なぜ外部メモリの検索・抽象化が重要なのか
大規模言語モデル(LLM)には「コンテキスト長の制限」「知識の鮮度問題」「根拠の説明責任」という三つの構造的な制約が存在する。これらを補うために、モデルのパラメータ外に存在する大規模な情報源——ドキュメント集合、ナレッジベース、長期対話履歴——にアクセスし、必要な知識を取り出して利用可能な形に変換する技術が急速に重要性を増している。
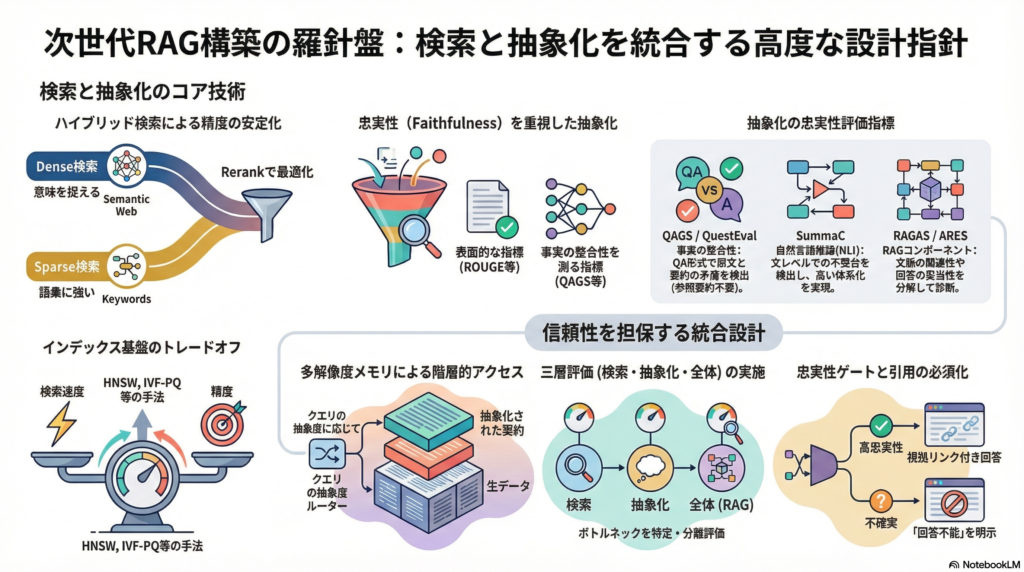
その代表的な枠組みが**RAG(Retrieval-Augmented Generation:検索拡張生成)**だ。RAGは「検索(retrieval)」と「生成(generation)」を組み合わせることで、モデルに非パラメトリックな知識アクセスを与える。ただし、RAGの性能は「検索の一般化能力」「複数文書にわたる証拠統合」「抽象化の忠実性(faithfulness)」に強く依存しており、これらを個別に最適化するだけでは不十分だ。
本記事では、検索アルゴリズムの多様な手法と、抽象化技術の課題・評価指標を体系的に整理したうえで、両者を統合した実装可能なアーキテクチャ設計を提示する。
検索アルゴリズムの全体像:sparse・dense・hybrid
dense bi-encoderとlearned sparse:二つの主流
外部メモリからの検索手法は、大きく「スパース(sparse)」と「デンス(dense)」に分類できる。
Dense bi-encoder(DPR、Contriever、E5) は、クエリと文書をそれぞれ独立にエンコードし、ベクトル間の内積・距離で近似最近傍検索(ANN)を行う方式だ。DPR(Dense Passage Retrieval)はBM25に対してtop-20の検索精度を大きく改善できることを示した。ただし、教師ありデータを使って学習したモデルは分布外(OOD)ドメインで性能が落ちやすく、ContrieverやE5はコントラスト学習・弱教師あり学習でゼロショット汎化を狙った設計になっている。
Learned sparse手法(SPLADE、uniCOIL、DeepImpact) は、入力から語彙次元のスパースベクトルを学習し、倒立索引で高速検索する方式だ。BM25的な完全一致の強みを保ちながら意味拡張を学習することで、OODで相対的に頑健になりやすい傾向があり、SPLADEv2はBEIR(多様なIRタスクのゼロショット評価ベンチマーク)で改善を報告している。
late interactionによる精度と効率のバランス
ColBERT / ColBERTv2 は「late interaction」という独自のアプローチをとる。クエリと文書を独立にBERTエンコードしたうえで、トークンレベルの表現間でMaxSim演算を行いスコアを算出する。cross-encoderのような全トークン同士の相互作用は計算コストが高すぎるが、ColBERTはこれを後段の軽い演算で代替し、曖昧クエリや語彙ミスマッチに対してdense単一ベクトルより高い表現力を発揮する。ColBERTv2は残差圧縮と改善した学習戦略で品質とストレージコストを両立させた。
多段・ハイブリッドパイプラインの安定性
実用上「外しにくい」構成として定評があるのが、BM25またはdense系でfirst-stage候補を生成し、cross-encoderやlate interactionでrerankする多段パイプラインだ。BEIRはrerankの有効性を示しつつ、その計算コストの高さも強調している。クエリの抽象度や計算予算に応じてfirst-stageを切り替えられる柔軟性があり、OODでハイブリッドが安定しやすいという特性がある。
生成と検索を統合するRAG系手法
RAG は文書を潜在変数として周辺化する定式化で生成と検索を結合する。FiD(Fusion-in-Decoder) は複数文書を個別にエンコードし、decoderで統合する方式で文書数に線形なコストがある。Self-RAG は「必要な時だけretrieval」を学習し、自己反省トークンで品質・事実性・引用精度の改善を実現した。Atlas はretrieval-augmented LMの設計と事前学習を組み合わせ、索引更新によって知識を最新化できる点が重要な特徴だ。
インデックス基盤:ANNと圧縮の選択
FAISS・HNSW・DiskANN・ScaNN
検索性能はモデルだけでなく、インデックス(近似探索・圧縮・ディスク常駐) に強く支配される。
- HNSW:階層小世界グラフ探索で対数的なスケーリングを実現。RAM常駐が望ましく、増分構築が可能。
- IVF-PQ(IVFADC系):粗クラスタで候補を絞り、Product Quantizationで圧縮・近似距離計算。メモリ節約に優れる。
- FAISS:flat/IVF/PQ/HNSW等の多様な索引とGPU実装を提供。複数GPU構成(IndexShards/IndexReplicas)にも対応。
- ScaNN:非等方量子化(anisotropic VQ)を中心にspeed–accuracyトレードオフを最適化。
- DiskANN:SSDを活用してRAM制約を緩和し、単一ワークステーションで大規模スケールの近似探索を実現する設計。
中規模研究環境でのメモリ概算として、次元数d=768、ベクトル数N=5,000万、float16(2バイト)で保存する場合、単純計算で約76.8GBが必要となる。RAM 64GBでは厳しく、PQで圧縮すれば数GBオーダーまで削減できる可能性がある。ただし圧縮は検索精度との明確なトレードオフを伴う。
抽象化アルゴリズム:要約の忠実性をどう確保するか
抽出型・生成型・統合型の特徴
抽象化(要約・一般化)には大きく三つのアプローチがある。
抽出型は原文の文やスパンを選ぶため忠実性が高いが、ユーザー意図に合わせた一般化が難しい。生成型は短く一般化された表現を作れる一方、「流暢だが事実不整合」な出力が頻発する問題がある。FRANKはこの誤り類型と評価の難しさを体系化しており、忠実性評価が不可欠であることを強調する。**統合型(メタ表現)**は複数ソースから同一概念・エンティティを同定して統合する方向で、GraphRAGが”構造+要約”への変換を実装例として示している。
軽量適応:LoRAとPrefix-tuning
計算資源が限られた中規模研究環境で実装可能性を高めるには、PEFT(Parameter-Efficient Fine-Tuning) の活用が現実的だ。LoRA は低ランク行列を注入することで推論レイテンシを増やさず適応する。Prefix-tuning は”連続プロンプト”を学習し生成タスクを軽量に制御する。また、FLAN(instruction tuning)は自然言語指示による多タスク微調整でゼロショット性能を大きく改善できる可能性を示した。
検索側では、HyDE(Hypothetical Document Embeddings) がLLMに”仮想文書”を生成させ、その埋め込みで実コーパス近傍を探索することでゼロショットdense retrievalを改善する枠組みを提示している。
抽象化の評価指標:忠実性に鈍感なROUGEだけでは不十分
| 指標 | 測定対象 | 参照要約 | 主な特徴 |
|---|---|---|---|
| ROUGE | n-gram重なり | 必要 | 低コストだが忠実性に鈍感 |
| BERTScore | 文脈埋め込み類似 | 必要 | 意味類似を捉えやすい |
| QAGS | QAで原文・要約の整合測定 | 不要 | 事実整合に焦点 |
| QuestEval | QAベースの多次元評価 | 不要 | 参照なしで汎用的 |
| SummaC | NLIによる不整合検出 | 不要 | NLIベースの体系化 |
| FActScore | 原子factの支持率 | 外部知識 | 長文生成の細粒度評価 |
| RAGAS / ARES | RAGのコンポーネント評価 | 不要 | RAG開発サイクル短縮 |
ROUGEとBERTScoreは標準指標だが忠実性検出が目的外であるため、FRANK・QAGS・SummaC・FActScoreなどを開発の回帰テストに組み込むことが実務的に重要だ。
統合アーキテクチャの設計:二つの提案
提案A:階層的リトリーバ+多解像度メモリ
外部メモリを「生データ(チャンク)」と「抽象メモリ(文書要約・トピック要約・コミュニティ要約)」の多解像度で併存させ、クエリの抽象度に応じて探索対象を切り替える設計だ。
処理フローは次のようになる。
- Query Routerがクエリの抽象度・意図を推定する
- 具体的・事実寄りのクエリはdense/learned-sparseでfirst-stage検索
- 抽象的・俯瞰的なクエリはグラフ/トピック要約索引(GraphRAG的)を参照
- 候補をlate interactionでrerank、重複除去・矛盾検出
- 生成的抽象化(RAG/FiD系)で統合出力
- 忠実性チェック(QAGS/SummaC/FActScore等)を通過した出力のみ最終化
- 合格した要約をMemory Consolidatorが多解像度メモリに反映
実装上の注意点として、(a) 抽象メモリの更新頻度設計と根拠リンク(どのチャンク由来か)の必須化、(b) セクション見出し・構造を保持したセマンティックチャンクの採用、(c) retrieval失敗を抽象化で隠さない不確実性の明示、が特に重要だ。
提案B:学習型インデックス+メタ学習的抽象化ポリシー
提案Aが”パイプライン設計”に重心を置くのに対し、提案Bはインデックス自体を学習対象に寄せる方向だ。Neural Corpus Indexerの考え方(固定索引と検索を分離する従来設計の限界を指摘し、学習とindexingを統合)と、Self-RAGの”retrieval on demand”制御を組み合わせる。
Controllerが「浅い検索(learned index/粗い量子化)」か「深い検索(ANN+rerank)」かを方策として選択し、生成器(LLM)とcritic/judgeが出力を評価して不十分であれば再検索を行う。Memory Managerが保存先の粒度(ホット/ウォーム/コールド)を決定する。
学習設計の要点は、(a) 既存retriever/rerankerで疑似教師信号を生成してdistillation、(b) “正答性+忠実性+推論コスト”の多目的コスト関数、(c) LoRA/Prefix-tuningで計算資源に合わせた軽量適応、だ。
A vs B の比較
| 観点 | 提案A(多解像度メモリ) | 提案B(学習型+方策) |
|---|---|---|
| 主眼 | 説明責任と外しにくさ | 索引・制御を最適化 |
| 学習コスト | 必要部分のみPEFTで軽量 | learned indexで重い |
| 更新性 | バッチ再要約で管理しやすい | オンライン更新の整合が難所 |
| 適用しやすさ | 研究〜プロダクト移行が比較的容易 | 研究投資型・大規模データで有利 |
評価計画と推奨ベンチマーク
三層評価の設計
評価は「retrieval単体」「抽象化単体」「RAG全体」の三層に分けることで、ボトルネックを明確に切り分けられる。
- Retrieval:BEIR(OODゼロショット評価)、KILT(統一知識ソースでの横断評価)。指標はRecall@k、MRR、nDCG@10。
- 抽象化:ROUGE/BERTScoreをベースラインに、QAGS/SummaC/FActScoreで忠実性を補完。日本語要約にはXL-Sumの日本語分割が現実的な選択肢となる。
- RAG全体:RAGAS/ARESでcontext relevance・faithfulness・回答関連性をコンポーネントごとに分解診断。
多言語・日本語評価には、MIRACL(18言語のad hoc retrieval)、JaQuAD・JSQuAD(日本語読解QA)を組み合わせることを推奨する。
小規模プロトタイプの進め方
- 日本語Wikipediaをセクション単位でチャンク化(スナップショット固定を推奨)
- dense embeddingはE5系(多言語)、sparseはBM25をbaselineとして用意
- FAISS(HNSWとIVF-PQの2系統)で検索速度・recallを比較
- MIRACL日本語でRetrieval評価
- LoRAでXL-Sum日本語分割に軽量微調整して抽象化を評価
- QAGS/SummaC等で忠実性の逸脱率を推定
- RAGAS/ARESでRAG全体を診断
再現性のため、スナップショットID・チャンク規則・embeddingモデルとバージョン・索引パラメータ・乱数seed・ハードウェア仕様を実験ログとして必ず保存する。
リスクと倫理的配慮
幻覚・誤情報への対策
RAG出力の誤情報の主因は、retrieval失敗、根拠間の矛盾、LLMによる補完(hallucination)の三つだ。Self-RAGが示すように、”必要な時だけretrieval”する制御と自己反省は品質改善に有効である可能性がある。実装上は(a)出力に引用(どのチャンク由来か)を必須化、(b)忠実性メトリクスを開発・回帰テストに組み込む、(c)根拠不足を返せる出力仕様を設計する、ことが基本対策となる。
プライバシーと知的財産
RAGはprivate dataを扱う手段として普及したが、検索DB・プロンプト・出力の相互作用から新しいプライバシーリスクが生じうる。埋め込みへのmembership inference攻撃の脆弱性も報告されており、PII前処理・権限分離・監査ログを ingestionパイプラインに組み込む設計が不可欠だ。著作物を含む外部メモリを扱う場合は、スニペット長の制御・原文へのリンク・データライネージの追跡が推奨される。
バイアスとドメイン特化の課題
外部メモリは”データの偏り”をそのまま反映する。BEIRが示すようにOOD一般化の保証は弱く、ドメイン・言語・トピックを跨ぐベンチマークによる定期監査と、出力への不確実性提示が必要だ。医療・法務などの高リスク領域では、忠実性評価を”必須ゲート”に格上げし、引用必須・推測禁止などの出力仕様を厳格化することが求められる。
まとめ
本記事では、外部メモリの検索・抽象化アルゴリズム高度化について、以下の観点を整理した。
- 検索アルゴリズム:dense bi-encoder(DPR/E5)、learned sparse(SPLADE)、late interaction(ColBERT)、多段ハイブリッドのそれぞれに固有の強みとOOD課題がある
- インデックス基盤:FAISS・DiskANN・ScaNN等の選択がシステム性能を大きく左右し、圧縮はprecisionとのトレードオフを伴う
- 抽象化の忠実性:ROUGEだけでは不十分で、QAGS・SummaC・FActScore等の忠実性評価を開発サイクルに組み込むことが重要
- 統合アーキテクチャ:多解像度メモリ設計(提案A)は説明責任と実装容易性に優れ、学習型インデックス+方策設計(提案B)は研究投資型で大規模データで真価を発揮する
- 評価:三層評価(retrieval/抽象化/RAG全体)とBEIR・KILT・MIRACLの組み合わせが再現性高い評価プロトコルとなる
検索と抽象化を”評価可能な形で”結合し、根拠リンクと忠実性ゲートを設計に組み込むことが、実運用で信頼性の高いRAGシステムを構築するための核心といえる。
コメント