はじめに:「正解できる」は「理解している」とイコールではない
教育評価の現場では長年、テストの正誤結果が学習者の理解度を示す主たる根拠として使われてきました。しかし近年、日本の学習指導要領改訂や教育政策の議論においても「深い学び」が重視されるようになり、単に答えられるかどうかではなく、知識を使いこなせるかどうかが問われる評価へのシフトが加速しています。
概念理解とは、知識を相互に関連づけ、理由を説明し、新しい文脈へ応用できる状態を指します。この定義に照らせば、従来の一問一答型テストだけでは「理解の深さ」を十分に捉えられないことが明らかです。
本記事では、説明能力・転移能力・確信度・反応時間という4つのアプローチを統合した概念理解指標の設計思想と実装可能性について、学習科学・教育測定の知見をもとに解説します。
概念理解の測定が難しい理由
「知っている」と「理解している」の違いとは
学習科学の観点では、理解は単なる記憶の量ではなく、新しい学習を促進する組織化された知識として捉えられます。暗記に基づく学習と理解に基づく学習の最大の違いは、転移——習得した知識を未知の文脈に応用できるかどうか——に現れます。
知識が特定の文脈に閉じていると転移が阻害されることが古典的な研究から示されており、真の理解を持つ学習者は、見慣れない問題に対しても基礎となる原理を使って対処できます。逆に、表面的な記憶だけの学習者は、文脈が少し変わるだけで対応できなくなりがちです。
単一テストが捉えられない構成概念
正誤のみを記録する選択式テストは実施が容易で信頼性も高い一方で、以下の点において概念理解の測定に限界があります。
- 推論の過程が見えない:正答に至った思考プロセスが不明
- 文脈依存が強い:習った形式の問題には答えられるが、応用問題に対応できない
- メタ認知が見えない:「なんとなく選んだ」と「確信を持って選んだ」が区別されない
- 努力の差が見えない:丁寧に考えて答えたのか、直感で答えたのかが不明
これらを補うために、説明課題・転移課題・確信度測定・反応時間ログを組み合わせた多面的評価が研究・実践の両面で注目されています。
4つの測定アプローチを理解する
説明能力:「なぜそうなるか」を語れるか
説明能力の測定は、概念理解の中核に最も近い指標とされています。代表的な手法として、自己説明プロトコル、CER(主張・根拠・推論)ルーブリック、概念地図、SOLO taxonomy などが挙げられます。
自己説明研究では、理解の深い学習者ほど「操作を原理と結びつける説明」を多く生成することが示されています。単に「こうすればいい」ではなく、「なぜそうなるのか」を言語化できるかどうかが、理解の深度を映し出す鏡となります。
科学教育で広く用いられるCERルーブリックでは、説明をclaim(主張)・evidence(根拠)・reasoning(推論)に分けて評価します。この方法は内容理解と推論の両方を可視化できる点で優れていますが、評定者間の一致を担保するためのトレーニングが不可欠です。
概念地図やSOLO taxonomyも、概念間の関係性や理解の質的水準を捉える上で有効な古典的手法ですが、採点基準の揺れや地図作成スキルそのものの影響を受けやすい点は留意が必要です。
転移能力:習ったことを別の文脈で使えるか
転移の評価は、概念理解の「外的妥当性」を確認する上で不可欠です。研究では一般に、近転移(表現を変えた同構造の問題)と遠転移(全く異なる文脈での応用)が区別されます。
さらに近年注目されているのが**PFL(Preparation for Future Learning)**と呼ばれるアプローチです。これは、資源(テキスト・図・ヒントなど)を提供した状態で新規問題に取り組ませ、「学びながら解く能力」を測るものです。PFL研究は、既有知識の量だけでなく、新しい問題に学習しながら対応する能力こそが深い理解の証拠だという立場をとります。
日本の理科授業研究でも、継続的なモデルベース学習を通じた学習者が、内容理解に加えて遠転移課題でも一部対応できたことが報告されており、転移の可視化は日本の教育評価文脈でも有効性が認められつつあります。
転移課題の課題として挙げられるのは、問題数が少ないと信頼性が低下しやすいことです。このため、課題設計の段階で転移の「遠さ」を明示し、複数問題を組み合わせることが推奨されます。
確信度:「自分の理解への見積もり」は正確か
確信度測定には大きく2つの系統があります。第一は項目ごとに0〜100で回答後の自信度を記録するtask-specific confidence judgment、第二は学習全般に対する信念を測る自己効力感・メタ認知尺度です。
ここで重要な概念が**校正(calibration)です。確信度が高いこと自体は理解の証拠ではありません。「高い確信度を持ちながら実際には間違える」過剰確信の問題は多くの研究で確認されており、確信度を評価指標として使う際には確信度の平均値ではなく、正答とのズレの小ささ(校正の正確さ)**が重要です。
確信度から算出できる主な指標は以下の通りです。
- 校正バイアス:平均確信度と正答率の差
- 絶対校正誤差:確信度と正答の絶対的なズレの平均
- 分解能:確信度が実際の正誤を識別できているかどうかの相関係数
自己効力感尺度(MSLQなど)やメタ認知尺度(MAIなど)は比較的安定した自己信念を測れますが、領域一般的な測定にとどまると説明力が落ちる傾向があります。概念理解の評価では、課題に即した特異的な自己効力感評定が望ましいとされています。
反応時間:応答の速さが語ること、語らないこと
コンピュータ化評価の普及により、反応時間(RT)は教育測定の注目データとなっています。ただし、RTをそのまま「速い=理解が深い」と解釈するのは誤りです。長時間応答が熟慮の結果である場合もあれば、混乱の表れである場合もあります。
RTの活用で現在もっとも有効とされているのは、rapid guessing(素早い当てずっぽう)の検出です。低ステークスの評価場面ではとくに、十分に考えずに素早く回答する行動が混入しやすく、こうした応答を検出・除外することで評価の質が向上します。
計量的には、RTの分布は右に歪んでいるため対数変換(lognormal モデル)が適切とされており、項目の難度や内容に合わせてRTを正規化する手法が用いられます。さらに速度と正確性を階層的に分けて扱う速度‐正確性モデルが確立されており、個人差と項目差を切り離した解析が可能になっています。
RTはあくまで「応答過程の痕跡」として補助的に使うのが妥当であり、理解の直接指標ではなくエンゲージメントや戦略の手掛かりとして統合するのが現実的な設計方針です。
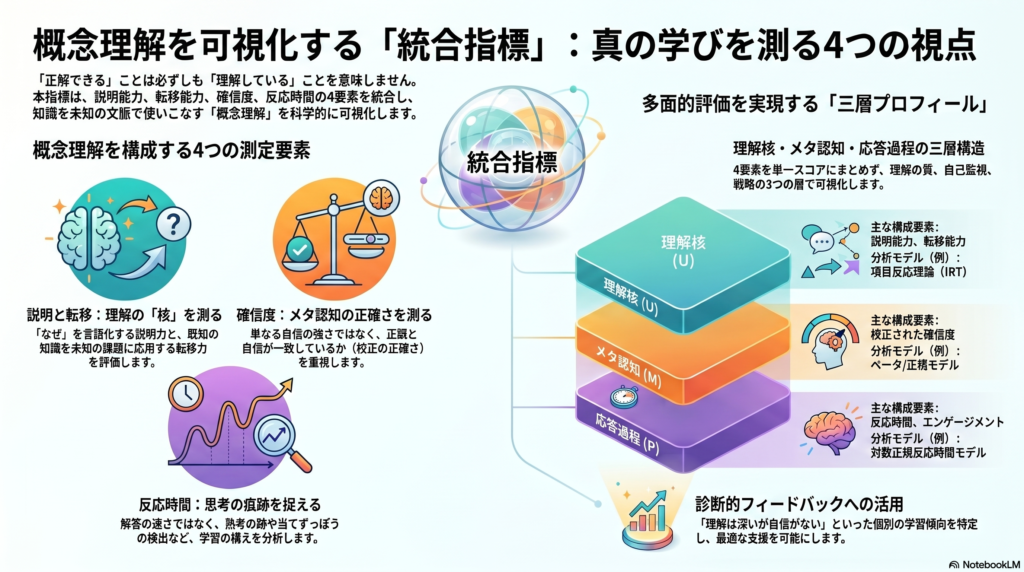
統合指標の設計:三層プロフィール構造
単一スコアより「三層プロフィール」が有効な理由
4つのアプローチを一気に単一の総合点に圧縮することには大きなリスクがあります。たとえば「説明は弱いが転移は強い」「理解は高いが過剰確信がある」「理解は中程度だが学習可能性が高い」といった違いは、教育的に非常に重要な情報ですが、単一総合点では消えてしまいます。
そこで理論的に推奨されるのが、三層プロフィールとして報告し、必要に応じて合成指標を算出する設計です。
- 理解核(U):説明能力と転移能力の共通分散
- メタ認知(M):校正された確信度と課題特異的自己効力感
- 応答過程(P):条件づけられた反応時間とエンゲージメント指標
この三層構造において、MとPはUと相関しますが、同一ではありません。したがって、両者はUを補助・診断的に解釈するための変数として扱うことが理論的に自然です。
計量モデルの選択と注意点
統計モデルとしては、複数の候補を段階的に比較することが推奨されます。
説明課題の採点にはmany-facet Raschまたは評定者つきの順序IRT、選択式・近転移課題には2PL/GRM、確信度には連続尺度ならbeta/normalモデル、反応時間にはlognormal RTモデルと速度‐正確性の階層モデルが基本構成です。
全体の統合モデルとしては、相関四因子モデル → 二次因子モデル(bifactorも選択肢)→ SEMの順で段階的に構築することが、実装可能性と理論的一貫性のバランスが良い方法です。
モデル選択の基準は適合度だけにとどまらず、外的基準予測・群間不変性・重みの安定性・解釈可能性を総合的に判断すべきです。
公平性・倫理の課題
反応時間やログデータは、神経発達の多様性、障害、言語背景などによって集団差が生じやすく、同じ理解水準の学習者でも分布が異なる可能性があります。OECDは、プロセスデータの利用において妥当性・公平性・倫理を設計段階から一体で議論することを強調しています。
また、RTログが「見えない監視」として受け取られる可能性もあるため、収集目的・保存期間・再利用範囲・教育的フィードバックと選抜利用の区別を学習者と現場に明示することが倫理的に求められます。
実装に向けたロードマップ
研究の進め方:認知面接から本調査へ
概念理解の統合指標を開発する現実的な研究計画は、認知面接と小規模パイロットから出発し、2段階のパイロットを経て本調査へ進む約15〜18か月のロードマップが標準的とされています。
各段階の目安は次の通りです。
- 構成概念定義・設計(2〜3か月):ブループリント、初版ルーブリックの作成
- 項目開発・認知面接(2〜3か月):項目草案、操作ログ仕様の確定(N=30〜60)
- パイロット1(2か月):不良項目の除去、RT仕様の確認(N=150〜250)
- パイロット2(3か月):因子候補の確定、評定者間信頼性の安定化(N=300〜500)
- 本調査(3〜4か月):主分析データの確保(N=500〜800以上)
- 分析・公開(2〜3か月):技術報告・論文・コードの整備
本調査で群間比較まで視野に入れるなら、N=900〜1500が現実的なサンプル規模の見積もりとなります。
妥当性証拠の積み上げ方
单一のα係数だけで信頼性を判断するのは不十分です。Testing Standardsに従い、少なくとも内容・応答過程・内的構造・外的変数との関係・帰結の各側面から証拠を積み上げることが求められます。
特に説明課題と反応時間を含む設計では、応答過程証拠(think-aloudや認知面接)と公平性証拠(DIF・測定不変性・デバイス差の検証)が通常以上に重要になります。
まとめ
概念理解の測定は、「正解できるか」という問いだけでは完結しません。説明能力・転移能力・確信度の校正・反応時間の戦略的解釈を組み合わせた三層プロフィール設計が、現在の学習科学・教育測定の知見と日本の政策文脈の双方に整合する最も妥当なアプローチです。
開発の成功条件は明確です。説明と転移を中核に据え、確信度は高さではなく妥当さとして、反応時間は速さではなく戦略・エンゲージメントの痕跡として扱うこと。そして統合は最初から単一スコアを目指すのではなく、妥当性証拠を段階的に積み上げながら進めること——この原則を守った設計こそが、「深い理解を測る評価」の実現に最も近い道筋です。
コメント