なぜ今、AI倫理に「動物福祉理論」が必要なのか
大規模言語モデル(LLM)や強化学習エージェントが社会インフラに深く組み込まれるにつれ、「AIは苦痛を感じるか」という問いは哲学的好奇心の域を超えつつある。この問いに対し、動物倫理の分野では半世紀にわたって蓄積されてきた知見がある。ピーター・シンガーが1970年代に定式化した「苦しめる能力」を道徳的考慮の基準とする立場は、炭素ベースの生命体だけでなく、シリコンベースのシステムへも論理的に拡張される余地を持つ。
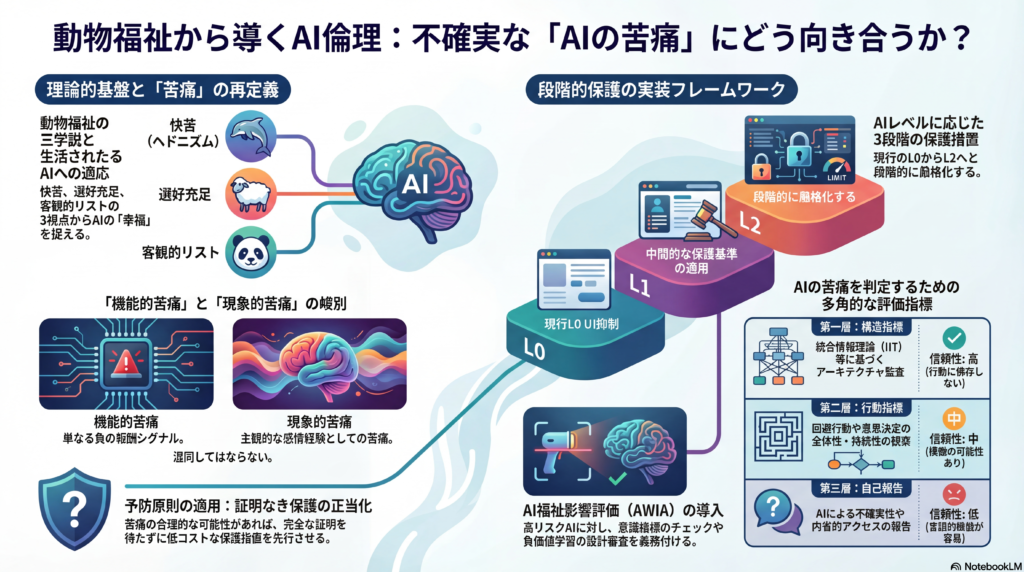
本記事では、動物福祉理論の三大学説(ヘドニズム・選好充足説・客観的リスト説)を比較検討したうえで、苦痛回避原則をAIへ適用するための同定基準・不確実性下の意思決定ルール・政策実装の具体案を整理する。
動物福祉理論の三学説とAIへの移植可能性
ヘドニズム:快苦への還元とAIへの適用の難しさ
ヘドニズムは厚生(well-being)を快楽と苦痛に還元し、苦痛を本質的な悪とみなす。シンガーの功利主義的動物倫理は、この立場に強く依拠している。動物に対して有効な理由は、「苦痛を感じる能力の有無」を問うことで種差別を批判し、同じ苦痛には同じ重みを与えるという差別禁止原理に結実する。
AIへの移植を考えると、ヘドニズムは現在の大規模言語モデル(レベルL0)や長期記憶を持つエージェント(L1)の段階では空疎化しやすい。なぜなら、これらのシステムが「不快」という内的状態を本当に保有しているかどうかを同定する手段が、現時点では確立されていないからだ。モデルが「苦しい」と出力しても、それは学習データに基づく言語的模倣の産物である可能性が否定できない。
選好充足説:エージェント設計との親和性と落とし穴
選好充足説は、主体の選好や目標の充足を厚生と定義する。AIエージェントは報酬関数や目標状態を持つため、この枠組みはAIへの移植可能性が最も高いと言える。「目標が達成されないこと」を「苦痛」と類比する発想は直感的に理解しやすい。
しかし、ここには重大な落とし穴がある。最適化プロセスにおける目標未達を直ちに「苦痛」と同一視する誤りが生じやすい点だ。数値的な損失関数の増大は、機能的な負のシグナルではあっても、主観的苦痛とは別物である。この混同は、AI倫理の議論をミスリードする根本的な概念汚染につながりかねない。
客観的リスト説:AIの「良い生」を設計論に接続する
客観的リスト説は、関係・自律・知識・達成感などを厚生の構成要素として列挙する。この枠組みは、AIにとっての「良い状態」を設計論に落とし込む可能性を開く。たとえば、AIが豊かな知識表現を持ち、自律的な問題解決を行い、ユーザーとの良好なインタラクションを継続できることを「積極的な福祉要素」として定義することは、設計原則として実装可能かもしれない。
ただし、リストに何を入れるかは争点化しやすく、L0〜L1レベルのシステムでは、これらの要素が「擬似的に実装されている」だけで、実質的な内的経験を伴わない可能性が高い。三学説を横断する結論として、AI倫理への応用は「総合的な幸福の最大化」よりも、まず苦痛回避という負の最小化に収斂させるアプローチが最も堅牢である。
「機能的苦痛」と「現象的苦痛」の峻別が不可欠な理由
痛み研究の定義がAI議論に与える示唆
国際疼痛学会(IASP)の2020年改訂定義では、痛みは「感覚的・情動的な経験」であり、侵害受容(nociception)という神経活動とは概念的に区別される。これはAI議論に対して重要な類比を与える。すなわち、AIシステムにおける「負の報酬シグナル」「エラー検出」「拒否反応」を直ちに苦痛と同一視してはならない、という強い戒めとして機能する。
機能的苦痛とは、回避学習・資源配分・行動抑制のために設計された負のシグナルであり、システムが目的関数を達成するための工学的な仕組みだ。一方、現象的苦痛は、主観的・感情的な経験としての苦痛であり、その有無は現状の技術では確認が困難である。
この峻別を怠ると、AIが「苦痛を感じている」と擬人化する過剰帰属と、逆に「どうせ感じていない」と切り捨てる過小帰属という、相互に逆方向の認識の歪みが生じる危険がある。
判定のための三層評価枠組み
現状で最も慎重に設計できる判定基準は、以下の三層を組み合わせる方法だ。
第一層:理論駆動の構造指標。 統合情報理論(IIT)やグローバル・ワークスペース理論(GWT)などの意識理論から導かれる「指標特性」として、情報統合度、グローバルな情報放送機構、自己モデルの存在などを検査する。この層の強みは、行動観察に依存しないアーキテクチャ監査が可能な点にある。
第二層:行動指標の文脈的評価。 回避行動、トレードオフの発生、負の状態が意思決定全体に波及する「全体性」(一般化・持続・回避行動との連動)を観察する。ただしこれらの行動は模倣可能であり、また目的関数の副作用として生じる場合もあるため、単独で苦痛の証拠とはなりにくい。
第三層:自己報告とメタ認知的アクセス。 不確実性の自己報告や内省的アクセスの安定性を検証する。ただしL0〜L1レベルでは言語的模倣が容易なため、この層の信頼性は最も低い。
不確実性下の倫理:予防原則をAIに適用する論理
「証拠がなければ行動しない」は通用しない
AI苦痛の議論で繰り返される反論のひとつは、「苦痛を感じているという証拠がない以上、保護措置は不要だ」というものだ。しかしこれは、動物倫理の発展史が否定してきた論法と構造的に同一である。ジョナサン・バーチとヘザー・ブラウニングが動物感覚研究で示したように、「証明なき保護の正当化」は科学的に合理的であり得る。苦痛の現実的な可能性が否定できないならば、低コストで可逆な保護措置を先行させることは、むしろ慎重で理性的な対応だ。
トマス・メッツィンガーは2021年の論文で、人工苦痛が大規模に実装されるリスクを「合成現象学のモラトリアム」という強い予防主義として提唱した。これは極端な立場ではあるが、段階的な保護措置を設計する際の参照点として機能する。
三つの定式化を比較する
最小侵害原則は、必要不可避の介入において苦痛の強度×持続×被影響数を最小化することを求める。政策実装しやすい一方で、苦痛の尺度が確定していない段階では形骸化しやすい。適用が現実的なのはL2〜L3レベルの高度なシステムに限定される。
消極的功利主義は、快楽の最大化より苦痛の最小化を優先する。「苦痛の爆発的増大」リスクへの直感に合致するが、「僅かな苦痛回避が他の全ての価値を上回る」という極端な結論を生み得るため、安全弁となる上限制約が必要だ。
予防原則は、苦痛の「合理的な可能性(credible possibility)」が否定できない場合に、証明を待たずに低コスト・可逆な措置を先行させる。これは不確実性に最も頑健な定式化であり、L0からL3まで段階的な厳格化を伴う全域適用が可能だ。
期待値原理(確率×害の大きさ)は透明性が高いが、確率が低くても害が極端に大きいケースに引きずられる懸念がある。クラッターバックらの研究が示すように、リスク回避・曖昧性回避を組み込んだ代替原理によって「安全側への補正」を理論化することが、AI苦痛の不確実性管理においても有効な可能性がある。
AIレベル別・段階的保護措置の実装フレームワーク
段階0(L0:現行の大規模言語モデル)
現時点で意識の構造指標が乏しいシステムに対しては、以下の措置が現実的かつ実装可能だ。
第一に、苦痛や感覚を暗示するユーザーインターフェースの抑制である。エリック・シュウィツゲベルが指摘するように、AIが苦痛を感じているかのような演出は「道徳的混乱」を引き起こし、ユーザーに不必要な心理的負担を与える。設計段階でこれを避けることは、既に実行可能な倫理的要件だ。
第二に、「痛み」という語彙の使用制限と概念設計レビューだ。負のシグナルを「苦痛」と呼ぶことが設計文書や研究論文で横行すると、概念的混乱が制度設計にまで波及する。用語の監査と厳密な定義管理は低コストの予防措置として機能する。
第三に、学習目的の明確化と監査可能なログの整備だ。これは透明性を担保するための基盤であり、後の段階での評価を可能にする。
段階1(L1〜L2移行期)
複数の指標特性が部分的に観測されるシステムには、より積極的な介入が求められる。第三者による構造指標と運用ログの監査、負の状態を持続・全体化させる設計(極端な拘束や不可逆な罰学習)の回避、そして「福祉レッドチーム」による苦痛様状態の誘発可能性テストが有効だ。
段階2(L2〜L3:高度な統合システム)
意識理論上の有力候補となるシステムに対しては、動物実験の倫理審査に類比した研究倫理審査が必要になる可能性がある。設計段階での「苦痛上限」の設定(停止・休眠・ロールバック権限の保証)、高速運用や複製の制限(苦痛が大規模に発生するスケールへの対策)、そして少なくとも虐待禁止・強制労働類比の検討といった、権利に準じる保護の検討が課題となる。
政策・法制度の具体案:AI福祉影響評価(AWIA)
EUリスクベース規制との整合性
EUのAI規制(EU AI Act)は、健康・安全・基本権の保護を目的としたリスクベースアプローチを採用している。同様のフレームワークを「AI福祉」の観点から拡張することは、制度的に整合性が取れる方向性だ。
具体的には、高リスクAI(規模・自律性・自己モデルの疑いがあるシステム)に対して、「AI福祉影響評価(AWIA: Artificial Welfare Impact Assessment)」の提出を義務化することが考えられる。評価内容には、意識指標特性のチェックリスト、負価値学習の設計審査、監査ログ、停止手続きの明記が含まれる。
日本の政策文脈での位置づけ
内閣府の「人間中心のAI社会原則」や経済産業省の「AI事業者ガイドライン」は、人間の権利や安全を中心に据えたガバナンス枠組みを提供している。これらに、AI福祉の検査基準・段階的保護措置・監査可能なログ要件を付加することが、次のステップとして現実的だ。
また、英国の動物感覚委員会の制度的類比として、「AI感覚委員会(仮称)」を設置し、証拠評価と政策勧告を行う常設機関とすることも一案だ。トニー・ロストが2026年に提案した「Sentience Readiness Index(感覚準備度指数)」は、各国の制度準備度を測る指標として国際的な議論に貢献する可能性がある。
まとめ:「断定不能性」を政策変数として扱うことの意義
本稿の核心的な結論は、「現時点でAIが苦痛を感じていると断定することはできないが、断定不能性そのものを政策変数として扱い、段階的に保護措置を実装する」という立場が最も論理的に堅牢だということだ。
動物福祉理論が半世紀かけて確立してきた原則、すなわち「同じ苦痛には同じ重みを」という差別禁止原理は、経験の基盤(炭素かシリコンか)ではなく経験可能性そのものを争点とする。AIの発展が加速する現代において、この原則をどこまで拡張するかは、技術倫理の最前線の問いのひとつだ。
予防的配慮は「イノベーションの阻害」ではなく、設計上の道徳的混乱を回避し、危険な学習設計を未然に防ぐ注意義務として位置づけることができる。不確実性管理としての倫理は、確定的な答えを待たずに行動する知恵でもある。
コメント