マルコフ毛布とは何か――因果推論における局所的な情報境界
ベイジアンネットワーク上のある変数 T に対し、その親ノード(直接原因)、子ノード(直接影響)、子ノードの他の親(配偶者)で構成される最小の変数集合をマルコフ毛布と呼ぶ。この集合を条件付けると、T はネットワーク上の他のすべての変数から条件付き独立になる。つまり、T の予測や因果推論に必要十分な情報がこの毛布の中に閉じ込められている。
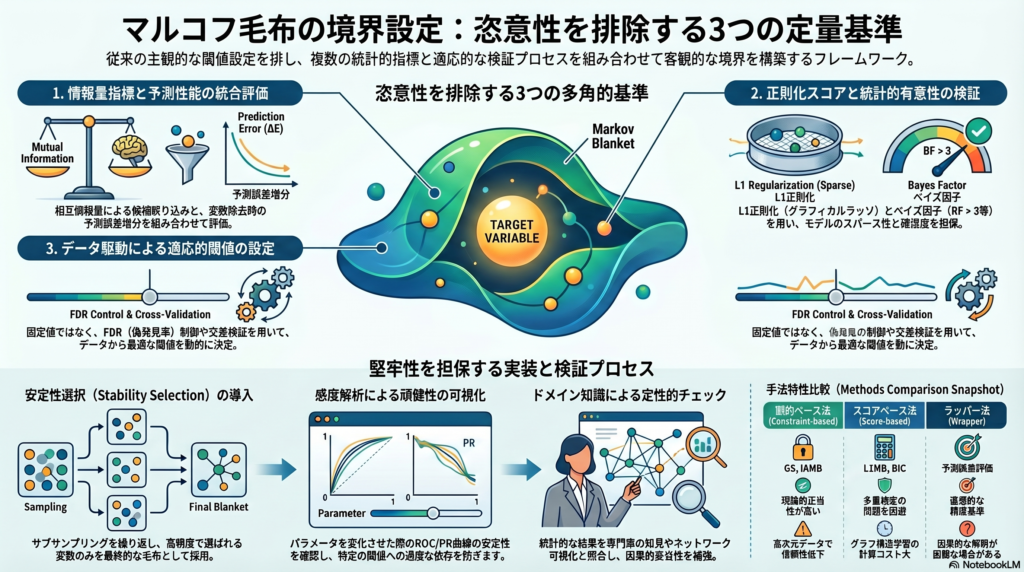
医療診断におけるバイオマーカー選択や、遺伝子ネットワーク解析における発現制御因子の同定など、実務で「本当に必要な変数だけを抽出したい」場面でマルコフ毛布の概念は強力な道具になる。しかし問題は、実データからこの毛布を発見する過程で、閾値設定や検定手法の選び方によって結果が大きく揺れることだ。この恣意性をどう減らすかが、本記事の主題である。
既存のマルコフ毛布探索アルゴリズムを整理する
制約ベース法:条件付き独立検定に基づくアプローチ
代表的な手法としてGrow-Shrink(GS)法、IAMB、HITON-MBがある。GS法はMargaritisとThrunが提案した前進・後退探索であり、理論的な正当性が保証される一方、前進段階での誤検出が起きやすい。IAMBは条件付き相互情報量を用いて動的に変数を追加・削除する改良版で精度が向上するが、縮小段階での検定数が増大する課題を抱える。HITON-MBは親子ノードをまず特定してからスパースな候補を絞り込む設計で、サンプル効率に優れるものの、信仰律(faithfulness)の成立を前提とする。
これらの手法は小規模データで正当性が担保されやすい反面、変数の次元が増えると条件付き独立検定の信頼性が急速に低下する傾向がある。
スコアベース・正則化法:高次元に強い統計的手法
L1正則化(グラフィカルラッソ)を用いて隣接リストを推定し、BICやMDLで最終的なモデルを選択する方法がこのカテゴリに属する。多重検定の問題を回避できる利点がある一方、各正則化パラメータでの回帰計算が必要なため計算コストが高い。SchmidtらのL1MBはこの代表例であり、高次元の遺伝子発現データなどで実績がある。
スコアベースの探索(MDLやBDe)はモデル全体で最適化できるが、グラフ構造学習自体がNP困難であるため、変数数が多い場合は近似解法に頼らざるを得ない。
ラッパー法:予測性能で毛布を評価する
選択した変数集合で予測モデルを学習し、誤差の変化を観測するアプローチである。予測性能という直感的な基準が使える反面、得られた変数集合の因果的解釈が難しくなる。予測精度の向上が因果関係を意味するとは限らない点に注意が必要だ。
これら三つのアプローチにはそれぞれトレードオフがあり、いずれか一つの基準だけに依存すると、閾値の恣意性や検定方法の選択バイアスが結果を左右してしまう。
複数基準を組み合わせた定量的境界設定の提案
情報量指標による候補絞り込み
すべての変数 X についてターゲット T との相互情報量 I(T;X) または条件付き相互情報量 I(T;X∣S) を算出し、上位の変数を候補として抽出する。この段階で多重検定補正(BonferroniまたはBenjamini-HochbergによるFDR制御)を適用し、統計的に有意な変数だけを残す。情報量は変数の型(離散・連続)に応じて推定法を変える必要があり、連続変数ではカーネル密度推定やk近傍法を用いることが多い。
予測性能の増分評価
候補集合を用いた予測モデルを構築し、各変数を一つずつ除去した際の誤差増分 ΔEX を測定する。誤差が有意に増大する変数は毛布に不可欠であり、変化が小さい変数は除外候補となる。この評価には交差検証を組み合わせ、過学習による偽の重要性判定を防ぐ。
正則化スコアによるスパース化
ターゲット T に対してL1正則化回帰を適用し、正則化パスに沿って非ゼロ係数を持つ変数集合を追跡する。BICまたはMDLが最良となるモデルの変数集合を採用し、さらに尤度貢献の低い変数を追加検定で除去する。この手法は多重検定を直接扱わずに済む点で、制約ベース法と相補的な役割を果たす。
統計的有意性とベイズ因子
各変数について χ2 検定や偏相関検定を実施し、FDRで p 値閾値を制御する方法に加え、ベイズ因子を用いたモデル比較も有効である。変数 X を含むモデルと含まないモデルのベイズ因子が一定閾値(例えばBF > 3)を超える場合に X を採択する。ベイズ因子はサンプルサイズに対して p 値よりも安定した判断を与える場合がある。
アルゴリズム全体の流れ
実装としては、まず情報量指標で候補を絞り、FDRで閾値を設定した上で前進的に毛布に追加する。次に後退フェーズで条件付き独立検定により不要変数を除去し、最後に予測性能の交差検証やブートストラップで安定性を確認する。鍵は閾値 α を固定値にせず、データから適応的に決定する点にある。
感度解析と頑健性評価の設計指針
提案基準の信頼性を担保するには、パラメータ変動に対する感度解析が不可欠である。
閾値の変化に対しては、p 値やベイズ因子の判定水準を幅広く動かし、真陽性率と偽陽性率をROC曲線やPR曲線で可視化する。ここで曲線下面積(AUC)がパラメータ選択に過敏でなければ、基準の頑健性が示唆される。
サンプルサイズの影響は、同一の因果構造からサンプル数を段階的に変化させてデータを生成し、検定力と誤検出率の推移を観察することで評価できる。ノイズ耐性については、データ生成過程にガウスノイズやクラスラベルの反転を加え、毛布の構成がどの程度安定するかを測定する。
これらの解析で特に有効なのが安定性選択の枠組みである。サブサンプリングを多数回繰り返し、各変数の選択頻度を集計する。高頻度で選ばれる変数のみを最終毛布に残すことで、特定の閾値への過度な依存やサンプル固有のノイズの影響を緩和できる。
シミュレーション実験の設計
評価用シミュレーションでは、真のマルコフ毛布構造が既知である合成データを生成する。変数数は10から500程度、サンプルサイズは100から5000程度の範囲で段階的に設定し、グラフ構造としてはランダムベイジアンネットワーク、スケールフリー構造、ツリー構造を用意する。変数型は離散(二値・多値)と連続(ガウス分布)の両方を扱い、信号対雑音比を低・中・高の三段階で変化させる。
さらに、信仰律(faithfulness)が成立するケースと破れるケースの両方を含めることで、各手法の前提条件への依存度を明らかにする。評価指標としては、真陽性率、偽陽性率、Precision、Recall、AUC、予測性能の改善度、計算時間を計測する。強い因果関係を弱めた場合の検出率低下や、変数間相関が高い場合の誤検出増加などを系統的に調査することが、手法の実用限界を見極める上で重要になる。
実データへの適用における手順と注意点
データ前処理と検定法の選択
実データでは欠損値処理や外れ値除去が前提となる。連続変数を離散化する場合はビニング手法の選択が結果に影響するため、等頻度分割と等幅分割を比較検討するとよい。離散データには χ2 検定やG²検定、連続データには偏相関検定やカーネル条件付き独立検定を用いる。データの性質に応じた検定法の選択が、毛布探索の精度を左右する。
モデル前提の確認とドメイン知識の活用
ベイジアンネットワークの前提である信仰律、潜在変数の不在、因果的十分性が実データで満たされるとは限らない。これらの前提が破れている可能性がある場合は、得られた毛布を因果構造として直接解釈することに慎重であるべきだ。専門家の知識やネットワークの可視化による定性的チェックを組み合わせることで、統計的結果の妥当性を補強できる。
代表的な検証用データセット
Asiaネットワーク(8ノード、医療診断モデル)やALARMネットワーク(37ノード、麻酔モニタリング)は因果構造が既知であり、手法のベンチマークに適している。Sachsらの細胞シグナルデータも因果ネットワーク構造が検証されており、実データでの評価に有用である。高次元データとしては遺伝子発現マイクロアレイやメタボロームデータがあり、L1正則化と安定性選択の組み合わせが特に効果的と報告されている。
まとめ――多角的基準と適応的閾値で恣意性を排除する
マルコフ毛布の境界設定において恣意性を減らすためには、単一の基準に頼らず、情報量・予測性能・正則化・統計検定という複数の視点を組み合わせることが有効である。閾値はFDRや交差検証、パーミュテーション検定によってデータから適応的に決定し、安定性選択やブートストラップで再現性を確認する。この多角的なアプローチにより、既存のIAMBやHITONなどの手法を補完し、より堅牢な毛布検出が期待できる。
実務上は「少なくとも2種類以上の基準を併用する」「閾値はデータ駆動で決定する」「選択結果の再現性をブートストラップで検証する」「ドメイン知識で理論的妥当性を担保する」という四つの原則を守ることが推奨される。
コメント