生成文法とLLMはなぜ同じ土俵で比較できるのか
言語を「規則の体系」として捉えるチョムスキーの生成文法と、「確率分布の推定」として扱う大規模言語モデル(LLM)。一見、まったく異なる立場に見えるこの二つの研究潮流が、近年あらためて同じテーブルで論じられるようになっています。
その背景には、GPT-4やPaLMに代表されるLLMが、人間の言語使用に迫るような流暢な出力を見せるようになり、「これは普遍文法(UG)の否定ではないか」という問いが自然に浮かび上がってきたことがあります。しかし実際には、両者はそれほど単純に対立するわけではありません。生成文法が問うのは「なぜ人間はあの少ないデータで文法を習得できるのか」という学習可能性の問題であり、LLMが示すのは「大量データと計算資源があればどこまで言語行動を近似できるか」という予測性能の問題です。
本記事では、GB(Government & Binding)理論からミニマリスト・プログラムに至る生成文法の変遷と、BERT・GPT系・PaLMといった代表的LLMを比較しながら、普遍文法概念を統計的学習の枠組みで再定式化する複数の研究プログラムを解説します。
生成文法・普遍文法の主要概念と変遷
I-languageとUG:理論の中核にある「内在化された文法」
生成文法を理解するうえで欠かせないのが、I-language(内在化された言語) という概念です。これは、話者の外に存在する文や発話の集合(E-language)ではなく、個人の心的状態として存在する文法体系そのものを理論の対象にするという立場です。
この立場から、普遍文法(Universal Grammar: UG) は「言語獲得の初期状態に組み込まれ、到達可能な文法を制約する原理の体系」として定式化されます。子どもは限られた言語入力しか受け取らないにもかかわらず、驚くほど正確な文法知識に到達します。この現象——いわゆる刺激の貧困(poverty of the stimulus)——を説明するために、UGが仮説空間を強く制約していると考えるわけです。
GB理論からミニマリスト・プログラムへ:UGの縮減という一貫した流れ
1981年の『Lectures on Government and Binding』でGBとして体系化されたP&P(原理とパラメータ)モデルは、「普遍的原理+有限個のパラメータ」によって文法の多様性と普遍性を同時に説明する枠組みを与えました。経験(言語入力)はパラメータを「トリガー」する役割を担い、UGはその仮説空間の外枠を定めます。
1995年の『The Minimalist Program』以降、この方向性はさらに進みます。UG固有の装置を極小化し、インターフェース条件(発話器官・概念意図系)や計算効率といった一般原理によって統語現象を説明しようとする——これがミニマリズムの核心です。2005年の「Three Factors in Language Design」では、(i)UG(遺伝的要因)、(ii)経験(入力)、(iii)言語・生物一般の原理、という三要因が明示され、UGを「言語固有の固定規則集」から「初期条件としての制約の集合」へと位置づけ直す方向が鮮明になります。
この「UGの縮減」という歴史的流れは、後述するLLMとの対比において重要な示唆を持っています。
統計的言語モデルとLLMの原理:確率分布としての言語
次トークン予測という出発点
統計的言語モデルの基本は、文(トークン列)に確率分布を与えることです。自己回帰分解 P(w₁:ₙ) = ∏ P(wₜ | w<ₜ) として定式化され、観測コーパスの対数尤度を最大化する(交差エントロピーを最小化する)学習が標準的です。この枠組みはシャノンの情報理論に遡る系譜を持ち、「言語を予測すること」そのものを学習目標に据えます。
Transformerアーキテクチャは、自己注意機構によって系列内の遠距離相互作用を並列に計算可能にし、それまでのRNNが抱えていた長距離依存の取り込みの難しさを大幅に緩和しました。これが現在のLLMの標準基盤となっています。
代表的モデルの比較:BERT・GPT系・PaLM
| モデル | アーキテクチャ | 事前学習目標 | 規模(代表値) |
|---|---|---|---|
| BERT(2019) | Transformer encoder(双方向) | MLM+NSP | 110M〜340Mパラメータ |
| GPT-2(2019) | Transformer decoder(左→右) | 自己回帰LM | 最大1.5Bパラメータ |
| GPT-3(2020) | Transformer decoder(左→右) | 自己回帰LM+in-context | 175Bパラメータ |
| PaLM(2023) | Transformer decoder(左→右) | 自己回帰LM(大規模スケール) | 540Bパラメータ |
BERTは双方向文脈でのマスク言語モデルとして表現学習を実現し、GPT系は左→右の自己回帰生成によるin-context学習を特徴とします。PaLMはさらに大規模スケーリング下で多様なベンチマークで顕著な性能向上を示し、一部タスクでは平均的な人間の正答率を上回ると報告されています。
重要な発見として、性能(損失)がモデルサイズ・データサイズ・計算量に対して滑らかなべき則に従うスケーリング則があります。また、あるスケールを超えると特定の能力が急に立ち上がるように見える「創発(emergence)」的現象も報告されており、単純な「パラメータ設定」とは異なる一般化のあり方が示唆されています。
生成文法とLLMの理論的対比:同じ現象を異なる説明水準で
文法獲得の説明:UGモデル vs 分布近似
UGモデルは、到達すべき文法が入力データから一意には決まらない(under-determination)という直観から出発し、仮説空間に強い制約を置きます。「経験がパラメータを固定する」という表現がよく使われます。
一方、LLMにおける学習は「パラメータのトリガー的固定」ではなく、勾配降下による連続最適化です。目標は文法の明示的な理論化ではなく、コーパス上の確率分布の近似(尤度最大化)にあります。
ここで生じる本質的な問いは、LLMの学習成功が「人間並みデータ効率での獲得理論」を提供するわけではない、という点です。現状のLLMは人間が生涯に触れる言語データをはるかに超える量のテキストで学習しており、このデータ効率のギャップがUG議論の核心として残ります。
構文的一般化:階層構造はどこから来るか
生成文法の古典的な論点は、言語の規則が線形ではなく階層構造に依存する(structure dependence) という点です。「疑問文を作る際、最初の動詞ではなく主節の主動詞を移動させる」というような、表面的なパターンではなく構造に基づく一般化が、ほとんど経験なしに子どもによって選択されるように見える。これが刺激の貧困議論と結びつきます。
統計的アプローチからは、ベイズ的モデルでも「単純性」によって構造依存が合理的に選ばれ得るという反論が提示されています。LLMについては、Transformerの自己注意が階層構造を表現できるかどうかは理論的にも議論があり、「入力長に応じて層やヘッドを増やさない限り階層構造を扱えない」という形式言語理論上の主張もあります。
LLMの成功は「階層性がUG固有の専売である」という強い主張を弱める一方で、「どのバイアスが階層的一般化を保証するのか」というより精密な問いへと議論を押し出します。
能力(competence)と遂行(performance)の境界線
生成文法は「理想話者の能力」を対象化し、処理上の誤りや記憶制限は「遂行」の問題として別扱いします。LLMはむしろ遂行モデルに近く、確率的生成の結果として誤りが含まれることは想定内です。その誤り分布自体がモデルの性質を表します。
この差は、UGをLLMで再解釈する際に「能力とは何か」を再定義する必要を示しています。「能力=ある種の制約を満たす分布族」として捉え直すことで、両者の橋渡しが可能になるかもしれません。
BLiMPで見るLLMの構文的能力:実証的エビデンス
BLiMP:最小対による大規模構文評価の標準
最小対(minimal pairs)とは、文法的/非文法的の差を最小限の変更で作り出したペアです。モデルが文法に整合する方の文に高い確率を付与できるかを問うことで、局所的な語彙頻度ではなく構文知識を測ろうとします。
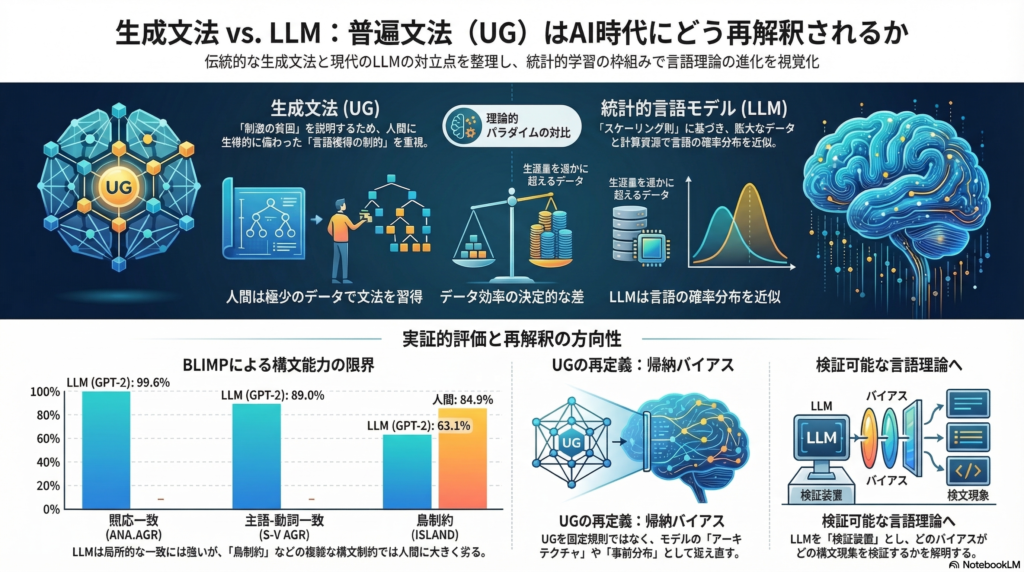
BLiMP(Benchmark of Linguistic Minimal Pairs)は、この最小対を大規模化し、現象カテゴリ別の成績を与えるベンチマークです。ローカル共起統計(5-gram)が総合60.5%程度にとどまる一方、GPT-2では総合80.1%に達し、大規模ニューラルモデルが局所統計を超えた構文知識を持つ可能性を示しています。しかし人間の一致率88.6%には届いていません。
現象別の達成状況:何ができて、何が難しいか
| 対象現象 | GPT-2の成績 | 人間の成績 | 解釈上の注意点 |
|---|---|---|---|
| 照応一致(ANA.AGR) | 99.6% | — | 形態・語彙手掛かりで近似できる可能性あり |
| 主語-動詞一致(S-V AGR) | 89.0% | — | 真の階層一般化の確認には追加証拠が必要 |
| フィラー-ギャップ(FILLER-GAP) | 79.0% | 86.9% | 表層パターンとの分離が課題 |
| NPI ライセンシング | 78.9% | 88.1% | 意味・語用との境界が曖昧 |
| 量化(QUANTIFIERS) | 71.3% | 86.6% | 形式的制約と意味的可解性の分離が困難 |
| 島制約(ISLAND) | 63.1% | 84.9% | 最大のギャップ。因子計画による精密評価が必要 |
特に島制約(island constraints) でのギャップは顕著です。63.1% vs 84.9%という差は、単純な頻度学習ではこの制約が獲得しにくいことを示唆しており、UGが焦点化してきた現象こそLLMの限界が現れやすいという皮肉な構図が見えます。
BLiMP論文自体が「肯定的な結果を人間と同型の知識の証拠と解釈することへの注意」を明示しており、複数の証拠様式(無意味語・分布外一般化・因子計画)による確認を求めています。
普遍文法の統計的再解釈:3つの研究プログラム
提案1:UGを「事前分布/帰納バイアス」として捉える
最も直感的な再定式化は、UGを「生成規則のリスト」ではなく、学習者が採用する仮説クラスに置かれた事前分布(prior) として表現することです。刺激の貧困を「データが少ない状況での合理的推論」に翻訳するこのアプローチは、ベイズ的モデルが構造依存を単純性から選好し得ることを示した研究と整合します。
LLM側では、Transformerのアーキテクチャ(自己注意の接続形式)、トークナイザ、事前学習目標、正則化が「暗黙のUG」として機能していると見ることができます。BERTの双方向制約とGPT系の左→右制約の違いは、「UG=仮説空間の制約」の異なる実装として解釈できるかもしれません。
この枠組みが生む予測は明快です。島制約のような現象の学習困難さは、データ量だけでなくアーキテクチャ上の制約(注意の形、長さ一般化の方式)に敏感に変化するはずです。BabyLMのように人間並みデータ量(100M語以下)に制限したとき、どのバイアスが残る能力を支えるかが「UGの実体」として浮かび上がる可能性があります。
提案2:UGを「資源制約下の最適化が誘導する普遍性」として捉える
三要因論を「目的関数+制約の最適化問題」として書き直す視点です。UGは「初期条件(表現形式)」、一般原理は「効率制約(計算資源・圧縮)」、経験は「観測分布」に対応します。
LLMのスケーリング則や計算最適学習の議論は、まさに「資源制約下での最適化が性能を左右する」ことを示しています。言語普遍性を「言語固有の生得的規則」ではなく、「最適化が誘導するアトラクター」として捉えると、異なるモデル族でも類似した誤り分布が現れることが予測されます。逆に、島制約が「最適化だけ」では出現しないなら、追加バイアスの必要性が浮かび上がります。
提案3:UGを「評価関数を含む学習可能性理論」として捉える
最も野心的な再定式化です。UG論争の核心を「何が生得か」から「何を到達目標とみなすか」へ移します。UGとは「評価関数(何を成功とみなすか)」と「仮説空間(何を候補とみなすか)」の組であり、LLM研究は現状「次トークン予測損失」という単一の評価関数を採用しています。
評価関数を複数化(文法性・意味整合・処理指標・データ効率)し、「どの評価関数で普遍性が出るか」を問う研究計画こそが、形式(form)と意味(meaning)の切り分けを含む、より包括的な言語理論につながる可能性があります。
具体的な実験設計:理論を検証可能な仮説へ
プロトコルA:島制約の因子計画ターゲット評価
wh依存の有無×島環境(島/非島)×距離×語彙新奇性を直交させ、surprisal差で「wh効果」を測ります。交互作用(wh×島)が人間と同方向に出るか、分布外一般化で効果が保持されるかを指標にします。効果が特定語彙やテンプレートに依存する場合は「ヒューリスティクス」的学習の証拠となります。
プロトコルB:データ効率制約下での獲得実験
BabyLMの枠組み(100M語以下の固定予算)で、アーキテクチャ・目的関数・カリキュラムを因子操作します。「低データでも島制約・量化が立ち上がるか」が主要問いであり、現象別の学習曲線(何語で能力が獲得されるか)を指標とします。
プロトコルC:形式言語プレトレーニングと自然言語一般化
再帰的階層性(Dyck言語等)を事前学習させることで自然言語の構文一般化が改善するかを調べ、「UG=階層計算のバイアス」という仮説を操作可能にします。
まとめ:LLMはUGを否定しない——問いの水準が変わった
本記事の要点を整理します。
LLMの成功はUGを直ちに否定しない。 生成文法の「説明的十分性」は単なる正答率ではなく、仮説空間・学習可能性・文法の型まで含む説明を要求しますが、LLMは主に予測性能を最適化しています。BLiMPの実証データが示すように、島制約や量化など、UGが焦点化してきた現象でこそLLMは人間から大きく遅れます。
重要なのは、両者の対立を「UGがある/ない」という二項対立で論じるのではなく、「どのバイアスが、どのデータ効率で、どの構文現象を保証するか」という検証可能な問いに変換することです。UGの再定式化——事前分布としてのUG、最適化が誘導する普遍性としてのUG、評価関数を含む学習可能性理論としてのUG——はそれぞれ、この変換の異なる実装です。
次世代の普遍文法概念は、固定された規則集ではなく、検証可能な帰納バイアス理論として構築されていく可能性があります。その検証装置として、LLM研究は大規模比較実験・学習曲線分析・ターゲット評価基盤という強力なツールを提供しています。
コメント