はじめに:なぜ今、オープンサイエンスとAI研究プラットフォームの統合が重要なのか
AI研究の加速に伴い、膨大なデータセット・モデル・実験ログが日々生み出されている。しかしその多くは、属人的な管理や断片化したツール群に散在し、再現性の確保や透明性の担保が難しい状況に置かれている。
そこで注目されるのが「オープンサイエンス」の考え方だ。論文・研究データ・コード・プロトコルをオープンライセンスのもとで共有し、誰もが再利用・再配布・改変できる環境を整える——この枠組みをAI研究プラットフォームと統合することで、研究の再現性と信頼性を飛躍的に高める可能性がある。
本記事では、統合の全体像を「プラットフォーム比較」「技術要件」「ガバナンス・法務」「実装ロードマップ」「ケーススタディ」「推奨アーキテクチャ」の順に整理する。
オープンサイエンスとAI研究プラットフォームの現状と課題
オープンサイエンスの定義と範囲
オープンサイエンスは、論文・研究データ・メタデータ・教育資源・ソフトウェア/ソースコードへのオープンアクセスを包括する国際的な枠組みとして定義・推進されている。オープンライセンスにより再利用・再配布・改変が可能であることが前提条件だ。
さらに、FAIR原則(Findable・Accessible・Interoperable・Reusable)は、データを「機械可読・機械処理可能」にする設計要件として国際標準となっており、自動パイプラインやAIエージェントとの相性が高い点でAI研究との親和性は大きい。
AI研究プラットフォームの多層構造
一方、AI研究プラットフォームは単一サービスで完結しづらい。クラウド計算・データレイク・実験追跡・モデルレジストリ・共同開発機能など複数コンポーネントを横断する「研究基盤」として運用されることが多く、各機能を別々のツールで担うケースが一般的だ。
この構造的な分散こそが、統合を難しくしている本質的な要因の一つといえる。
主要プラットフォームの機能比較|統合設計に必要な視点
統合を設計するうえで最初に把握すべきは、各プラットフォームの「強み」と「弱み」の違いだ。
コード・研究成果系プラットフォーム
GitHubは、Gitベースの共同開発・CI/CD・Issues/PRなど研究コードの標準基盤として機能する。Zenodo連携によりリリース単位でDOIを付与でき、学術引用を可能にする点が強い。ライセンスはSPDX識別子で機械可読化することが推奨される。
Zenodoは、学術成果の長期保存とDOI付与に特化した公開アーカイブだ。GitHub連携でリリースを自動アーカイブでき、無償でアップロード・アクセスが可能な点が研究者に受け入れられやすい。ただし、計算機能は持たず、あくまで「引用・保存の受け皿」として位置づける必要がある。
Hugging Faceは、モデル・データセット・デモの公開・共同開発ハブとして機能する。Model Cardによるドキュメント化、組織RBAC・SSOによるアクセス制御、トークン認証など、AI成果の配布と管理を一体化できる点が特徴的だ。
研究ワークフロー・データリポジトリ系
**OSF(Center for Open Science)**は、研究の計画から成果公開までのライフサイクルを管理できるプロジェクト基盤だ。公開・非公開の段階制御、エンバーゴ設定など、研究過程の透明性確保に強みを持つ。無償・オープンソースで提供されている。
Dataverseは、機関・分野別の研究データリポジトリとして機能する。Dublin Core・DDI・DataCiteなどの標準メタデータをサポートし、OAIプロトコルによる外部連携がしやすい構造になっている。
MLOps・AI基盤系
Google Cloud Vertex AI(旧AI Platform)は、学習から配備・追跡まで統合したMLOps基盤だ。実験追跡・モデル版本管理・パイプライン・マネージドトレーニングを備え、IAMに基づくアクセス制御やラインエージ追跡機能も持つ。ただし、研究成果のライセンス管理は外部に委ねる必要がある。
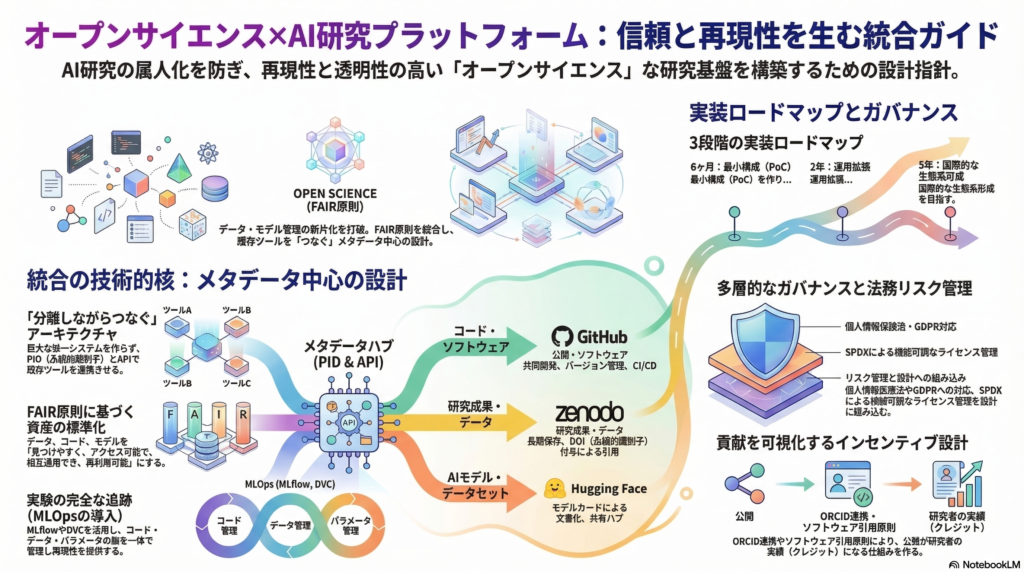
統合設計の核心:「分離しながらつなぐ」
各プラットフォームの強みが異なる以上、「1つの巨大システム化」ではなく、永続識別子(PID)+標準メタデータ+API連携+ガバナンスで”つなぐ”設計が現実的だ。公開・引用・保存と、開発・運用、AI共有、研究ワークフローをそれぞれ分離しつつ、メタデータとIDで統合する構成が長期的な安定性を生む。
技術要件と参照アーキテクチャ|FAIRを軸にした統合設計
技術要件チェックリスト
統合の技術要件は「資産(データ・コード・モデル・実験)」をFAIR原則に沿って揃えることに集約される。主要カテゴリと推奨標準を以下に整理する。
| 要件カテゴリ | 推奨標準/技術 |
|---|---|
| メタデータ(汎用) | Dublin Core(DCMI Terms) |
| Web発見性 | schema.org/Dataset(JSON-LD) |
| 永続識別子(PID) | DataCiteメタデータ(DOI登録) |
| 認証・認可 | OAuth/OIDC、ORCID OIDC |
| バージョン管理(データ・モデル) | DVC(Git履歴と連結) |
| 実験追跡 | MLflow Tracking+Model Registry |
| ワークフロー再現性 | CWL(Common Workflow Language) |
**永続識別子(DOI)**は、研究成果を”引用可能な単位”として固定するうえで不可欠だ。DataCiteメタデータにより、データセット・ソフトウェア・モデルなど多様な成果物を学術的に引用可能にできる。
実験追跡では、MLflow Trackingを用いてパラメータ・指標・成果物・コード版をログに残す構成が実績ある選択肢だ。データ・モデルの版はDVCでGit履歴と結合することで、「どのコードで・どのデータを使い・何を生成したか」を一体で追跡できる。
ワークフロー再現性については、CWL(Common Workflow Language)が可搬・再現可能な記述標準として機能する。実験を”提出物”として記述し、入力データ版・コード版・環境・出力を一緒に管理することで、他者による再実行を現実的なものにできる。
参照アーキテクチャの要点
メタデータ中心の統合アーキテクチャでは、各リポジトリやAI基盤を置き換え可能にしつつ、統合の”要”をメタデータ(Dublin Core / schema.org / DataCite)とPID(DOI等)、および実験追跡(MLflow等)に置く。
具体的には、組織IdPとORCIDによるアイデンティティ管理を起点に、コードリポジトリ・研究データリポジトリ・公開リポジトリをメタデータストアと統合カタログに接続し、AI研究基盤(データレイク・計算・追跡・レジストリ)との間でポリシーと監査ログを横断管理する構成が基本形となる。
ガバナンス・法務・倫理|「公開すればよい」では済まない理由
データプライバシーと越境移転
統合プラットフォームが国際共同研究を想定する場合、日本の個人情報保護法(APPI)とGDPR双方への対応が求められる可能性がある。データ分類(個人情報・仮名化情報・匿名加工情報・機微情報)と、越境移転(クラウドリージョン・委託先・再委託)を含む責任分界は、設計の初期段階で固める必要がある。
「匿名化=安全」という前提は危険だ。Netflix Prizeのケースでは、匿名化された研究用データが外部情報と突合され、再同定可能と分析された事例がある。公開前の再同定リスク評価と共有範囲設計が必須といえる。
ライセンス互換性の設計
コード・データ・論文本文・モデル重み・学習データの由来は、それぞれ異なる権利・契約に支配される可能性がある。統合プラットフォームは、資産タイプごとに許諾・再利用条件を分離記録し、検索・取得APIにも反映する設計が求められる。
コードライセンスはSPDX識別子で機械可読化し、データ・文書にはCreative Commonsライセンス(CC0等)を活用するのが実績ある組み合わせだ。ImageNetの事例では、画像の著作権を保有しないことでアクセス制限・再配布困難が発生し、再現性確保が難化した経緯がある。許諾・アクセス経路を前提にした設計の重要性が示された例だ。
AIガバナンスと説明可能性
NIST AI RMFは「GOVERN / MAP / MEASURE / MANAGE」の機能群でリスク管理を体系化しており、継続的レビューを前提とした生きているドキュメントとして整備されている。日本でも総務省・経済産業省のAI事業者向けガイドラインが統合・更新されており、AIガバナンス構築と主体別取組事項が整理されている。
統合プラットフォームにおける実装上の要点は、(1) データ・モデルの由来(プロベナンス)と利用条件、(2) 実験ログ、(3) デプロイ後の監視、(4) インシデント対応を、監査可能な形で結び付けることにある。
撤回リスクへの備え
MIT CSAILのTiny Imagesは、自動収集・ラベル付けで差別語カテゴリや不適切画像が混入し、撤回・削除要請に至った代表的な事例だ。公開後の削除要請・差し替え手順と、版のネーミングおよびDOI等による参照の不変性を、運用設計の段階から組み込む必要がある。
実装ロードマップ|短期・中期・長期の段階設計
短期(0〜6か月):統合の”芯”を作る
まず優先すべきは以下の5点だ。
- 資産種別の定義:データ・コード・モデル・論文・プロトコルを類型化する
- メタデータ最小プロファイルの策定:Dublin Core+DataCite+schema.orgのマッピングを行う
- 認証・認可のPoC:OIDC/SSOと外部研究者ID(ORCID)連携の方針を固める
- 実験追跡・版管理の最小構成:MLflow/DVCを導入し追跡の骨格を作る
- 公開フローの標準化:GitHub→Zenodo DOIの手順を整備する
中期(6か月〜2年):運用を拡張する
統合カタログを本格稼働させ、検索と権限反映を実装する。ワークフローはCWL等で標準化し、再現可能パイプラインを”提出物”として扱う仕組みを整える。監査ログ・インシデント対応・削除要請の運用体制もこのフェーズで確立する。
KPI設計も重要で、「量」だけでなく「再現性成功率(指定ワークフローが再実行できた割合)」「実験追跡のカバレッジ(ログ欠落率)」「ライセンス情報欠落率」などの質的指標を持つことが望ましい。
長期(3〜5年):生態系を形成する
分野別メタデータの拡張と相互運用、国際的なAI・著作権・プライバシー規制への継続的な適合、外部コミュニティとの共同ガバナンスを進める。資金調達も、公的資金を初期の軸にしつつ、組織向けサブスクリプションや学会・財団との共同スポンサーを組み合わせたミックス型が長期安定性につながりやすい。
必要な人員・役割の目安
短期に最低限必要な役割は、プロダクト/アーキテクト・データエンジニア・MLOpsエンジニア・セキュリティ/IAM担当・データスチュワード/キュレーター・法務/コンプライアンスの6職能だ。フェーズが進むにつれて専任比率を高めていく構成が現実的といえる。
インセンティブ設計|公開を「続く仕組み」にするために
公開が継続するためには、貢献が学術的クレジットとして評価される仕組みが不可欠だ。
FORCE11のデータ引用原則(Data Citation Principles)とソフトウェア引用原則(Software Citation Principles)は、引用を機械可読かつ学術的クレジットに繋げる枠組みを提示している。CITATION.cffはソフトウェアおよびデータセットの引用情報を人間・機械双方が読める形で記述する仕様として整備されており、リポジトリ運用における引用の標準化を支える。
また、研究者のORCID連携により、共同研究者の寄与者同定と権限付与を明確に分離できる。外部研究者を巻き込む際の認証連携基盤としても有効だ。
まとめ:統合成功のカギは「メタデータ中心設計」と「運用の制度化」
オープンサイエンス資産とAI研究プラットフォームの統合において、成功確率を高める要素は技術選定よりも設計思想と運用体制にある。
本記事のポイントを整理すると以下のとおりだ。
- FAIR+永続識別子(DOI)を軸にしたメタデータ中心設計が基盤になる
- ライセンス互換性はコード・データ・モデルで別管理が必要
- 実験・データ・モデルのラインエージを一体で残すMLOpsが再現性を担保する
- プライバシー・有害性・撤回リスクへの運用設計を公開前から組み込む
- 引用・貢献の可視化によるインセンティブ制度化が継続的な公開を支える
各プラットフォームを「1つに統合」しようとするより、それぞれの強みを活かしながらメタデータとIDで”つなぐ”設計が、長期的な持続可能性を生む可能性が高い。
コメント