なぜ「予測誤差」が教育を根本から変えるのか
学習者は空白の器ではない。授業が始まる前からすでに「こうなるはずだ」という仮説を頭の中に持っており、授業の情報はその仮説と照合されながら処理される。この事実を出発点に置いたとき、従来型の「説明→練習」という教授設計がいかに多くの学習機会を取りこぼしてきたかが見えてくる。
近年、神経科学・認知科学の分野で急速に支持を集める予測処理理論(predictive processing / predictive coding)は、脳を「予測機械」として捉える。脳は感覚入力を受け取るたびに、自分の持つモデルから予測を生成し、実際の入力との差分=**予測誤差(prediction error)**を手がかりにモデルを更新し続ける。この枠組みを教育へ翻訳すると、学習とは「既有の知識モデルに誤差を与え、その誤差を適切に修正する反復過程」として再定義できる。
本記事では、予測処理理論の核心を整理したうえで、実証エビデンスと接続させながら教育実践への応用設計を具体的に解説する。理論的背景、授業設計の原則、フィードバック・評価の改善、そして個別化学習への展開まで、段階的に論じていく。
予測処理理論の核心:脳は何を「学ぶ」機械なのか
生成モデルと予測誤差の仕組み
予測符号化(predictive coding)の基本的な主張は、脳の各階層が上位から下位へ「予測」を送り、下位から上位へ「予測誤差(差分)」を返す双方向通信によって知覚・学習・行為が成立する、というものだ。
Karl Fristonらが整理した自由エネルギー原理(free-energy principle)はこれをさらに拡張し、知覚・学習・行為のすべてを「自由エネルギー(予測誤差の上限)の最小化」という単一の原理で説明しようとする。教育設計の観点からこの原理を読むと、学習者はつねに「誤差をできるだけ小さくしようとする存在」であり、その誤差を意図的に設計することが教師の核心的な仕事になるという視点が生まれる。
もう一つの重要概念が**精度(precision)だ。予測誤差が生じれば自動的に学習が促進されるわけではなく、「この誤差をどれだけ信頼すべきか」という重み付けが更新の強さを決める。この精度推定が、計算論的な意味での注意(attention)**に対応する。つまり、学習者がどこに注意を向けるかを制御することが、誤差修正の質を左右する決定的な変数になる。
能動的推論と探索行動
能動的推論(active inference)の観点では、学習者は誤差に受動的に対応するだけでなく、行為によって入力そのものを変え、将来的な誤差を減らそうとする。これは「探索・試行・検証を通じた能動的な学びが理論的に最も整合性が高い」ことを意味する。受け身で説明を聞く授業より、予測を立てて試して確かめるサイクルを回す授業のほうが、予測処理理論の観点からは学習効果が高くなると予測される。
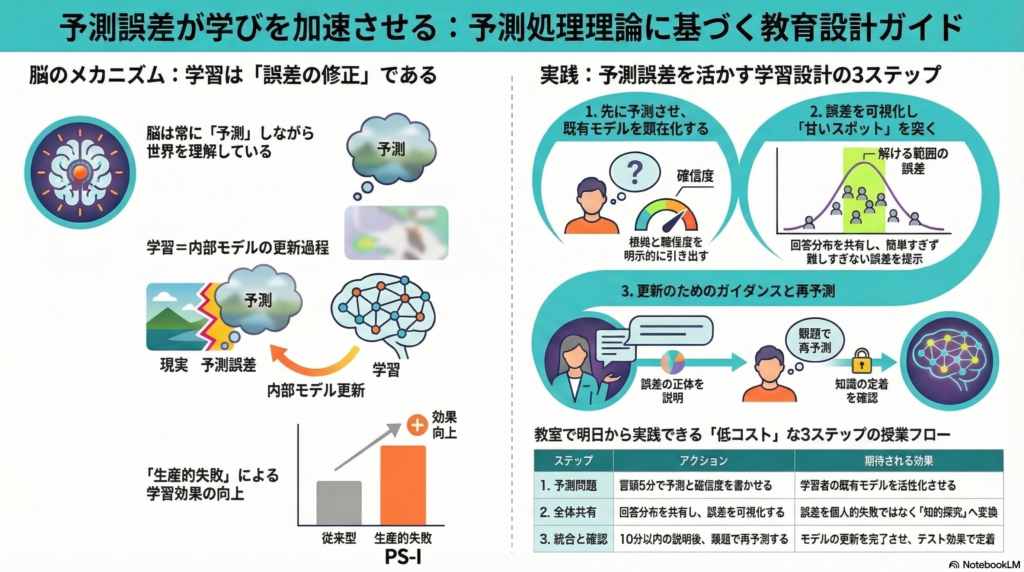
予測誤差駆動型学習設計の4つの設計原則
予測処理理論を教育方法論へ翻訳したとき、核となる設計単位は次の短サイクルになる。
予測(仮説)を引き出す → 観測/解答で誤差を可視化する → 説明・対話・フィードバックで更新する → 転移課題で再予測する
この4ステップを繰り返すことが「予測誤差駆動型学習設計(Prediction-Error Driven Instructional Design)」の骨格だ。以下、設計原則として4点に整理する。
原則1:先に予測させる(Predict First)
授業や課題の冒頭で、答えを教える前に「あなたはどう思うか」を明示的に引き出す。選択肢への投票でも、短い自由記述でも構わない。重要なのは「根拠と確信度も一緒に書かせること」だ。根拠を言語化させることで、学習者自身がどのような生成モデルを持っているかが顕在化し、後の誤差修正の効率が上がる。
この設計と親和性が高い手法として**POE(Predict–Observe–Explain)**がある。理科教育を中心に多くの教室で実践されており、学習者の予測と観測が矛盾したときに説明段階で概念修正が起こる構造を持つ。メタ分析では、POEが理科の学習成果に対して中〜大程度の効果量を示す報告がある。
原則2:誤差を「見える」形にする(Visualize the Gap)
予測の後、観測や解答が返ってきたとき、個々の学習者だけが誤りを知るのではなく、クラス全体で誤差の分布を共有することが学習効果を高める可能性がある。ピア・インストラクションでは、回答の分布(何割が選択肢Aを選んだか)をその場で提示し、クラス内の予測の多様性を見せる。この「自分だけが間違えたのではなく、みんなも予測が割れている」という文脈が、誤差を個人的な失敗でなく「探索可能な知的問題」として再フレームする効果を持ちうる。
また板書やスライドで「予測」と「実際の結果」を並べて差分を可視化することも、精度(注意の重み付け)を設計する観点から有効だ。どこに注意を向けるべきかを教材提示の時点でコントロールすることが、誤差修正の成否を左右する。
原則3:誤差を「甘いスポット」に置く(Design the Sweet Spot)
誤差が大きすぎると、学習者はどこから手をつけてよいかわからず、認知負荷が爆発して学習が破綻しやすい。逆に誤差が小さすぎれば、更新は起こるが動機づけにならない。予測処理理論における「能動的推論」は、誤差が「解ける範囲にある」課題へ自発的に向かう探索行動を予測する。この「解けそうだが、まだ解けていない」という帯が、動機づけと学習の両面に効く「甘いスポット」だ。
**Productive Failure(生産的失敗)/ PS-I(Problem Solving–Instruction)**は、この原則を意図的に設計した介入として位置づけられる。学習者にまず問題を解かせ(失敗を前提とする)、その後に統合的な説明を行うことで、失敗という予測誤差体験が後段の説明の受け取り方を変える。2021年のメタ分析(53研究・166比較)では、全体効果量 g=0.36 程度でPS-Iが有利な結果が示されており、特に設計の忠実度が高い条件での効果が強くなる傾向があると報告されている。ただし、若年の学習者や汎用スキルの習得場面では逆転が見られる場合もあり、「誰でも誤差先行が良い」という単純化は禁物だ。
原則4:ガイダンスで更新を正規化する(Guide the Update)
誤差を経験させても、その後の「統合説明」がなければ、誤った更新が定着したり、混乱が残ったりするリスクがある。予測処理理論の観点からも、誤差は更新のシグナルであるが、何をどう更新すべきかのガイダンスなしに正しい方向への修正は保証されない。したがって、誤差を設計した分だけ、統合・説明・フィードバックの質が問われる。
具体的には、(a) どの仮説が誤っていたか、(b) どの手がかりを見落としていたか、(c) 次の予測で何を変えればよいか、の3点を含むフィードバックが有効と考えられる。教育フィードバック研究の大規模メタ分析(435研究、6万名以上)は、フィードバックを「学習調整のための情報」として扱う重要性を繰り返し示している。
低コストで始める実装ステップ
予測誤差駆動型学習設計は、ICTや大規模な教材改訂がなくても始められる。以下に最小限の実装手順を示す。
ステップ1:授業冒頭に「予測問題」を1問入れる
毎時限の最初の5分間、選択式の予測問題を出す。回答に加えて「根拠または確信度(1〜5)」を書かせるだけでよい。この一手間が、学習者の既有モデルを活性化させ、後続の情報処理を能動的にする。
ステップ2:誤差を全体で共有する
挙手・投票・GoogleフォームなどでクラスのA/B/C回答の分布を見せる。「約半数がAを選んだ」という事実が、次の議論への動機になる。印刷物しか使えない環境では、黒板に手挙げで数を書き留めるだけでも機能する。
ステップ3:ペア・小集団で根拠を交換する
3〜5分のペアワークで「なぜそう予測したか」を話し合わせる。他者の予測を聞くこと自体が新たな誤差(「そういう見方もあるのか」)を生み、精度の再配分を促す。
ステップ4:教師が短く統合説明する
ペアワーク後、教師は長い講義ではなく「今回の誤差の正体」だけを10分以内で説明する。「多くの人がAを選んだのは○○という前提があったから。でも、実際には△△という条件があるため…」という型で話すことで、更新すべきポイントが明確になる。
ステップ5:再予測問題で更新を確認する
最後の5分で類題を1問だけ解かせる。これが「テスト効果(retrieval practice)」として機能し、更新された知識の定着を促す。多くのメタ分析が、再学習より想起練習(テスト)のほうが長期保持を高めることを示している。
フィードバックと評価の再設計
「正誤通知」から「更新情報」へ
従来の丸付けや点数は「正誤通知」にとどまることが多い。予測誤差の観点からすれば、学習に効くのは「どの仮説が誤っていたか」という差分情報だ。誤答を3〜5タイプに分類し、各タイプに対応する「更新ヒント(定型コメント)」を準備することで、教員の負担を最小化しながら情報量の多いフィードバックを実現できる。
フィードバック後は「再予測問題(類題)」を即座に1問だけ解かせることで、更新が起きたかどうかを確認し、短サイクルで誤差の解消を促せる。
評価の観点を「結果」から「プロセス」へ
単元末テストの点数だけでなく、(a) 予測の妥当性、(b) 誤差後の更新の質(説明の改善度)、(c) 新しい文脈での転移(再予測)、という3軸で評価する設計が、予測誤差駆動型学習設計と理論的に整合する。最初は「転移課題1問+更新説明1本」という最小セットから始め、校内体制に合わせて拡張するのが現実的だ。
個別化学習への応用:「誤概念タイプ」で分岐する
個別化の鍵は個々の「誤差の種類」をデータ化することにある。単元開始前のプレテストで誤答タイプと確信度を把握し、「反例が効く学習者」と「手続き支援が効く学習者」で教材を分岐させる。この分岐は高度なAIシステムがなくても、2〜3種類の印刷プリントや課題カードで実現できる。
重要なのは、分岐を「能力グループ」として固定しないことだ。分岐はあくまで「現時点での予測モデルの差分に基づく可変な支援」であり、更新が進めば支援の形も変わる運用が学習者の自己概念を守る。
まとめ:予測誤差を設計することが教育の本質へ
予測処理理論が教育方法論にもたらす最も重要な転換は、「良い授業とは正しい情報を正確に伝えることだ」という前提を揺るがすことにある。学習者はすでに自分なりのモデルを持っており、そのモデルに適切な誤差を与え、誤差を解消するための支援を設計することが教師の核心的な仕事になる。
本記事で紹介した実践ポイントを整理すると次のようになる。
- 授業冒頭に「予測問題+根拠」を組み込み、既有モデルを顕在化させる
- 誤差の分布をクラスで共有し、更新への動機を引き出す
- 誤差が「甘いスポット」に収まるよう課題難易度とガイダンスを設計する
- フィードバックを「正誤通知」から「更新情報」へ転換する
- 再予測・転移課題で更新の定着を確認する
これらは、POE・Productive Failure・ピア・インストラクション・テスト効果・分散学習といった実証済みの手法と直接接続しており、理論的な裏付けと実践的エビデンスの両面から支持される設計論として統合できる。
コメント