はじめに:なぜマルチモーダル比喩理解が重要なのか
比喩(メタファー)は、人間が抽象的な概念を具体的なイメージになぞらえて理解する言語表現です。この比喩という現象は言語だけでなく、画像、音楽、映像といった様々なモダリティに現れます。近年、AIによるマルチモーダル比喩理解の研究が急速に進展しており、ソーシャルメディア上のミーム画像、広告動画、歌詞付き音楽など、複数の情報チャネルを統合した比喩の自動検出・解釈が可能になりつつあります。
本記事では、マルチモーダル比喩理解における最新の研究動向と手法を体系的に解説します。主要なAIモデル、動画や音楽といった時系列メディアでの比喩検出、認知科学理論とAI応用、そして学際的アプローチや国際会議での議論まで、この新興分野の全体像を明らかにします。
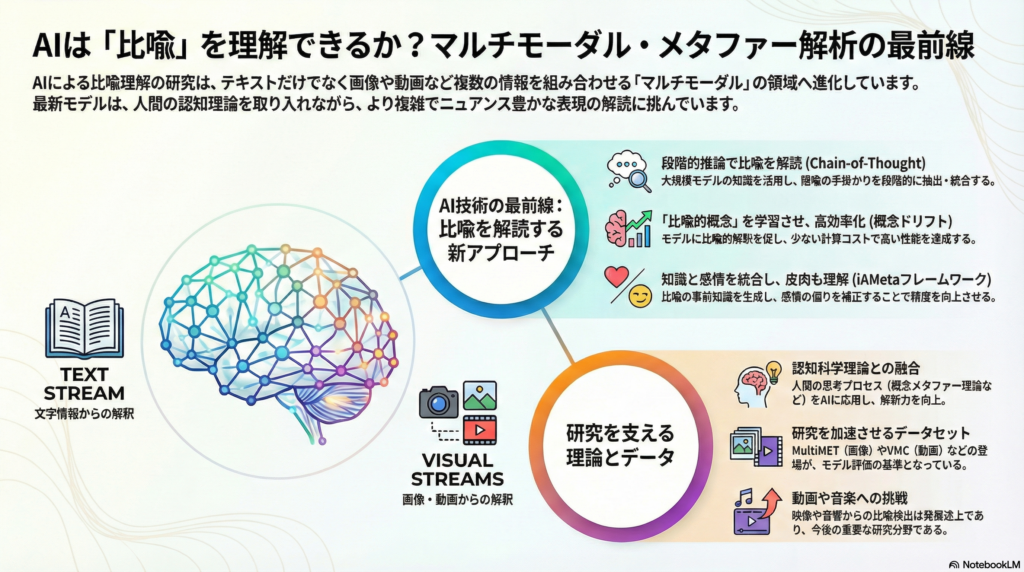
マルチモーダルAIモデルによる比喩検出の技術革新
Chain-of-Thought推論による段階的比喩理解
テキストと画像を組み合わせた比喩理解において、大規模言語モデル(LLM)とビジョンモデルを統合したマルチモーダル大規模言語モデル(MLLM)が注目されています。しかし、比喩のような暗黙的な意味理解では、依然として人間の能力に及ばない課題があります。
この課題に対し、Xuら(2024)が提案したC4MMDフレームワークは画期的なアプローチを示しました。Chain-of-Thought(CoT)手法を導入し、MLLMから抽出した知識を小規模モデルに統合することで、段階的に隠喩の手掛かりを抽出・統合します。この手法により、ソーシャルメディアの広告やミーム画像中の比喩検出性能が従来モデルを大きく上回る精度を達成しています。大規模モデルの知識蒸留と逐次推論を組み合わせた体系的なアプローチは、比喩理解の新たな方向性を示しています。
セマンティック・コンフリクトを活用した比喩検出
比喩表現では、異なるモダリティ間に意味的な衝突が生じることがあります。例えば「燃えるような恋」というフレーズは、文字通りには成立しない情景を描きます。このような特性を活用したのが、HeらによるSC-Netモデルです。
SC-Netは、テキストと画像の意味不一致から比喩性を検出するネットワークで、言語学の比喩理論を計算モデルに組み込んでいます。モダリティ間の対照に着目することで、単一モダリティでは見逃される比喩を効果的に検出できる可能性が示されています。
概念ドリフトによる効率的ファインチューニング
Qianら(2025)が提案した**概念ドリフト誘導LayerNormチューニング(CDGLT)**は、比喩タスクに特化した効率的なファインチューニング手法です。この手法では、CLIP画像エンコーダのマルチモーダル埋め込み空間上で球面線形補間(SLERP)を用いて、「字義的概念」と「比喩的概念」の中間に位置する新たな概念ベクトルを生成します。
このベクトルを入力特徴に加えることで、モデルに比喩的解釈を促し、高コストな生成型モデルに頼らずに最先端性能を達成しました。ソーシャルメディア上の比喩豊富なミームデータセットMET-Memeでは、従来手法を上回る精度と大幅に改善された計算効率を両立しています。
知識生成と感情バイアス補正の統合アプローチ
2025年に提案されたiAMetaフレームワークは、MLLMを活用した対照思考にもとづく知識生成と感情バイアス補正を組み合わせた手法です。このモデルでは、大規模視覚と言語モデルを用いて「比喩か否か」の事前知識を段階的に推論します。
具体的には、まず比喩と非比喩の特徴を対比学習で抽出し、その上で全体の判断を行います。さらに感情情報の多タスク学習で比喩による感情の偏りを補正し、因果推論により画像と言語の不適切な連想を減らす工夫も導入されています。結果として、比喩検出と感情分析の両タスクで高い性能を示し、特に皮肉など複雑なケースにも強いロバスト性を発揮しました。
マルチモーダル比喩生成への挑戦
比喩理解と生成は表裏一体の関係にあります。Chakrabartyら(2023)による「I Spy a Metaphor」研究では、LLMにChain-of-Thoughtで視覚的連想を文章生成させ、その結果を拡散モデルに与えて視覚メタファー画像を生成する試みが行われました。
1,500以上の言語メタファーから6,000以上の視覚メタファー画像が人間とAIの協調で作成され、専門家による評価でもLLMと画像生成モデルの協調の有望性が示されています。このような生成実験から得られる知見は、比喩の解釈モデル構築にもフィードバックを与え、理解と生成の相互作用が研究を前進させています。
主要なマルチモーダル比喩データセットと研究成果
マルチモーダル比喩理解の研究を支える重要なデータセットと研究成果を時系列で整理します。
2021年:MultiMETは、1万件以上のテキスト-画像ペアからなる初の大規模比喩データセットです。比喩の有無だけでなくドメイン間の対応関係や感情・意図まで注釈されており、マルチモーダル情報の相互作用が比喩理解に重要であることを示しました。
2022年:Ring That Bellは、音声・字幕付き動画中の比喩を専門家がアノテーションした初の公開コーパスです。テキスト(字幕)のみを用いたモデルでF1スコア62%を達成しましたが、画像や音響を加えた手法では大きな上積みが得られなかったと報告されています。
2024年:V-FLUTEは、比喩・直喩・慣用句・皮肉・ユーモアの5種類、計6,027件の画像と言語キャプションペアで構成されるデータセットです。画像が前提、テキスト主張が仮説となり、含意を判定して説明文を生成するタスクで、モデルの比喩的理解と説明能力を評価します。
**2024年:VMC(Video Metaphor Captioning)**は、比喩的表現を含む動画705本について、それぞれの隠喩内容を1文のキャプションで記述する新タスクです。計2,115件の字幕が付属し、低リソース環境向けにVision-LanguageモデルLLaVAをGPTと組み合わせたGIT-LLaVAモデルが提案されています。
これらのデータセットは、マルチモーダル比喩理解のベンチマークとして機能し、研究コミュニティ全体の進展を加速させています。
動画・音楽など時系列メディアにおける比喩解析
動画中の比喩検出における課題と進展
動画や音楽といった時系列メディアにおける比喩の自動解析は、研究が始まったばかりの領域です。映像は連続するビジュアルと音響情報からなり、シーン展開やコンテクストによって暗示される比喩も多様です。
Alnajjarら(2022)による「Ring That Bell」コーパスの研究では、短い動画クリップ(音声と字幕付き)の中で人間が隠喩的表現を含む部分に注釈を付けています。提案手法では動画の字幕テキストのみを入力したモデルがF1スコア62%で隠喩ラベルを予測しましたが、画像フレームや音声特徴を組み込んだモデルはそれ以上の性能を発揮できませんでした。
エラー分析によれば、一部のケースでは映像情報が隠喩の曖昧性解消に役立つものの、多くの場合視覚的手がかりが微妙すぎてモデルが捉えられなかったと報告されています。この結果は、動画内の比喩の多くが会話やナレーション(テキスト情報)に依存しており、現状のモデルでは視覚・音響情報を巧みに活用できていないことを示唆しています。
映像比喩の説明的キャプション生成
比喩を検出するだけでなく、映像が含意する暗喩を言語で説明するタスクも提案されています。Rajakumarら(2024)による「Video Metaphor Captioning(VMC)」は、比喩的な内容を持つ短編動画705本に対し、それぞれ映像の隠喩を捉えた1行の説明文を生成することを目的としています。
視覚言語モデルGITと対話型MLLMであるLLaVAを組み合わせたGIT-LLaVAモデルを開発し、低リソース下でも最先端モデルに匹敵する性能を示しました。例えば、CM映像に映る「氷山の一角」を示すシーンに対し「企業の問題の表面化を示唆する比喩的光景」といったキャプションを生成するようなケースが想定されます。映像から暗示を読み取り自然言語で要約するこの手法は、映画やCMの隠れたメッセージ解読や、映像コンテンツのメタデータ自動生成に繋がる可能性があります。
音楽における比喩表現の解析
音楽はメロディや歌詞を通じて豊かな比喩を伝達します。特に歌詞は詩的メタファーや感情的隠喩の宝庫であり、自動歌詞解析による比喩検出も研究されています。NLP技術を用いて歌詞中のメタファー表現を抽出・分類し、その背後にある感情やテーマを解釈する試みが進められています。
一方、歌詞を持たない器楽曲や純粋なサウンドにおける比喩的表現の自動解析は極めて難しい課題です。現状では、人間が音楽を記述する際の比喩(例:「この曲は明るく陽気な雰囲気だ」のように視覚・感情に喩える)を分析するアプローチが主流です。
Garyら(2025)の研究では、観光地PR用の短編映像における音楽と映像の組み合わせがブランド印象に与える効果を調べ、認知メタファー理論を用いて「音楽が文化的意味を担い映像と合わさることでブランド共感を生む」ことを示しています。音楽と言語・映像を統合した比喩効果の分析は主に認知実験やマーケティング研究で行われており、AIによる自動解析はこれからの開拓分野といえます。
認知モデル理論とAI応用の融合
概念メタファー理論(CMT)の計算機応用
人間の比喩理解メカニズムについては、認知科学・認知言語学で長年にわたり理論研究が蓄積されています。LakoffとJohnsonによる概念メタファー理論(CMT)は、「ある概念領域(ターゲット)を別の概念領域(ソース)に照らして理解する」心的マッピングが比喩の本質であると説きました。
例えば「人生」という抽象概念を「旅」という具体的経験になぞらえる(LOVE IS A JOURNEYのようなドメイン間対応)といったドメイン間マッピングが多数存在するとされます。この理論は計算機にも応用され、比喩表現中のソース概念とターゲット概念を同定して知識ベースと照合することで隠喩解釈を試みる手法などが研究されてきました。
近年では、LLMに対しこの理論をガイドラインとして与え、大規模テキストから概念メタファーのパターンを発見させる取り組みも登場しています。Hickeら(2024)は人間のメタファーアノテーション手法(MIP法など)をLLMのプロンプトに組み込み、LLMが大規模コーパス中の概念メタファーを高精度に抽出・説明できることを示しました。これはCMTをLLMの認知的プロンプトとして用いた先駆的研究であり、人間の比喩理解理論がAIの解釈力向上に役立つ可能性を示しています。
ブレンディング理論と創造的AI
FauconnierとTurnerによるブレンディング理論(概念ブレンド)は、2つ以上の精神空間(シナリオ)から選択的に要素を取り出し、新たな意味構造を創出する概念ブレンドのプロセスで比喩や創造的発想を説明します。比喩ではソースとターゲットの要素がブレンドされて新たな意味空間が生まれると捉え、この理論は創造的AIにも影響を与えています。
Ahmedら(2023)は、デザイン支援システム「Creative Blends」において、抽象概念を象徴する視覚メタファーを得るために異なるオブジェクトのビジュアルブレンドを行う手法を提案しています。ブレンディング理論の視点から、ディープラーニングモデルが持つ概念表象を組み合わせることで新奇なメタファー生成を行う試みといえます。
また、比喩とユーモアの関係をブレンディングで説明しようとする研究や、複数の比喩が文脈で動的に変容する様子をモデル化する動的メタファー理論の提案もあります。後者では、比喩には「生きている/死んでいる」といった静的区分では捉えきれない文脈依存の躍動があるとし、言語フレームに沿ったメタファーの流動的変化を計算モデルに組み込む構想が議論されています。
カテゴリー化理論とシンボリックAIの統合
比喩理解は類推推論(Analogical Reasoning)の一種とみなすこともできます。構造マッピング理論では、ソースとターゲットの関係構造を対応付けることで比喩を理解するとされ、計算モデルとしてはグラフマッチングによる対応抽出などが試みられてきました。
Glucksbergのカテゴリー化理論では「X is a Y」という比喩文は「YのカテゴリーにXを入れる」というカテゴリー包括の操作と解釈します。この考えに基づき、計算機において単語ベクトル空間上でソース語とターゲット語を組み合わせ新たなベクトルを生成し、その近傍語から比喩の隠れた意味を推定するといった手法も検討されました。
2025年のIJCAI会議では、Lietoらが典型性に基づく概念論理(TCL)を用いてメタファーの生成と認識を行うシステムMETCLを報告しています。これはカテゴリ理論的に、メタファー解釈を「人間らしい常識的概念の組合せ(カテゴリー生成)」問題と見なし、シンボリックAIとLLMを組み合わせて比喩識別と生成を実現したものです。評価では、METCLがGPT-4など最新のLLMよりも高精度に比喩検出でき、人間が評価しても自然と受け入れられる比喩生成ができるとされています。この成果は、比喩理解を単なる言語処理ではなく概念レベルでの推論・カテゴリ化として捉える認知的アプローチの有効性を示しています。
学際的アプローチの重要性と実践例
比喩理解の研究は、AIと認知科学・言語学・芸術研究など学際的な連携が不可欠です。人間の比喩理解メカニズムを探る認知科学の知見がモデル設計に活かされ、逆にAIによる大規模データ分析が認知理論の検証や新発見につながるという双方向のフィードバックが起きています。
例えば、言語学では隠喩識別プロトコル(MIP)という人手アノテーション手法が確立されており、これをAIトレーニングデータに用いることでモデルの解釈力を高めることができます。また、認知言語学で提案されたメタファーの構造マッピングやドメイン知識は知識グラフや共通常識データベースとして実装され、モデルの知識源として統合されています。
感情分析やユーモア検出の研究者も含め、比喩・皮肉・風刺といった幅広いフィギュラティブ(figurative)な現象を扱うため、心理学者や社会学者との協働も進んでいます。音楽情報処理や映像メディア研究の分野でも、比喩表現は共通の関心事です。マーケティング研究では認知メタファー理論を用いて音楽と映像の相乗効果を分析したり、映像作品論では映像メタファーの読み解きが行われています。
これら人文学分野の知見をAIモデルに取り入れることで、単一の工学的手法では捉えきれない文化的・文脈的な意味合いまで理解できるマルチモーダルAIが期待されています。実際、最新の比喩研究には心理学・認知科学の理論を取り入れたものが多く見られ、例えば前述のiAMetaは感情情報を制御信号として組み込みました。このように学際的アプローチによって、より人間らしい比喩理解に迫るモデル構築が目指されています。
国際会議・ジャーナルでの研究動向
自然言語処理(NLP)分野の取り組み
ACLやEMNLPなどトップ会議では、言語メタファー検出のセッションやFigurative Language Processing Workshopが継続的に開催され、近年はマルチモーダル比喩にも議論が広がっています。ACL 2021では初のマルチモーダル比喩データセットMultiMETが発表され、ACL 2024ではマルチモーダルCoTによる比喩検出など先端手法が報告されました。
2024年NAACLでは前述のV-FLUTEデータセットが紹介され、EMNLP 2025のFindingsでは画像メタファー理解の包括的ベンチマーク(ImageMetデータセット)が発表されるなど、NLPコミュニティでの関心が高まっています。
コンピュータビジョン(CV)分野の展開
CVPRやICCVにおいても、画像と言語を組み合わせた高次タスクとして視覚的ユーモアや比喩への取り組みが始まっています。ICCV 2025では視覚文脈が発話の含意理解に与える影響を測るVAGUEデータセットが公開され、マルチモーダルモデルでも人間のように皮肉や誇張を文脈から読み解くことが困難であると示されました。
これは比喩解釈と直接ではありませんが、あいまいな表現の解釈という点で通底しており、視覚と言語の統合推論の難しさが議論されています。また、CV分野では広告の視覚メタファー検出や創造的画像生成の文脈で、比喩理解に関連する研究が散見されます。
マルチモーダルインタラクションと知識ベースシステム
ICMIやAAAIなどでは、マルチモーダルな皮肉検出・感情理解の文脈で比喩が扱われています。またJournal of Information FusionやKnowledge-Based Systems誌では、マルチモーダル融合による比喩理解やミーム解釈の論文が近年増えています。例えばInformation Fusion 2025にはiAMeta論文が掲載され、Knowledge-Based Systems 2024にはミームの多角的理解に比喩情報を組み込む研究が報告されています。
認知科学・言語学分野との連携
CogSci(認知科学会議)や言語学関連の学会でも、メタファーの認知的処理や言語発達における比喩の役割などが議論されています。これらの場では計算モデルだけでなく人間実験によるデータも提示され、AIモデルの評価指標として人間の比喩理解プロセスが参照されます。認知言語学のジャーナル「Metaphor and Symbol」や「Journal of Pragmatics」などでは計算機によるメタファー解析の特集が組まれることもあります。
このように、マルチモーダル比喩理解は自然言語処理、コンピュータビジョン、マルチモーダル対話、認知科学といった複数領域の交差点で発展している分野です。それぞれのコミュニティが持つ知見を融合することで、より高度な比喩理解AIの実現が期待されています。
まとめ:マルチモーダル比喩理解の未来展望
視覚・音声を含む完全マルチモーダルな比喩理解に関する研究は、ここ数年でようやく本格化してきた新しい挑戦領域です。最新のモデルやデータセットは比喩理解能力を高めつつありますが、人間のように文脈を踏まえて多義的な暗喩を解釈するには依然大きなギャップが存在します。
Chain-of-Thought推論、概念ドリフトチューニング、知識生成と感情バイアス補正の統合など、様々な技術的アプローチが提案されています。また、概念メタファー理論やブレンディング理論、カテゴリー化理論といった認知科学の知見を計算機モデルに応用する試みも進んでいます。
今後、認知モデルのさらなる統合、マルチモーダル大規模モデルの活用、および学際的協働によって、このギャップを埋めていくことが期待されます。比喩は言語文化の深層に根差す現象であり、それを理解するAIの発展は、人間の思考と創造性を機械がいかに模倣・拡張できるかという問いへの一つの回答となるでしょう。
マルチモーダル比喩理解の研究は、AI技術の進化だけでなく、人間の認知プロセスの解明にも貢献する可能性を秘めています。この分野の発展は、より自然で人間に近いAIコミュニケーションの実現に向けた重要なステップといえます。
コメント