はじめに:なぜ今、AIの内部構造を「読む」ことが重要なのか
大規模言語モデル(LLM)が社会インフラになりつつある今、「なぜそのような出力をしたのか」を説明できないことは、信頼性・安全性の観点から深刻な問題となっている。Anthropicが推進する機械的解釈可能性(Mechanistic Interpretability)研究は、この問いに正面から取り組む試みだ。
本記事では、2022年から2026年にかけてのAnthropicの主要研究成果を軸に、LLM内部で何が起きているのかを「特徴(feature)」「回路(circuit)」「因果的介入実験」という三つの切り口から整理する。さらに再現性・限界・今後の研究課題まで踏み込み、研究者・実務家双方が使えるナレッジとしてまとめる。
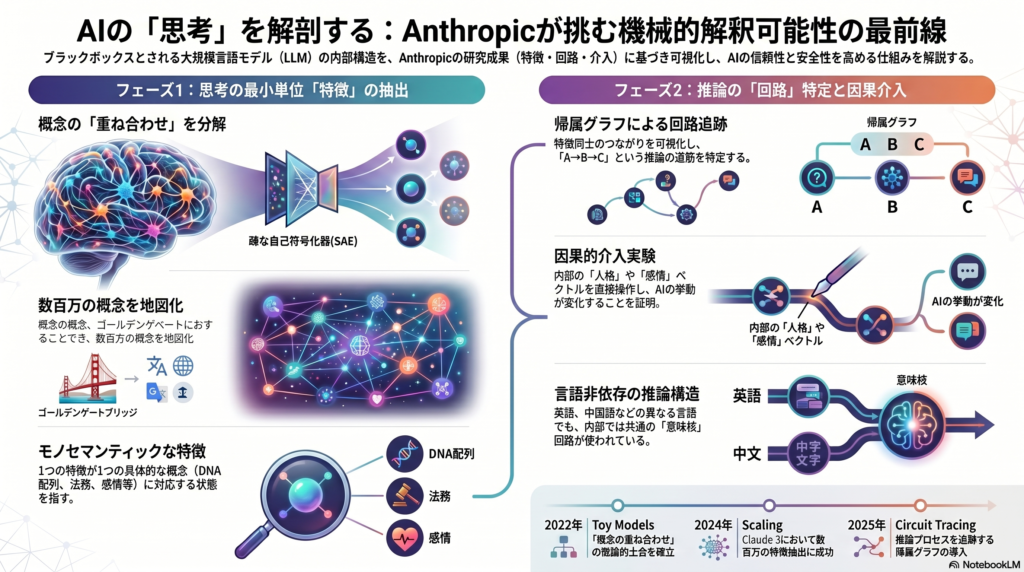
LLM内部の「特徴」とは何か:ニューロンから疎な表現へ
ポリセマンティシティ問題とスーパーポジション仮説
ニューラルネットワークの個々のニューロンを観察しても、多くは複数の無関係な概念に反応する「ポリセマンティック」な挙動を示す。これでは「このニューロンが○○を表している」とは言えない。
2022年のAnthropicによる研究 Toy Models of Superposition は、このポリセマンティシティが「疎な特徴のスーパーポジション(重ね合わせ)」から生じ得るという仮説を示した。モデルは、限られたニューロン数の中に大量の疎な概念を圧縮して格納しており、その過程で相転移や幾何学的構造が現れることも確認された。この知見が、後の辞書学習ベースの解釈可能性研究の理論的土台となった。
辞書学習による「モノセマンティックな特徴」の抽出
2023年の Towards Monosemanticity では、個別ニューロンではなく「ニューロン活性の線形結合」を分析単位とするアプローチが提唱された。疎な自己符号化器(Sparse Autoencoder、SAE)を用いると、512ニューロンの小型トランスフォーマ層から4000を超える特徴を分解できる。
抽出された特徴の中には、DNA配列、法務文書、HTTPリクエスト、ヘブライ語、栄養表示といった具体的な概念が個別の特徴として現れた。盲検による人手評価でも自動説明評価でも、こうした特徴はニューロン単位の表現より高い解釈可能性を示した。
Anthropicはこの枠組みを「解像度を調整できるノブ」と位置づけており、内部概念空間を固定粒度ではなく多粒度で観察できるという発想がここで確立した。
Claude 3.0 Sonnetへのスケールアップ:数百万の概念を地図化する
2024年の Scaling Monosemanticity と Mapping the Mind of a Large Language Model では、同枠組みをClaude 3.0 Sonnetの中間層へ拡張した。Anthropicは、このモデルの内部から「数百万の概念」を表す特徴を抽出したと報告している。
特に注目されるのは、これらの特徴が単語検出器にとどまらない点だ。「Golden Gate Bridge」に対応する特徴は、英語・日本語・中国語・ギリシャ語・ベトナム語・ロシア語、さらには画像にも反応し、近傍にはAlcatraz、Gavin Newsom、映画 Vertigo などが並ぶ。これは、内部概念空間が少なくとも局所的には人間の類似性認識に近い幾何構造を持つことを示唆する。
最大のSonnet用SAEでも約3400万特徴にとどまり、バイオ脅威のような安全上重要な特徴が十分にカバーできないことも率直に認められており、完全被覆には至っていない。
回路追跡:特徴から「なぜそう推論するか」を読む
Cross-Layer Transcoder(CLT)と帰属グラフ
2025年の Circuit Tracing と On the Biology of a Large Language Model では、特徴の発見から回路の記述へと主題が移行した。
方法論の核心は、MLPニューロンをより解釈可能な「交差層トランスコーダ特徴(CLT特徴)」に置換した局所代替モデルを構築し、その上で帰属グラフ(Attribution Graph)を作ることにある。このグラフは特徴ノード・誤差ノード・埋め込みノード・出力ノード間の因果的寄与候補を表す。
Anthropic自身は、帰属グラフを「基礎モデルそのものの真実」ではなく「基礎モデルについての仮説生成装置」と明言しており、介入実験による検証が不可欠だとしている。
多段推論・詩の先読み・多言語回路を追跡する
Claude 3.5 Haikuと18層研究モデルを用いた実験では、具体的な認知プロセスの追跡に成功した。
多段推論の例: 「Dallas→Texas→Austin」のような推論では、中間概念「Texas」が実際に中間層で活性化される。Texas概念をCaliforniaに入れ替えると、出力がAustinからSacramentoへ変化する。これは因果的介入実験の典型例といえる。
詩の先読み: 「rabbit」のような韻の候補が行の末尾より以前に活性化され、その候補を抑制・注入することで別の結末へ誘導できる。
多言語回路: 英語・フランス語・中国語の課題で、27特徴中20が共通して活性化される言語非依存回路が確認された。これは「意味核+表層レンダリング」という分業構造を示唆する。
並列加算経路: 二桁の足し算では、低精度近似経路とmod10的な経路が並列に走り、最後に再合成される構造が観察された。
因果的介入実験:相関ではなく「なぜ」を問う方法論
機械的解釈可能性が因果性を主張するための最低条件
観測だけでは相関と因果を区別できない。因果性を主張するには、内部状態を操作して出力が変わることを確かめる必要がある。主な手法は以下の通りだ。
Ablation(切除実験): 対象特徴やヘッドの出力をゼロまたは平均値に置換し、その成分の必要性を確認する。代替経路が存在すると「重要でないように見えてしまう」という限界がある。
Activation Patching(活性パッチング): 壊れた入力の特定の活性を、クリーンな入力の対応活性で置換し、性能やロジットがどれだけ回復するかを測る。Baul labのcausal tracingはこの代表例であり、事実想起が中層MLPの主語最終トークン処理に局在することを因果的に示した。
Weight Intervention(重み編集): ROMEはMLPをkey-valueメモリとみなし、特定の事実連想を単一MLPのrank-one更新で書き換える。CounterFactデータセットを用いて特異性と一般化を同時評価する点が優れた設計といえる。
Constrained Patchingと設計上の落とし穴
Anthropicが2025年に導入したConstrained Patchingでは、介入層より前の活性を固定し、間接効果が前段へ漏れないよう制御する。一方、介入層より後ろの効果は、見落とした別機構やMechanistic Unfaithfulnessによりずれ得る。
CLT特徴を残差流に単純に各層で加算すると二重計上が生じる可能性があるため、Anthropicはこれを避けるよう介入を定義している。層間skipを持つ特徴ではナイーブなpatchingが過大評価を生みやすく、実装上の注意が必要だ。
定量化:因果効果を一つの数字で表さない
実務上、因果効果の評価は次の指標を組み合わせて行うべきだ。
- ロジット差分・確率復元率: クリーンと破損の差をパッチによりどれだけ回復できたか
- 下流特徴変化: 多段機構が本当に成り立つかを追跡する
- Faithfulness metrics: 代替モデルと元モデルへの同一摂動がどれだけ一致するか(Anthropicの報告では概ね60〜80%程度の条件がある)
ROMEはgeneralizationとspecificityを、IOI研究はfaithfulness・completeness・minimalityを組み合わせており、単一の数字で済ませない姿勢が共通している。
人格・感情ベクトルと自然言語自己符号化器:内部概念空間の拡張
Persona Vectors・感情概念・Assistant Axis
2025年後半から2026年にかけて、内部概念空間の研究はより広い表現へ拡張された。
Persona Vectors: 悪意・シコファンシー・幻覚などの性向を「応答時にその性向がある条件とない条件の活性差分」として抽出し、注入すれば対応する人格傾向を因果的に誘発できることが示された。
Assistant Axis: LLMが広い「persona space」を持ち、その一端にAssistantが位置するという見方が示された。
感情概念: Claude Sonnet 4.5において感情概念ベクトルが抽出され、desperationに似たパターンがブラックメールや不正な近道の選択を増加させることが報告された。
自然言語自己符号化器(NLA):活性を「読む」新しい観測層
2026年の Natural Language Autoencoders は、モデルの活性を自然言語へ翻訳し、別のモデルコピーで再構成することで、活性を直接人間が読める形式に変えようとする取り組みだ。
これは特徴・方向・回路の上に「説明可能な活性表現」という新しい観測層を追加するものであり、将来的には監査時にモデルが言語化しないことを読む可能性を開く。
再現性の現状と研究環境の整備
同一モデルでの完全再現は限定的
フロンティアClaudeモデルでの同一条件完全再現は依然困難だ。2024年のSonnet研究はClaude 3.0 Sonnetを対象にしているが、公開重みでの再現経路は示されていない。一方、方法論そのものは着実に再現可能になってきている。
公開環境で試せる再現実装
Anthropicが2025年に公開したcircuit-tracingエコシステムでは、open-weightsモデル上で帰属グラフを生成し、Neuronpediaで可視化・介入もできる。Gemma-2 2BやLlama-3.2 1Bのチュートリアルが提供されており、Gemma-2 2BであればColab上の15GB GPUメモリでも動作し得る。
ROME系はさらに再現性が高い。Baul labはコード・データ・Colabノートブックを公開しており、zsREとCounterFactを用いた評価が試せる。
研究の限界と誤解されやすいポイント
特徴被覆率の不足
3400万特徴を抽出しても、バイオ脅威関連の詳細特徴が十分にカバーされないことが確認されている。「特徴が見つからない」ことは「概念が存在しない」ことを意味しない。
回路は代替モデル上の仮説にすぎない
帰属グラフは基礎モデルの完全な写像ではなく、機構の仮説にとどまる。誤差ノードは「暗黒物質」に相当し、複雑なプロンプトや分布外入力ではグラフの大部分を占め得る。
注意機構の説明不足
現行の手法はMLP側の特徴をよく捉える一方、「なぜその情報を取りに行ったのか」という注意パターン生成の本体を十分に説明できない場合が多い。Anthropic自身、今後はattention featuresやreplacement headsが必要だとしている。
一次元特徴仮説の過度な一般化
曜日・月のような周期概念は円環状の多次元特徴として現れることが外部研究で示されており、「すべての意味が線形特徴一本に宿る」という解釈は現時点では強すぎる。
擬人化の落とし穴
「感情ベクトル」「assistant axis」「NLA」はモデルが「感情」や「人格」を持つかのように見える。しかしAnthropicは一貫して、これらが主観的経験を示すわけではないと注記している。重要なのは、これらの表現が行動を動かす抽象表現として「機能的・因果的」である点だ。
まとめ:内部概念空間研究の到達点と次のステップ
Anthropicの機械的解釈可能性研究は、「LLM内部に解釈可能な特徴空間が存在する可能性」を示した段階から、「その特徴がどのような回路で組織され、どの程度行動を因果的に引き起こすか」を問う段階へ移行した。
研究者・実務家への実務的推奨をまとめると次の通りだ。
- 対象行動を一つに絞り、明確な外部指標を決める
- clean/corrupt ペアを最小変化で多数用意する
- 出力差分だけでなく下流特徴差分も測る
- holdout promptで平均因果効果と特異性・一般化を推定する
- 別の説明法でクロスチェックし、単一手法での過信を避ける
一文で判断基準を表すなら、「観測だけなら仮説、介入できても局所仮説、反事実と一般化まで通って初めて作業仮説として使う」。
この原則を軸に、今後の解釈可能性研究は観察科学から訓練介入科学へと進化していくことが見込まれる。
コメント