なぜ今、量子意味論と概念ブレンディングの統合が注目されるのか
認知科学・言語学・量子情報理論という、一見交わらない三つの領域が、近年「意味の生成プロセス」という共通テーマのもとで接近しつつあります。その中心に位置するのが、メンタルスペース理論と量子意味論を橋渡しする「量子化ブレンディング」の枠組みです。
本記事では、この統合モデルの全体像を整理し、(1)理論の数学的基礎、(2)具体的な計算例、(3)実験検証の可能性と限界、という三つの柱に沿って解説します。「脳が本当に量子計算をしている」という主張ではなく、量子的な数理を道具として意味現象を記述するという「量子ライク(quantum-like)アプローチ」がその立場です。
メンタルスペース理論の基本:談話の中で意味はどう生まれるか
スペースとマッピングという考え方
Gilles Fauconnierが提唱したメンタルスペース理論は、私たちが会話や思考の中で「部分的な構造体(スペース)」をオンラインに構築し、それらを結びつけることで意味を動的に生成していくという枠組みです。たとえば「もし私が鳥だったら」という反事実条件文を理解するとき、私たちは現実スペースとは別に「鳥としての私」というスペースを一時的に作り、そこで推論を展開します。
この理論の核心は「スペース間のマッピング(対応づけ)が意味構成の中心コンポーネントである」という点です。参照・前提・条件文・態度報告といった言語現象は、複数スペース間のリンクによって説明されます。
概念ブレンディング:創発的意味の生成
概念ブレンディング(概念統合)理論は、二つ以上の入力スペース(input spaces)に加え、両者に共通する総称スペース(generic space)と、それらが統合されたブレンド(blended space)から構成される「統合ネットワーク」を描きます。
重要なのは、ブレンドには入力スペースには存在しなかった**創発的構造(emergent structure)**が生まれる点です。「時間はお金だ」という比喩が成立するとき、「時間を節約する」「時間を投資する」という推論は、TIMEスペースにもMONEYスペースにも単独では存在せず、ブレンドの中で初めて生成されます。
理論の洗練とともに「最適性原理(governing principles)」として、統合・位相・ウェブ・関連性・アンパッキングなどの制約が提案され、どのブレンドが「良いブレンド」かを評価する枠組みが整備されてきました。
量子意味論の数学的基礎:状態・測定・干渉を意味に使う
ヒルベルト空間・密度行列・ボルン則
量子意味論の基礎は、言語・概念の意味表現をヒルベルト空間上のベクトル(純粋状態)または密度行列(混合状態)として扱う点にあります。密度行列 ρ は半正定値で tr(ρ)=1 を満たす演算子であり、観測(判断・推論)は射影測定またはPOVMとして表現されます。確率はボルン則によって与えられます。
この枠組みを意味論に適用する動機は、文脈依存・順序効果・「合理性公理」からの逸脱といった現象を、古典確率論だけでは一貫して説明しにくいケースがあるからです。量子認知(quantum cognition)の研究では、「確実性原理(sure-thing principle)」の破れなどをヒルベルト空間モデルで説明できることが示されており、同等のマルコフモデルでは困難とされています。
干渉効果:文脈が確率を変える仕組み
量子モデルの特徴的な予測のひとつが**干渉(interference)**です。純粋状態の重ね合わせでは、古典的な「確率の加法性」が成り立たず、位相(phase)パラメータによって確率が古典的期待値より高くなったり低くなったりします。
これを意味論に応用すると、「同じ入力概念でも文脈の整合のさせ方(位相)によって、ある性質の賦与確率が大きく変わる」という現象を定式化できます。比喩理解における文脈効果や、語の多義性の解消プロセスは、この干渉モデルと親和性が高いとされています。
エンタングルメント:意味的結合の定量化
合成系の状態 ρAB が ρA⊗ρB の形に分解できないとき、その系は エンタングル(量子もつれ)していると言います。概念結合の文脈では、ある概念Aとある概念Bが独立して意味を持つのではなく、不可分な相関をもつ状態として表現されることを意味します。
先行研究では、概念組み合わせ実験においてベル不等式の破れに相当する非古典的構造が観測され、エンタングルメントとして分析する試みが報告されています。これは本統合モデルの中心的な外的根拠のひとつとなっています。
量子化ブレンディングの形式的枠組み
量子メンタルスペースの定義
統合モデルでは、各入力メンタルスペース S を三つ組 QMS(S):=(HS, ρS, OS)
で表します。HS は意味特徴のヒルベルト空間(有限次元複素空間)、ρS はその上の密度行列、OS はそのスペースで問われうる性質判断・推論を表す観測作用素族です。
この設計において、メンタルスペース理論でいう「プロファイリング(前景化)」は、特定の射影作用素 Pprofile として表現されます。文脈の変化に伴うプロファイリングの切り替えは、**測定更新(射影+正規化)または一般の量子チャネル(CPTP写像)**として記述できます。
スペース間マッピングの量子的表現
メンタルスペース間のマッピング(意味の移送)は、等長写像 VS→T:HS→HT または一般のCPTP写像 ES→T として定式化されます。Kraus表現 E(ρ)=i∑KiρKi†
を用いれば、環境との相互作用(文脈による解釈の変容)を含む開放系的なダイナミクスとして表現できます。これは「スペース間マッピングが意味構成の中心コンポーネントである」というフォコニエの立場を、状態遷移の言語で書き直したものです。
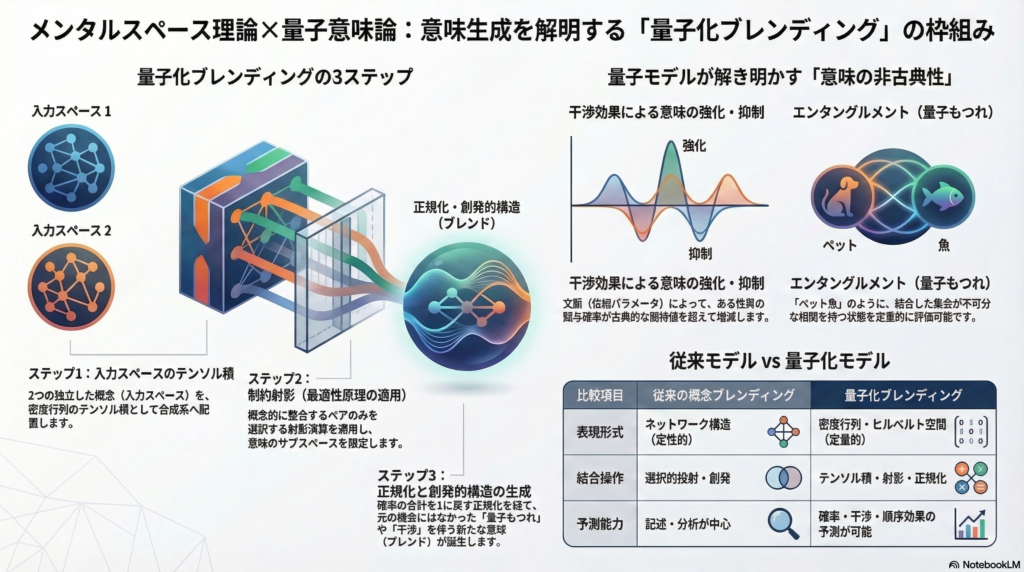
ブレンド生成の量子操作:テンソル積・射影・正規化
二つの入力スペース S1,S2 に対して、合成空間を H=HS1⊗HS2 とし、入力状態を ρin=ρS1⊗ρS2(テンソル積)とします。ブレンド生成は次のステップで記述されます。
- 文脈変換: 量子チャネル B を適用して入力状態を変換する
- 制約射影: 「最適性原理」に相当する射影 PB を適用し、許容される意味サブスペースへ投影する
- 正規化: ρB=ρ~B/tr(ρ~B) でトレースを1に戻す
- (必要に応じて)部分トレース: 各入力スペースの縮約状態 ρSi′ を読み出す
この形式は、ユニタリ変換(可逆な文脈変換)と非ユニタリ更新(選択的投射)を統一的に扱えるという利点があります。環境を含む拡張ユニタリとして書けば、量子チャネルの標準的なユニタリ実現とも整合します。
具体的な計算例:比喩とエンタングルメント
例1:「時間はお金だ」における干渉
TIMEとMONEYの入力スペースをそれぞれ「節約可能(∣p⟩)」「節約不可能(∣pˉ⟩)」の2次元ヒルベルト空間で表します。 ∣T⟩=0.3∣p⟩+0.7∣pˉ⟩,∣M⟩=0.9∣p⟩+0.1∣pˉ⟩
ブレンドを位相 ϕ を持つ重ね合わせ ∣Bϕ⟩∝∣T⟩+eiϕ∣M⟩ として定義すると、ϕ=0(構成的干渉)のとき Pr0(p)≈0.628 となります。古典的に二概念を均等に混合した場合の Prmix(p)=0.6 より高くなることが、干渉効果として表れています。一方 ϕ=π(破壊的干渉)では Prπ(p)≈0.373 と、同じ入力状態から大きく異なる予測が得られます。この「位相」パラメータは、談話文脈や語用論的含意がどの推論を強め・弱めるかを凝縮した変数として解釈できます。
例2:「ペット魚」のテンソル積・射影・エンタングルメント計算
PET概念の基底を「愛玩(∣C⟩)・食用(∣F⟩)」、FISH概念の基底を「水槽(∣A⟩)・食事(∣M⟩)」とし、テンソル積で合成した後、「整合的ペアだけを選ぶ」制約射影 PB=∣CA⟩⟨CA∣+∣FM⟩⟨FM∣
を適用すると、ブレンド後の状態は∣ΨB⟩=97∣CA⟩+92∣FM⟩
となります。これはシュミット係数が2つ非零であるためエンタングルした純粋状態です。部分トレースにより各縮約状態は混合になり、エンタングルメントエントロピーは約0.764ビットと定量化されます。
さらに、射影前には Pr(A)=0.6 だった水槽特徴の確率が、射影後には 7/9≈0.778 に上昇します。「ペット魚」ブレンドが魚を”水槽の対象”へ引き寄せる文脈効果が、量子更新として自然に表現されています。
従来モデルとの比較:何が変わり、何が難しいのか
| 比較項目 | 従来の概念ブレンディング | 量子化モデル |
|---|---|---|
| 表現形式 | スペース・要素・関係のネットワーク | 密度行列・ヒルベルト空間・観測作用素族 |
| 結合操作 | 選択的投射+創発構造+最適性原理 | テンソル積→量子チャネル→射影→正規化 |
| 確率的予測 | 別途設計が必要 | ボルン則で直接定量予測が可能 |
| 説明できる現象 | 創発・圧縮・整合性(定性的) | 干渉・順序効果・文脈依存確率(定量的) |
| 実験検証 | 質的分析・事例説明が中心 | 反応確率・解釈遷移を直接モデルフィット可能 |
最大の利点は、文脈依存・干渉・順序効果・エンタングルメントを単一のフォーマリズムで扱える点です。一方、表現の同定可能性(ヒルベルト空間の次元や基底選択が恣意的になりうる)や、「一度確定した解釈の維持」現象への対応といった課題も存在します。
実験検証の可能性:量子化ブレンディングを試す方法
量子化ブレンディングを実証的に評価するには、「物語的説明」ではなく「定量的予測の精度」で競う必要があります。具体的には以下の三系統の実験設計が考えられます。
性質判断・典型性判断の確率予測: 比喩・新奇複合語・ジョーク等のブレンド刺激に対して、ある性質の賦与確率を多数評定させ、量子モデル(干渉項・射影制約)と古典モデル(独立混合仮定)とを情報量基準(AIC/BICなど)で比較します。
順序効果・文脈更新の予測: 同一刺激を異なる質問順序で提示し、回答分布の非可換性を検証します。量子認知では順序効果が中心的な適用対象として研究されており、実験デザインの蓄積が参照できます。
解釈の不定性と読解過程: 文章理解において複数解釈が共存する不定性を「量子的重ね合わせ」として扱い、「ブレンドが確定していく過程=測定列」として設計します。比喩や暗黙含意を用いた読解実験との接続が有望です。
限界と課題:量子化ブレンディングが直面する問題
表現の同定可能性: ヒルベルト空間の次元・基底・射影サブスペースの定義が恣意的になりやすく、「何でも説明できる」方向へ傾くリスクがあります。パラメータを透明に公開し、事前登録型の実験設計で評価することが重要です。
量子ヒルベルト空間モデルの適用限界: 標準的な量子ヒルベルト空間モデルでは、「順序効果」と「反応再現性」が同時に生じる状況の扱いが難しいという指摘があります。より一般化された枠組み(GTRモデル等)の必要性も議論されています。
構造と分布の二層統合: 概念ブレンディングの伝統はフレーム・役割・関係の構造保存を重視しますが、量子状態は統計的予測に強い一方で関係構造の可読性が失われやすい点があります。圏論・代数的記号論の形式化(Goguen系のpushoutモデル)を制約射影の生成規則として組み込む設計が、このギャップを埋める鍵となります。
まとめ:量子化ブレンディングが開く可能性
本記事では、メンタルスペース理論・概念ブレンディング理論と量子意味論を統合する「量子化ブレンディング」の枠組みを整理しました。
核心は三点です。第一に、入力メンタルスペースを密度行列で表現し、第二に、ブレンド生成をテンソル積→量子チャネル→射影→正規化の操作列として定義し、第三に、ブレンド後状態のエンタングルメントエントロピーで意味的結合の強さを定量化するという構成です。
玩具例(「時間はお金だ」「ペット魚」)の数値計算が示す通り、この枠組みは干渉効果・文脈依存確率・エンタングルメントを統一的に扱える可能性を持ちます。ただし、表現の恣意性や構造情報の損失といった課題は残っており、今後の理論的・実証的な精緻化が求められます。
コメント