量子ウォークとLLMをつなぐ問いの意味
量子認知の研究が近年注目を集めている。脳の中で量子効果が起きているという主張ではなく、「量子形式の数理モデルを認知現象の記述に適用する」という研究計画として、文脈依存性・順序効果・干渉・判断後の状態変化を扱う枠組みが蓄積されている。
一方、GPT型の大規模言語モデル(LLM)は自己回帰生成によってテキストを1トークンずつ出力し、その過程で内部状態を更新する。この「状態を持ち、観測(トークン生成)のたびに状態が変わる」という構造は、量子開放系の更新法則と表面上よく似ている。
では、この類似はどこまで厳密なのか。本記事では、量子マルコフ・開放系モデルとGPT型LLMの自己回帰生成を形式的に比較し、対応が成立する範囲と成立しない範囲を具体的な数式と数値例で整理する。量子認知の応用を目指す研究者や、LLMの内部構造を別の理論枠組みから理解しようとする技術者にとって、実用的な地図となることを目指す。
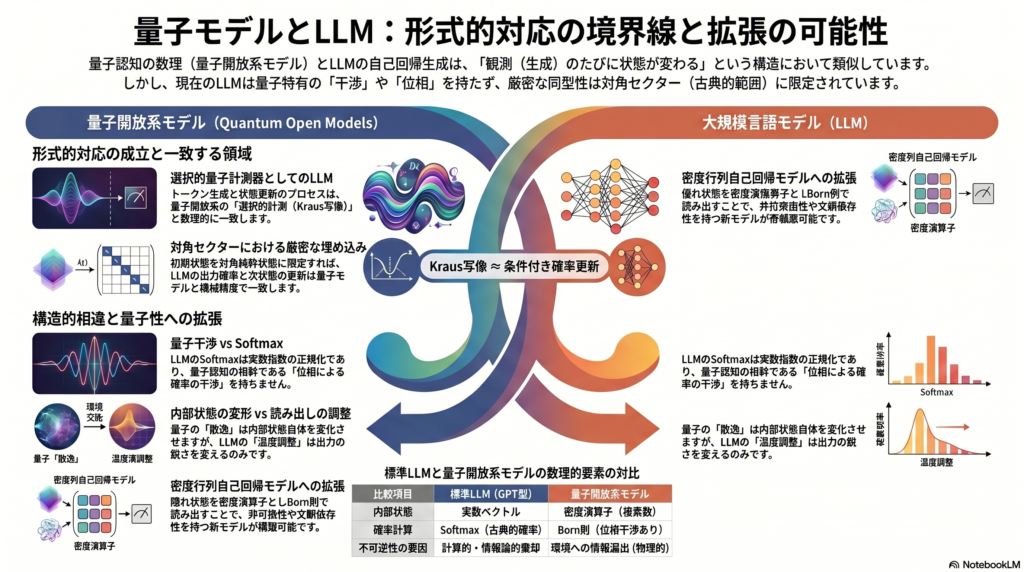
比較対象:量子側とLLM側の基礎構造
量子側:状態・更新・観測の三層構造
量子開放系の定式化は大きく四つに分類できる。
**離散時間量子ウォーク**では、状態はコイン空間と位置空間のテンソル積 Hcoin⊗Hpos 上のベクトル ∣ψt⟩ であり、更新はユニタリ演算子 Ut=S(Ct⊗I) による写像として与えられる。
連続時間量子ウォークでは、位置空間上のシュレーディンガー方程式 dtd∣ψ(t)⟩=−iH∣ψ(t)⟩
がグラフのハミルトニアン H で定まり、時間発展はユニタリかつ可逆である。
Kraus/CPTP写像は、環境との相互作用によって系の状態が非可逆的に変化する場合を扱う。密度演算子 ρt の更新は ρt+1=Φ(ρt)=α∑KαρtKα†,α∑Kα†Kα=I
で与えられ、完全正値・トレース保存(CPTP)という条件が物理的整合性を保証する。
GKSL/Lindblad方程式は、Markov的な連続時間開放系の最も一般的な生成子として dtdρ=−i[H,ρ]+k∑γk(LkρLk†−21{Lk†Lk,ρ})
と書かれる。右辺第一項がユニタリ(コヒーレント)発展、第二項が環境への散逸・デコヒーレンスを表す。
LLM側:自己回帰生成の形式
GPT型LLMの自己回帰生成は、因子分解 $$p_\theta(x_{1:T}) = \prod_{t=1}^T p_\theta(x_t \mid x_{<t})$$ に基づく。各ステップでTransformerデコーダが h0=UWe+Wp,hℓ=transformer_block(hℓ−1)
として隠れ状態を更新し、出力分布を pθ(xt∣x<t)=softmax(hnWe⊤)
で与える。masked self-attentionによって位置 t の予測は t 未満の出力にのみ依存し、因果的な更新が保証される。
対応関係の核心:selective Kraus instrumentとしてのLLM
対角セクターへの厳密な埋め込み
量子側とLLM側の最も強い形式的対応は、selective quantum instrument(選択的量子計測器) を介して構成できる。
語彙を V、時刻 t の隠れ状態を st、決定的な状態遷移を fθ(st,y) とする。各トークン y∈V について、Kraus演算子を Ky,s=pθ(y∣s)∣fθ(s,y)⟩⟨s∣
と定義すると、完全性条件 ∑y,sKy,s†Ky,s=I が成立する。
この演算子を用いたselective map Iy(ρ)=s∑Ky,sρKy,s†
に対して、トークン y の出力確率と次状態の更新は p(y∣ρt)=Tr[Iy(ρt)],ρt+1(y)=Tr[Iy(ρt)]Iy(ρt)
と書ける。初期状態を ρ0=∣s0⟩⟨s0∣ のような対角純粋状態に限れば、これはLLMの1ステップ自己回帰生成と完全に一致する。
数値例で確認する厳密対応
2語語彙 V={a,b}、p(a∣s0)=0.8、p(b∣s0)=0.2 の場合を見る。
Kraus演算子を Ka,s0=0.8∣sa⟩⟨s0∣,Kb,s0=0.2∣sb⟩⟨s0∣
と置くと、非選択的更新は Φ(ρ0)=0.8∣sa⟩⟨sa∣+0.2∣sb⟩⟨sb∣
となり、a に条件づけた更新は p(a)=0.8,ρ1(a)=∣sa⟩⟨sa∣
を与える。これは「確率0.8でトークン a を生成し、次状態が sa になる」という自己回帰生成と機械精度で一致する。
したがって、Kraus写像≈条件付き確率更新\mathrm{Kraus写像} \approx \mathrm{条件付き確率更新} Kraus写像≈条件付き確率更新 という対応は、対角セクターにおいては厳密に成立する。
対応が崩れる場所:位相・干渉・非可換性
量子干渉が確率へ現れる仕組み
量子力学では、確率は基本変数ではなく振幅の二乗として導かれる。例として、2状態系の状態 ∣ψϕ⟩=2∣0⟩+eiϕ∣1⟩
を ∣±⟩=(∣0⟩±∣1⟩)/2 基底で測定すると P(+)=21+cosϕ,P(−)=21−cosϕ
となり、相対位相 ϕ が確率に直接影響する。観測基底を変えると干渉項が顔を出し、同一状態でも測定文脈によって分布が変わる。これが量子認知の「順序効果」「干渉」「文脈依存性」の数理的根拠である。
softmaxに干渉項はない
これに対して標準LLMのsoftmaxは p(v∣st)=∑v′exp(zt,v′)exp(zt,v)
という実数指数の正規化であり、「足してから二乗する」量子干渉に相当する構造を本質的に持たない。位相を定義する複素成分がないため、観測基底の変更によって確率分布が変わることもない。
2点グラフ上の連続時間量子ウォークで確認しよう。ハミルトニアンを H=ωσx とすると P0(t)=cos2(ωt),P1(t)=sin2(ωt)
と確率が振動する。Lindblad方程式で脱位相(dephasing)を加えると非対角成分が減衰し、長時間では古典的混合へ収束する。この「振動から収束への移行」は量子認知の開放系モデルの核心だが、LLMで温度 τ を上げても出力分布が平坦になるだけで、隠れ状態に量子的振動が生まれるわけではない。
Lindblad散逸と温度・サンプリングの非同型性
散逸はどこに作用するか
Lindblad方程式の散逸項は密度演算子 ρ(t) 自体の時間発展を変える。つまり内部状態の変形を引き起こす。一方、LLMにおける温度スケーリング pτ(v∣st)=∑v′exp(zt,v′/τ)exp(zt,v/τ)
は、隠れ状態 st を変えるのではなく、readout部分の鋭さを調整するだけである。
同様に、top-k・nucleus samplingといったトークン切り捨て手法も出力分布の読み出し規則を変えるものであって、Transformer内部の状態更新則には関与しない。
したがって、「Lindblad散逸 ↔ 温度」「デコヒーレンス ↔ サンプリング」という対応は、エントロピーが増大するという現象論レベルのアナロジーとしては有効でも、力学的同型としては成立しない。
非可逆性の質の違い
量子チャネルが一般に不可逆であるのは、環境への情報漏出という物理的不可逆性による。LLMで生成トークンを確定させると棄却された枝が失われるのは、探索木を保存しないという計算的・情報論的不可逆性による。両者は「選択的更新」という抽象レベルでは対応するが、不可逆性の発生機構は本質的に異なる。
量子性を取り込む拡張モデルの方向性
複素値隠れ状態の導入
標準softmax LLMに位相を持ち込む最初の拡張として、隠れ状態を複素数値にする方法がある。ht∈Cd とし、読み出しをBorn則型 p(v∣ht)=⟨ht∣Mv∣ht⟩
に変更すると、位相が確率へ影響する経路が生まれる。複素値Transformerの基礎的構成要素は先行研究で提案されており、量子インスパイアード複素語埋め込みの試みも存在する。
密度演算子を隠れ状態にする
より根本的な拡張は、隠れ状態そのものを密度演算子 ρt とするモデルである。トークン確率をPOVM {Mv} で p(v∣ρt)=Tr(Mvρt)
と定め、生成されたトークン v に応じて ρt+1=Tr[Iv(ρt)]Iv(ρt)
で更新する。この密度行列自己回帰モデルでは、非可換性・射影順序・散逸・定常分布が生成過程の内部変数として自然に現れる。量子認知の操作的定式化と最も整合的な選択肢であり、既存のGPTそのものではなく理論的に新しいモデル化の提案となる。
潜在位相変数としての近似的埋め込み
第三の方向として、位相変数 ϕt を直接観測しない潜在変数として導入し av(st,ϕt)∈C,p(v∣st)=∫av(st,ϕ)q(ϕ∣st)dϕ2
と書く方法もある。周辺化後の出力は古典確率の形を保ちつつ、内部では干渉を表現できる。これは完全な量子モデルではないが、標準softmaxでは捉えられない文脈順序依存性や多義性解消の振る舞いを再現できる可能性がある。
実験的検証の設計
理論的対応を実証に落とし込むには、少なくとも三種の数値実験が必要になる。
第一:厳密埋め込み検証。 小語彙自己回帰モデルとdiagonal-Kraus instrumentを同一人工n-gram列で比較し、next-tokenのTV距離・系列尤度差・経路一致率を測定する。対角セクターで一致しなければ理論導出が誤っている。
第二:位相必要性検証。 実数softmax LMと複素hidden/Born decoderを、順序効果・曖昧性・多義的合成を含む人工コーパスで比較する。実数softmaxは周辺確率は合わせられても、位相依存の反事実比較では不利になる可能性がある。
第三:開放系補間検証。 ρ˙=−(1−w)i[H,ρ]+wD(ρ) 型decoderを用い、選好が振動しつつ収束する人工課題で中間値 w が最良かを確認する。w=0(純粋ユニタリ)では振動過多、w=1(純粋散逸)では干渉不足になるなら、開放系モデルの有効性が示される。
これらの実験の本質は「対角埋め込みの正確性」と「位相導入の増分価値」を分離して測ることにある。
まとめ:対応の範囲と次の問い
本記事の要点を整理する。
対応が厳密に成立する範囲: selective Kraus instrumentの対角セクターに限定すれば、GPT型LLMの「次トークン確率+条件付き状態更新」は量子開放系の形式に完全に埋め込める。Kraus写像 ≈ 条件付き確率更新という対応は、この範囲では正確である。
対応が成立しない範囲: 量子ウォーク・量子認知に固有な複素位相・干渉・非可換測定・散逸による内部状態変形は、標準softmax LLMの内部には存在しない。Lindblad散逸と温度スケーリングは現象論的アナロジーにとどまり、力学的同型ではない。
拡張の方向: 量子性を言語生成モデルへ本格的に取り込むなら、複素隠れ状態、Born型読み出し、密度演算子更新へと踏み込む必要がある。この拡張は既存のGPTを改変するのではなく、量子認知と自己回帰生成を共通の操作的枠組みで扱う新たなモデルクラスの設計を意味する。
最も厳密な答えは、「対応はあるが、それは量子性を捨象した古典化対応であり、量子性を取り込むにはモデル自体の拡張が必要」 という一文に集約できる。
コメント