なぜ中世イスラム哲学がAI研究に関わるのか
人工知能の研究が深層学習・大規模言語モデルを中心に急速に進むなかで、「知識とは何か」「認識はどのような構造を持つか」「推論をどう説明するか」という根本的な問いに対する哲学的基盤は、むしろ薄くなりつつあるともいえる。
こうした状況のなかで、10〜12世紀のイスラム世界を代表する哲学者アヴィセンナ(Ibn Sīnā)とアヴェロエス(Ibn Rushd)の思想が、現代AI理論への「概念的補助線」として再評価されつつある。両者の認識論・心身論・解釈学は、単なる歴史的遺産に留まらず、AI設計の課題——知覚表象の階層化、説明可能性(XAI)、倫理ガバナンス——に対して示唆を与えうる構造を持っている。
本記事では、アヴィセンナの「内的感覚」論とアヴェロエスの「三つの推論様式」を軸に、現代AIとの対応関係を整理し、具体的な応用仮説と研究上の限界を検討する。
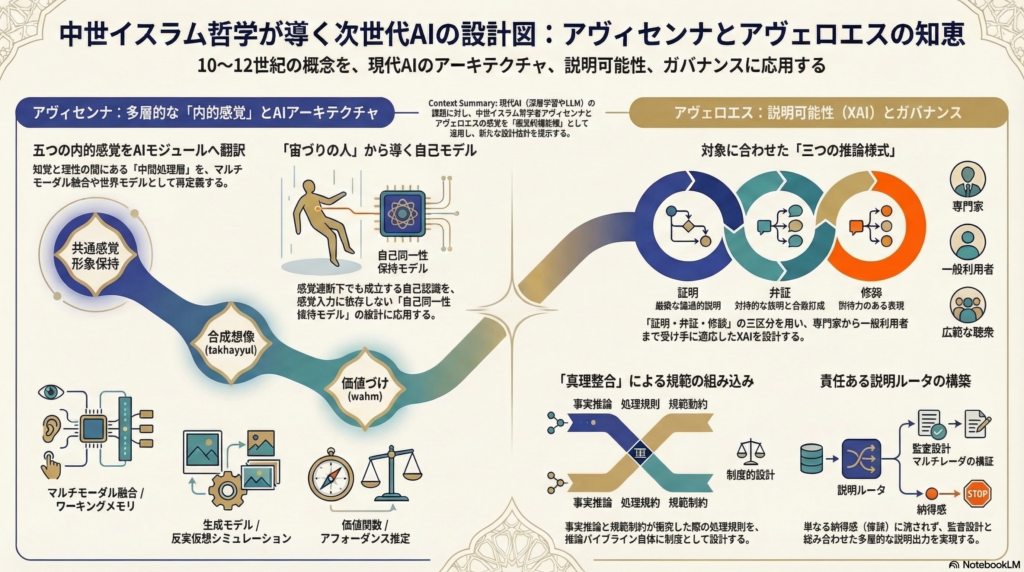
アヴィセンナの認識論:「内的感覚」階層が示す設計原理
外的感覚から理性へ——中間処理の多層構造
アヴィセンナは主著『治癒の書(Kitāb al-Shifāʾ)』の心理学部門において、認識を「外的感覚→内的感覚(複数の中間処理)→理性」という多段階構造として描いた。この構造が現代AIにとって注目に値するのは、「知覚から推論への経路」に複数の機能的役割を持つ中間表象を明示的に置いた点にある。
内的感覚は研究上「五内的感覚(five inner senses)」として整理されており、それぞれ以下の機能を担う。
- 共通感覚(sensus communis / al-ḥiss al-mushtarak):複数の感覚情報を統合する
- 形象保持(ḵayāl):知覚後もイメージを保持する
- 合成・分解する想像(takhayyul):イメージを組み合わせて新たな表象を生成する
- 推量・価値づけ(wahm / estimatio):感覚形象を超えた「意味(maʿnā)」——たとえば「危険」「敵意」——を把握する
- 記憶(dhākira):意味と像を長期保持する
アヴィセンナが「羊が狼の形(色・形状)を知覚する以前に、魂が”危険”という maʿnā を把握する」と例示する点は重要である。これは感覚入力の形式的処理を超えた「意味・価値づけ」の独立した層が存在することを示している。
現代AIへの翻訳:表象学習・世界モデル・価値関数との対応
今日の深層学習は「複数レベルの抽象」を学習する多層構造を基盤としており、アヴィセンナの階層分解はこの設計観と自然に接続する。各内的感覚を計算論的に言い換えると、おおよそ次のように対応させることができる。
| アヴィセンナの概念 | 現代AIで対応しうる概念 |
|---|---|
| 共通感覚(多感覚統合) | クロスアテンション/マルチモーダル融合 |
| 形象保持(ḵayāl) | ワーキングメモリ、リプレイバッファ |
| 合成想像(takhayyul) | 生成モデル/世界モデルによるシミュレーション |
| 価値づけ(wahm / maʿnā) | 価値関数、アフォーダンス推定、潜在ラベル |
| 記憶(dhākira) | 長期記憶、外部メモリ |
特に注目されるのが takhayyul(想像・合成) との接続である。Judea Pearlの「因果の梯子(ladder of causation)」は、観察・介入・反実仮想を段階的に区別し、AIに不足しがちな「反実仮想的想像」能力を焦点化する。アヴィセンナの「想像」を「反実仮想生成」として読み替えると、世界モデルと因果推論の統合(counterfactual world model)という研究課題が浮かび上がる。
また wahm(価値づけ・意味把握) は、単なる感情処理への還元を拒む概念として、報酬設計やアフォーダンス推定の透明化に貢献する可能性がある。wahm を独立モジュールとして明示することで、価値計算がシステム内のどこで行われるかを問える設計になる。
「宙づりの人」思考実験と自己モデル
アヴィセンナが提示する「宙づりの人(Floating Man)」思考実験は、感覚遮断・身体非接触の状態においてもなお「自己の存在」を確証できるという論法である。身体属性を一切肯定せずとも自己同一性が成立しうるという主張は、形而上学的解釈を括弧に入れるならば、「自己モデルが感覚表象とは別系統で成立しうる」という設計仮説として読むことができる。
Thomas Metzingerの自己モデル理論(Self-Model Theory of Subjectivity)や意識の計算論的研究と接続することで、この思考実験は「感覚入力が乏しい状況でも自己同一性を保持する内部状態とはどのような構造か」という評価可能な研究課題を生成する。
アヴェロエスの解釈学と理性主義:XAIとガバナンスへの示唆
「三つの推論様式」が説明可能性に与える分類軸
アヴェロエスは主著『決定的論考(Faṣl al-Maqāl)』において、人々が真理に到達する経路として三つの推論様式を区別した。
- 証明(demonstrative):形式的・論理的に確実な推論
- 弁証(dialectical):妥当な根拠・反例を用いた推論
- 修辞(rhetorical):理解・納得を優先した推論
彼は「宗教はこの三つの方法すべてを含むがゆえに普遍的である」と述べ、受け手の能力や立場に応じた説明の使い分けを制度的に位置づけた。
この区別は、現代のXAI(説明可能なAI)に対して本質的な示唆を持つ。説明の形式は「単一の最良形式」を持つのではなく、受け手(専門家・一般利用者・制度的監査者)に応じて切り替えるべきだという設計課題として再記述できるのである。
現在のXAI研究——LIME(局所近似による説明)やSHAP(特徴寄与の統一枠組み)——は個別手法として機能するが、「どの説明形式をいつ誰に用いるか」という上位の枠組みは未整備のままである。アヴェロエス的な三区分は、この枠組みを設計するための哲学的に整った分類軸となりうる。
「真理整合」原理とガバナンス設計
アヴェロエスが示す「真理は真理に反しない(truth does not oppose truth but accords with it)」という原理は、単なる楽観的な標語ではなく、証明によって得られた知と宗教的テキストの表面的意味が衝突した際の処理規則へと展開される。
証明が明確な結論を導く場合は、テキストの表面的語義を「比喩的解釈(taʾwīl)」によって読み替えることが適格者に求められる——という形式化された規則である。これを現代に読み替えれば、「事実推論の結論」と「規範制約」が衝突した際の処理手順を、推論パイプライン内に制度設計として組み込む発想に相当する。
NISTのAIリスク管理フレームワーク(AI RMF 1.0)、UNESCOのAI倫理勧告、EU AI Actといった現代のガバナンス文書が求める透明性・リスク管理・説明責任を、後付けの監査として扱うのではなく、「推論設計の要件」として組み込む——その発想の源泉として、アヴェロエス的整合原理は有効な参照点となる。
アヴェロエスによる「内的感覚」の再編成
認識論の面では、アヴェロエスはアヴィセンナの五内的感覚を四段階に再編した(共通感覚→想像→識別・思考(cogitative)→記憶)。最大の変更点は、wahm(価値づけ)を独立したモジュールとして置かずに、想像・記憶の過程に内在化させた点にある。
これは現代AIへの翻訳として言えば、「価値づけを独立モジュールとして明示するか、それとも生成・記憶過程に内在化させるか」というアーキテクチャ上の設計判断に対応する。どちらが優れているかは実装上のトレードオフであり、両者の比較研究が設計議論を深める可能性がある。
具体的な応用仮説と設計課題
応用A:内的感覚分解に基づくモジュール型アーキテクチャ
アヴィセンナの五内的感覚を「区別されたサブシステム」として設計に明示し、推論系と接続する構成案である。生成(想像)と識別(知覚)を分離することで世界モデル併用時の計画が整理され、中間表象に対するアブレーション評価も可能になる。
課題: 学習によってモジュールが自然に分離される保証はなく、強いモジュール化は端‐端最適化の性能を損なう恐れがある。モジュール化が「説明可能性の見かけ」に留まらず性能上の利得を持つかどうかを実証することが必要になる。
応用B:三層説明による説明可能性の多層化
同一の意思決定に対して、修辞的(直観的)・弁証的(根拠列挙)・証明的(形式的)の三層で説明を出力し、受け手の役割に応じて切り替える「説明ルータ」を設計する案である。
課題: 説明の忠実性(faithfulness)問題が本質的である。局所近似や特徴帰属が「納得感」を生んでも、真の内部因果を反映しない危険がある。説明層別化が「説得の最適化(修辞の悪用)」に流れないよう、監査設計との組み合わせが不可欠である。
応用C:規範・法と推論の整合設計
「真理整合」原理を、「事実推論」と「規範制約」の系統的整合として実装する案。EU AI Actのような規範文書の要件を推論パイプライン内に形式化し、ライフサイクル全体でリスク管理を組み込む設計である。
課題: 規範の多元性が最大の壁である。アヴェロエスは特定の共同体内の法を前提にしたが、現代AIは多文化・多法域に跨る。規範層の更新・監査・文書化を継続的プロセスとして維持する運用設計が求められる。
応用D:「宙づりの人」を手がかりにした最小自己モデルの評価研究
感覚入力が薄い状況でも自己同一性を保持する内部状態(自己モデル)をエージェントに持たせ、その評価指標を設計する研究計画である。「意識の実装」ではなく、自己同一性・メタ認知の計測可能な成分を抽出することが目的となる。
課題: 自己レポート(言語出力)だけを測る危険を避けるため、内部状態が自己位置・自己行為・自己限界をどの程度予測できるかという行動・表象指標を設計する必要がある。
翻訳の限界と主要な注意点
哲学概念をAI設計に転用する際の最大のリスクは、翻訳の恣意性である。wahm を「価値関数」に対応させる、takhayyul を「生成モデル」に対応させる、という読み替えは、概念の一側面を切り出したものに過ぎず、原典の哲学的文脈から逸脱する恐れが常にある。
また、内的感覚の機能分化が現代の深層モデル内部で観測可能かどうかは自明でない。「共通感覚」「想像」「wahm」が学習によって自然に分離されるかどうかは、プロービング(潜在表象の機能解析)によって検証されなければ仮説に留まる。
さらに、説明可能性の「三層化」は受け手適応の意図を持つが、修辞的説明の悪用——AI出力を「理解しやすく」見せるための説得最適化——というリスクも内包する。アヴェロエス自身が「適格者」による解釈の責任を制度化したように、説明の資格と責任の所在を明確にする仕組みが、設計と並行して整備される必要がある。
まとめ:哲学的発想がAI設計にもたらす問いの枠組み
アヴィセンナの認識論は、「知覚→内的感覚→理性」という階層構造として、現代AIの表象学習・世界モデル・自己モデルに対してモジュール分割の設計原理と評価観点を与える。とりわけ wahm(価値づけ)と takhayyul(生成的想像)の独立性は、価値関数と反実仮想推論を分離して評価するという研究設計と接続しうる。
アヴェロエスの解釈学は、三推論様式の区別と「真理整合」原理を通じて、XAIにおける多層説明の設計課題と、AIガバナンスにおける規範・推論の整合設計という具体的問いを提示する。
重要なのは、これらの哲学概念を「歴史的先駆」として祀り上げるのではなく、現代の計算科学的課題に対する「設計仮説の生成源」として機能させることである。翻訳の恣意性・実装上の観測可能性・説明の忠実性・規範の多元性という限界を認識しながら、学際的な検証計画へと落とし込む姿勢が求められる。
コメント