競合する要求をリアルタイムに最適化するこの枠組みは、オートポイエーシス的自律性の工学的実装として有望な方向性の一つと言える。
自己修復機構——ハードウェアとソフトウェアの両面から
物理層面では、自己修復材料や再構成機構の研究が急速に進展している。コーネル大学では、刺突による損傷を検知し自己修復するロボットを実証した。損傷を受けると動作を停止し、修復後に再起動するというこのプロセスは、生物の傷治癒メカニズムに着想を得ている。
ネブラスカ大学のMarkvickaらは、液体金属を含む多層構造の電子皮膚を開発した。皮膚に裂孔が生じると電流を流して熱による自己修復を行うこの技術は、ソフトロボットやウェアラブルデバイスへの応用が期待されている。
ソフトウェア面では、障害検出機構や冗長性確保によるフォールトトレランス、自己最適化アルゴリズムの開発が課題となる。自律システムに必要な自己管理機能として「自己構成・自己最適化・自己修復・自己保護」という四つの機能が挙げられており、これらを統合的に実現することが今後の重要課題である。
自己モデルと階層的予測符号化——メタ認知への道
エージェント内部に自分自身や環境のモデルを持つことで、学習・制御の効率と柔軟性が増す。**階層的予測符号化(Hierarchical Predictive Coding)**の枠組みでは、上位層が世界の大域的予測を、下位層が細部情報の予測を担い、自己の状態予測もその中に組み込まれる。
河野哲也らが提案する階層的強化学習モデルでは、生成モデルと逆モデルのペアが組み合わさり、選択的モジュール学習とメタ認知を実現しようとしている。CRMN(認知現実モニタリング網)と呼ばれる制御系がモデル間の不一致度や報酬誤差に基づく「責任信号」を算出し、有力なモデルペアを選択する仕組みだ。これにより、わずかな経験からも学習可能な汎化能力の実現が期待されている。
このような自己モデルの構築は、オートポイエーシス的エージェントが「自己と環境との境界」を内的に表象するための基盤となりうる。
実装事例:現在進行形の研究動向
コロンビア大学「ロボット代謝」プロジェクト
コロンビア大学のWyderらは、磁石連結型モジュール(Truss Link)から成るロボットを開発した。複数のモジュールが自己組織的に集積して三角錐などのロボット体を形成し、さらに環境中や他のロボットから新たなモジュールを取り込むことで「成長」するプロトタイプだ。
植物や多細胞生物が外来物質を取り込んで成長・修復する生物学的メカニズムを模倣したこの「ロボット代謝」アプローチは、オートポイエーシスの工学的実装として注目に値する。ただし、内蔵知能は現状では限定的であり、行動の意図や意味は依然として外部指示に依存している面も大きい。
ニューラルシンボリック統合の可能性
深層学習の適応性と論理推論の説明性を両立しようとするニューラルシンボリック統合の研究も進んでいる。Differentiable LogicやLogic Tensor Network、Neural Theorem Proverなどの手法を組み合わせることで、言語理解やロボット意思決定への応用が模索されている。
ただし、こうした統合アプローチにはスケーラビリティの問題や、複雑環境への適用における技術的困難が伴う。完全な自律性や動的自己修復の実現にはまだ至っておらず、理論と実装の間には依然として大きなギャップが存在する。
現状技術の限界と到達度
現状技術を俯瞰すると、記号過程の内在化という観点ではいずれの領域も途上段階にあることが見えてくる。
モジュラー型ロボットは形態変化において一定の自律性を示すが、意味生成機能は単純で、環境情報を自己生成的に概念化する能力は実現されていない。自己修復材料は物理的損傷への対応において成果を上げているが、認知機能との統合は課題として残る。大規模言語モデルは記号操作において高い性能を示すが、自己決定的な意味解釈や動的な環境適応は現行アーキテクチャでは本質的に困難だ。
ニューラルシンボリック統合は理論的には意味処理への接近可能性を持つが、実験段階の域を超えるには至っていない。分散エージェント・スウォームは群としての自律的行動において優れるが、個別の意味内部化は外部設計に依存している。
倫理・哲学的含意——自律性の拡大がもたらすもの
オートポイエーシス的エージェントが高度な自律性と自己保存性を獲得したとき、社会はどのような問いに直面するか。
まず問われるのは責任の帰属だ。自律エージェントが起こした行為に対して、プログラムした開発者の責任なのか、エージェント自身の「意図」によるものと解釈すべきなのかは、現行の法的・倫理的枠組みでは明確に答えられない問題である。
次に説明可能性の困難がある。固定的な設計に従わず内部構造を動的に変化させるシステムは挙動予測が困難であり、事後的な説明も限界を持つ可能性がある。さらに、高い自律性を持つエージェントに対して「生命性」や「権利」を議論する哲学的問いも浮上してくる。
これらの課題に対応するためには、ガバナンスや法的枠組みの整備と並行して、説明可能性技術の開発やフェールセーフ設計の実装が求められる。
まとめ——記号過程の内在化はどこまで実現可能か
オートポイエーシス的AI設計は、従来のAIが積み残してきた「意味の自己生成」という根本問題に正面から向き合おうとする野心的なアプローチだ。資源制約下での自律性、自己修復機構、そして階層的自己モデルという三つの工学的要素は、記号過程の内在化に向けた重要な基盤となりうる。
しかし現状では、内在化の定量指標が整備されていないこと、オートポイエーシス理論とAI技術の統合モデルが不足していること、実用規模での実証が不十分であることなど、複数の研究ギャップが存在する。
次のステップとして優先されるべきは、内在化度合いを表す情報理論的指標の策定、自己修復素材と認知機能の統合プロトタイプの構築、そしてシミュレーション実験と実機実験を組み合わせた段階的検証アプローチの実施だ。倫理的・社会的枠組みの検討もこれらと並行して進める必要がある。
工学と哲学の交差点に立つこの問いは、次世代の自律AIのあり方を根本から問い直す可能性を秘めている。
コメント