はじめに
大規模言語モデルの発展において、一方向的な処理から脱却し、より人間的な思考プロセスに近づくことが重要な研究テーマとなっている。人間の知的活動では、一度の判断で終わらず、自分の思考を振り返り、誤りを修正し、経験から学ぶという再帰的なプロセスが不可欠である。本記事では、Transformerアーキテクチャにおける再帰的フィードバック機構と自己修正能力について、最新の研究動向を交えながら体系的に解説する。
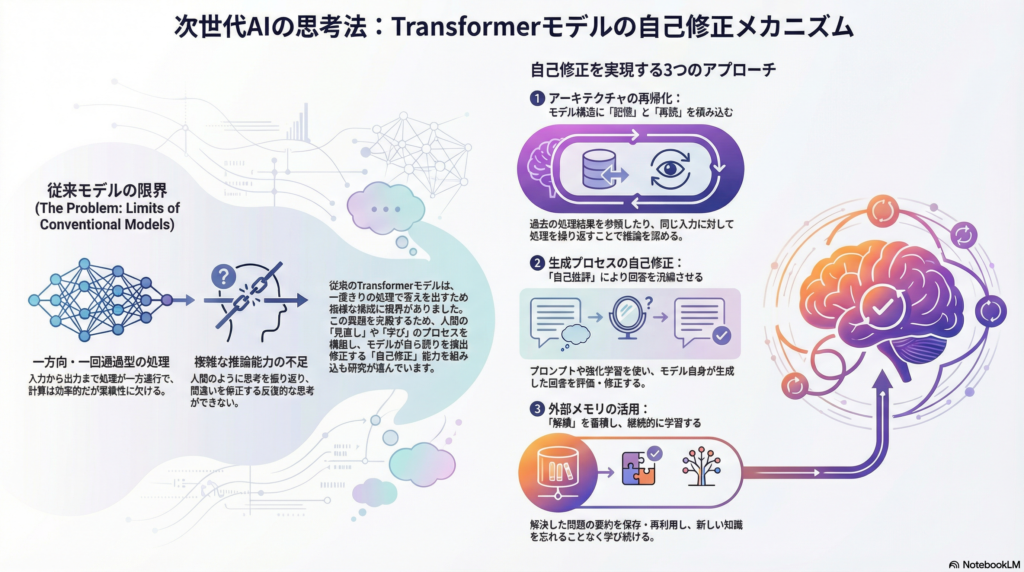
Transformerにおける再帰的フィードバックの必要性
従来型Transformerの構造的制約
標準的なTransformerモデルは、入力を受け取ってから出力を生成するまで、基本的に一方向かつ一回通過型の処理を行う。この設計は計算効率の面で優れているものの、複雑な推論や段階的な問題解決には限界がある。人間が難しい問題に直面したとき、一度考えてから見直し、修正を加えるという反復的思考を行うのとは対照的である。
フィードバックループがもたらす可能性
再帰的フィードバック機構を導入することで、モデルは自らの出力を評価し、必要に応じて修正を加えることが可能になる。これにより、単純な予測精度の向上だけでなく、論理的一貫性の確保、誤り検出能力の向上、さらには継続的な学習能力の獲得といった、より高度な知的機能の実現が期待される。
アーキテクチャレベルでの再帰的設計
Feedback Transformer:過去の表現を活用する
Feedback Transformerは、過去の高次抽象表現を現在の入力処理に再投入する「フィードバックメモリ」を導入したモデルである。具体的には、現在時刻の低レベル表現が、過去時刻の高レベル表現を参照しながら計算される仕組みになっている。
この設計により、RNNに似た再帰性がTransformer内部に組み込まれ、比較的小規模で浅い層構造のモデルであっても、言語モデリングや機械翻訳タスクにおいて性能向上が確認されている。従来のTransformerが時系列情報を位置エンコーディングに依存していたのに対し、Feedback Transformerは過去の処理結果を明示的に参照することで、より文脈に敏感な表現学習を実現している。
Universal Transformer:動的な推論深度の調整
Universal Transformerは、同一入力に対して複数回の反復処理を行うことで、推論の深さを動的に調整する機構を持つ。これは「再読」に相当するプロセスであり、難易度の高い推論タスクにおいて特に有効性が示されている。
通常のTransformerが固定された層数で処理を完了するのに対し、Universal Transformerは必要に応じて処理を繰り返すことができる。この適応的な計算量の調整により、簡単な問題には少ない計算で対応し、複雑な問題には十分な反復を行うという、効率的かつ柔軟な推論が可能になる。
タスク特化型の小規模再帰モデル
Hierarchical Reasoning ModelやTiny Recursive Modelといった研究では、論理推論やパズル解決に特化した小型Transformerが開発されている。これらのモデルは数百万パラメータ規模でありながら、内部状態を反復的に更新しながら解を洗練させることで、大規模モデルを上回る性能を示している。
ただし、これらのモデルには課題も存在する。特に、再帰的処理をいつ停止すべきかという「停止条件」の設計が重要であり、適切な条件設定がなければ、過剰な反復による計算コストの増大や、逆に不十分な処理による性能低下を招く可能性がある。
生成過程における自己修正機構
Self-Refine:プロンプトベースの自己批評
Self-Refineは、モデル自身に「自己批評」と「修正生成」を行わせるフレームワークである。最大の特徴は、追加の学習を必要とせず、プロンプト設計のみで実装可能な点にある。
このアプローチでは、モデルがまず初期回答を生成し、次にその回答を批評し、最後に批評を踏まえて改善された回答を生成するという三段階のプロセスを踏む。対話生成、数学的問題解決、説明文生成など多様なタスクで性能向上が報告されている。
しかし、Self-Refineの効果はモデルの自己批評能力に大きく依存する。モデルが誤った評価を行った場合、修正後の回答がかえって悪化するリスクがある。また、モデルが自身の限界を正しく認識できない場合、不適切な修正を繰り返す可能性も指摘されている。
SCoRe:強化学習による自己修正の内部化
SCoReは、自己修正行動そのものを強化学習によってモデルの内部能力として学習させる手法である。モデルは最初の回答と修正後の回答の両方を生成し、「改善が見られたか」を報酬シグナルとして学習する。
数学的問題やプログラミングタスクでは顕著な改善が確認されているが、訓練コストが高いという課題がある。また、定量的評価が困難な創造的タスクへの適用については、今後の研究が必要とされている。自己修正能力を獲得する過程で、モデルが誤った修正パターンを学習してしまうリスクも考慮する必要がある。
自己反省的デコーディング:事前的誤り抑制
SRGen(Self-Reflective Generation)は、生成途中でモデルの不確実性を監視し、誤りが生じやすい箇所で「振り返り」を行う方式である。これは事後的な修正ではなく、事前的な誤り抑制を目指す点に特徴がある。
具体的には、各トークン生成時のエントロピーを計算し、不確実性が高い箇所では一時的に立ち止まり、より慎重な生成を行う。この仕組みにより、誤った推論の連鎖を未然に防ぐことができる可能性がある。
継続学習を可能にする外部メモリアプローチ
Transformerにおける継続学習の課題
標準的なTransformerモデルは、訓練完了後は重みが固定され、新しい情報を学習する能力が失われる。これは「破局的忘却」と呼ばれる問題につながり、継続的な知識更新が困難になる。人間が経験から学び続けるのとは対照的に、現行のモデルは静的な知識に依存している。
動的外部メモリによる経験蓄積
ArcMemoなどの研究では、モデルが問題解決後に「概念的要約」を自然言語でメモリに保存し、次の課題で再利用する仕組みが提案されている。この方法には以下の利点がある。
まず、破局的忘却を回避できる点が挙げられる。重み更新を行わないため、既存の知識を損なうことなく新しい情報を追加できる。また、テスト時学習が可能になり、運用段階でも継続的に知識を拡張できる。
一方で、メモリの肥大化、誤った知識の蓄積、適切な検索と抽象化の困難さといった課題も存在する。特に、どの経験をメモリに保存すべきか、どのように効率的に検索するかという問題は、継続学習の実用化において重要な研究テーマとなっている。
メタ学習との関連性
文脈内学習自体が一種のメタ学習であると解釈でき、外部メモリはその拡張形と見なすことができる。ただし、自己生成データによる反復学習は「モデル崩壊」を引き起こす可能性があり、慎重な設計が不可欠である。人間の監督やフィルタリング機構を組み込むことで、質の高い知識蓄積を実現する必要がある。
創造的・科学的タスクにおける応用
創造的ライティングでの活用
創造的ライティングにおいて、再帰的フィードバックは「編集」「推敲」「構造の再検討」に相当する。自己反省プロンプトを用いることで、物語的一貫性、主題の明確化、キャラクター整合性の向上が報告されている。
人間の作家が初稿を書いた後に何度も見直すように、モデルも生成した文章を評価し、改善点を見出し、再生成することで、より洗練された創作物を生み出すことが可能になる。この過程は、単なる文法的正確性だけでなく、作品全体の芸術的完成度を高める方向に働く。
科学的推論と学術文書生成
査読応答文生成などのタスクでは、自己批評、知見蓄積、再生成という二重ループ構造が有効であることが示されている。これは科学的思考における「仮説検証ループ」に近い。
論理推論タスクでは、途中の思考を評価し選別しながら進める再帰的推論が高い精度を実現している。例えば、RDoLT(Recursive Depth-of-Logic Thinking)のような手法では、各推論ステップの妥当性を検証しながら段階的に解答を構築する。これにより、単純な連鎖推論では到達できない複雑な結論に至ることができる。
認知科学的・倫理的考察
メタ認知と内省の実装
再帰的フィードバック機構は、メタ認知や内省といった高次の認知機能と深く関係する。人間の知能は、自分の思考を対象化し、誤りを検出して修正し、経験を抽象化して蓄積するという性質を持つ。
自己修正可能なAIシステムは、より自律的で信頼性が高く、倫理的に調整可能なシステムへと近づく可能性がある。例えば、モデルが自らの出力の適切性を評価し、問題があれば修正を試みる能力は、AI安全性の観点からも重要である。
リスクと監査可能性
一方で、自己生成フィードバックの暴走、価値や目標のドリフト、説明可能性の欠如といったリスクも存在する。モデルが誤った方向に自己修正を繰り返した場合、人間が介入しにくい状況が生じる可能性がある。
そのため、再帰的自己修正には「監査可能性」と「人間との協調的ループ」が不可欠である。モデルの修正プロセスを透明化し、必要に応じて人間が介入できる仕組みを構築することが、安全で信頼できるAIシステムの実現には重要となる。
まとめ
Transformerモデルへの再帰的フィードバック機構の統合は、自己修正能力、継続学習、高次の創造的・推論能力を実現するための中核的要素である。アーキテクチャレベルでの再帰的設計、生成過程での反省的評価、外部メモリによる経験蓄積は、それぞれ異なるレベルで内的フィードバックループを形成し、より人間的な知的処理に近づく可能性を示している。
今後の研究課題としては、再帰性、安定性、安全性、意味理解を同時に満たす統合的枠組みの構築が挙げられる。これはAGI研究および人工意識研究において極めて重要な理論的テーマであり、認知科学、神経科学、哲学といった分野との学際的な対話を通じて、より深い理解が進むことが期待される。
コメント