マルチモーダルAIが記号論にもたらす新たな地平
テキストから画像、音声、動画まで多様なコンテンツを生成するマルチモーダルAIの登場は、記号論の枠組みに根本的な問いを投げかけている。GoogleのGemini 3のような高度なモデルは、異なる記号体系を横断的に結びつけ、従来の言語中心の記号理論では説明しきれない現象を生み出している。本稿では、ソシュールの記号論を軸に、AI生成コンテンツが視覚記号や意味生成にもたらす影響を多角的に考察する。
ソシュールの記号論とマルチモーダル生成の接点
シニフィアン/シニフィエ関係の拡張
ソシュールの記号理論では、記号は能記(シニフィアン)と所記(シニフィエ)から構成され、その結び付きは本質的に恣意的であるとされる。言語記号において音声や文字は概念を指し示すが、この結合に必然性はない。この枠組みは当初、言語を中心に構築されたものだった。
マルチモーダルAIは、この古典的枠組みに新たな次元を加えている。テキストプロンプト(言語的シニフィアン)を入力すると、それに対応する画像や音声(視覚的・聴覚的シニフィエ)が生成される。建築デザイン分野の研究では、プロンプト内の語彙選択や組み合わせが視覚出力に影響を与えることから、言語記号と視覚記号の間に統辞的(シンタグマ)・連想的(パラダイム)な構造が存在する可能性が示唆されている。
この過程は「描画を言語のように扱う新たな視点」を提供するものとされる。AIは異なる記号体系を橋渡しし、シニフィアンからシニフィエへの動的な変換を実現することで、従来の記号論的枠組みを拡張している。
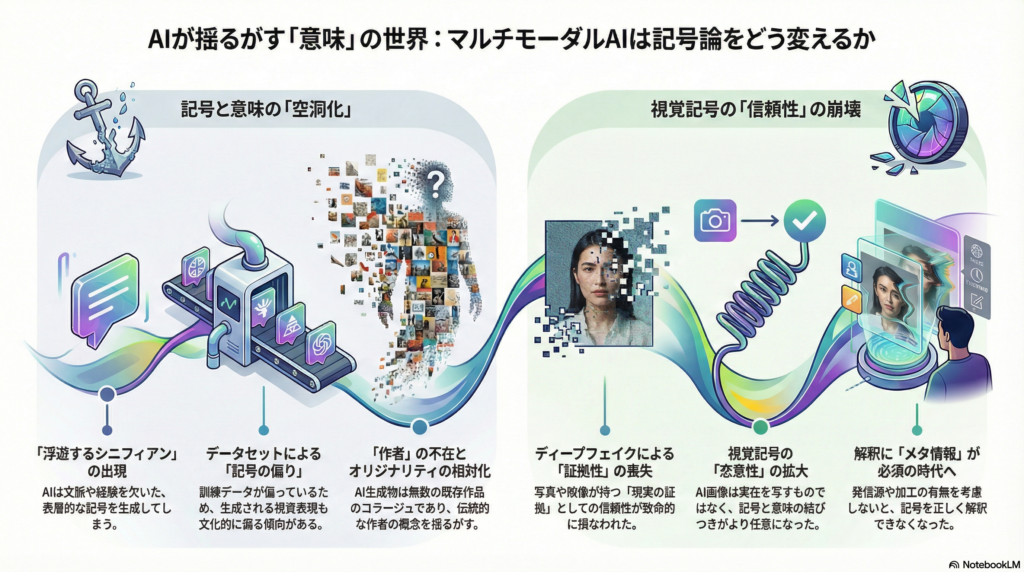
浮遊するシニフィアンという問題
しかし、マルチモーダルAI生成コンテンツは「浮遊するシニフィアン」という理論的課題も提起する。AIは人間の指示したスタイルで画像や音声を巧みに模倣できるが、その背後に人間の生活経験や文脈に根ざした確固としたシニフィエが伴わない場合がある。
音楽生成AIの研究では、この問題が明確に指摘されている。生成された音楽は技術的に精巧で様式的特徴も正確だが、文化的・文脈的な深みを欠いた「浮遊するシニフィアン」に留まる。AIは特定の音楽様式を表面的に再現できても、それが本来持つ歴史的・社会的文脈や「生きられた経験」に根差す意味までは再現できない。
その結果、生成コンテンツには文脈的基盤や文化的真正性、歴史的意識が欠如し、記号の意味生成プロセスに齟齬が生じる可能性がある。AIによるマルチモーダル生成は、シニフィアンとシニフィエの伝統的関係性を揺るがし、新たな記号論的課題を突き付けている。
AI生成記号における作用主体と意図性の問題
記号創出の動機づけをめぐる理論的難問
生成AIがプロンプトに応じて視覚画像や音声を自律的に創出する際、その記号作用(セミオーシス)は従来の人間中心モデルと大きく異なる。社会記号論では、記号は人間という「記号作用主体」の意図に基づき選択・構成されるため、動機づけられていると考えられてきた。
ところがAIが自律生成したマルチモーダル記号の場合、直接の生成過程に人間の創作者の意図性が存在しない。「その記号は動機づけられていないのではないか」という理論的難問が提起されている。AIシステムが出力する画像や音声には、人間が作品を制作する際に込める主観的意図や意味操作が介在しないため、記号論的には従来の枠組みで説明しにくい側面が生じる。
この問題に対し、Tomalinはマルチモーダル社会記号論の理論枠組みを改訂することで対応できると論じている。記号の「デザイナー」(人間の企図主体)と「制作者」(実際に記号を物質的に実現する主体)を階層的に分離し、AIを後者の記号制作者として位置づける提案である。
人間のデザイナーが意図と意味構想を記号設計に投影し、AIなどの自動システムがその設計を具体的な視覚・聴覚記号に実現するという二段構えのモデルにより、AI生成記号も人間の社会的文脈における「動機づけられた記号」として分析可能になる。
記号内容の偏りとデータセット依存性
AI生成記号がもたらす意味論的インパクトとして、記号内容の偏りが挙げられる。AIは大量の訓練データに基づいて出力を行うため、生成される視覚記号にはデータセットの偏りが反映されやすい。
拡散モデルを用いた建築デザインのテキスト-to-画像生成研究では、ユーザが用いるプロンプトの語彙を分析したところ、建築家や美術様式の名前などシニフィアンの多くが西洋中心的であり、非西洋の文化的記号が著しく少ないことが報告された。
この「シニフィアンの偏り」は生成される画像(シニフィエ)にも影響を与え、結果としてAIの視覚的アウトプットは文化的多様性に乏しく、記号表現が一面的になる傾向がある。重要なのは、これが人間の意図的な偏向ではなく、利用可能な訓練データの偏在に起因する「半ば自律的な記号偏向現象」である点だ。
このようなAI記号生成の偏りは社会における視覚記号の意味体系にも影響を及ぼし、非西洋文化の表象がますます周縁化されるといった問題につながる可能性がある。
視覚記号の信頼性と解釈環境の変容
ディープフェイクと証拠性の崩壊
AI生成コンテンツの氾濫は、視聴者側の意味解釈や信頼性の文脈にも変革を迫っている。とりわけディープフェイクを含む高度にリアルなAI生成画像・映像の出現は、写真や録音・録画といったメディアに伝統的に付与されてきた「証拠性」や「指標性」を揺るがしている。
Cittonは、ディープフェイクの登場が「現実を指示する索引的表象に抱かれてきた信頼に対し致命的な一撃を与えた」と述べている。もはや目に見える映像や写真がそれ自体で現実の確証とはならず、常に「それはAIによる捏造かもしれない」という解釈の留保が付きまとう状況が生まれた。
この変化は記号解釈の社会的文法を変容させている。視覚記号の受容において受け手は、発信源や加工の有無といったメタ情報を考慮せざるを得なくなっている。AIが生成した画像・音声によるフェイクは、従来の記号体系では結び付かなかったコンテクスト同士を結合しうるため、受け手の意味解釈プロセスに混乱や新たな読み取り規範の必要性を生んでいる。
作者性とオリジナリティの相対化
生成AIは過去のデータを学習して新たなコンテンツを作り出すため、その成果物には過去の無数の作品の要素が織り込まれている。バルトの「作者の死」の概念になぞらえれば、AIによるテキストや画像はまさに「無数の既存表現のコラージュ」であり、伝統的な意味での創造的作者が不在のテクストとも言える。
教育分野の研究では、チャットボットAIが生成する文章はあらゆる既存テキストの引用網から成る「パスティーシュ」であり、それを学生のオリジナルな答案と見なせるのかという批判が提起されている。AIは記号表現の担い手として新たな主体となった反面、従来の記号生成過程において暗黙裡に保証されていた作者の存在やオリジナルであることの価値を相対化した。
視覚芸術においても、誰の手も介さず高精細な画像が生成できる現在、作品の意味や価値は「誰が作ったか」よりも「どの文脈で消費・解釈されるか」にシフトしつつあるとの指摘がある。この変化は記号の送り手・受け手関係や意味の所在に関する社会的コンセンサスに影響を与えている。
恣意性と差異の体系の再解釈
視覚記号における恣意性の拡大
ソシュール記号論の柱である「記号の恣意性」は、マルチモーダルAIによって新たな意味を帯びている。言語記号ではシニフィアンとシニフィエの結び付きは自然必然ではなく社会的約束事だが、視覚記号の場合、記号表現が対象に似ているというアイコニックな特徴から、その関係は恣意的でないようにも思える。
バルトは写真を「メッセージ性なきメッセージ」と呼び、その指示対象との機械的・物理的な結び付きを強調した。しかしAI生成画像の台頭によって、この図式は揺らいでいる。AI画像は現実に「かつて存在したもの」を写し取ったのではなく、データをもとに合成されたものであり、たとえ写真風であっても何ら実在の指示対象を持たない。
写真がかつて持っていた索引記号的な裏付け(「それがそこにあった」という存在の保証)が失われることで、視覚記号もテキストと同様に純粋に恣意的なシニフィアン=シニフィエ関係の産物と捉え直す必要が生じている。AIが生成した顔写真は実在しない人物のものであるにもかかわらず我々に「誰か」を連想させるが、その「誰か」とシニフィアンたる顔画像との関係には社会的約束事以上のものはない。
差異体系の変容と新たな意味軸
「差異の体系」による意味生成についても再検討が必要である。ソシュールは記号の意味(価値)は他の記号との体系的な差異関係から生まれると論じた。AIが無数のバリエーション画像や架空の映像を生み出せる時代、視覚記号の意味体系にどのような変容が起きるのか。
生成モデルは既存のカテゴリの中間や融合を容易に作り出すため、これまで明確だった記号間の区別が滑らかに接続されうる。その結果、記号同士の差異に基づく従来の分類体系が再考を迫られる可能性がある。テキストプロンプトでは単語を入れ替える(パラダイム差異)だけで出力画像の内容が大きく変化し、語順や文法構造の違い(シンタグム差異)によっても解釈が異なる画像が生成される。
これは視覚記号の世界に言語的な差異体系が持ち込まれた現象であり、両者の記号体系が相互に絡み合う新たな意味ネットワークが形成されつつあることを示唆する。差異に基づく価値づけは社会的文脈でも変化しており、「AI生成か人間制作か」という出自の差異自体が記号の解釈や価値判断において重要な意味を持ちはじめている。
記号論モデルの拡張と新理論の模索
既存理論の適応と階層化
従来の記号論モデルをアップデートする試みとして、人間以外の記号作用主体を組み込む理論修正が進んでいる。マルチモーダル社会記号論における記号創出階層の再編は、人間の意図を上位に置きつつAIを下位の実現主体と位置づけることで、AI生成記号も理論的に説明可能にした。
記号の動機づけ概念についても再評価が進んでいる。視覚記号や身体記号などでは記号内容との類似性ゆえに「動機づけ」が論じられてきたが、AI時代には人間が直接介在しない記号創出にも何らかの動機づけ原理を見出す必要がある。それには記号の設計者の意図や、社会全体の需要・傾向といったマクロの要因を考慮したモデルが求められる。
記号論は個々の記号対だけでなく、記号生成を取り巻くエコシステム(データセット、アルゴリズム、ユーザ文化など)まで含めた体系へと拡張されつつある。
新たな記号理論の可能性
AIが生成する記号の特殊性は、全く新しい記号理論の構築を促す可能性もある。記号内容の空洞化現象(浮遊するシニフィアン)に対処するためには、従来のように記号内部の関係性を分析するだけでは不十分かもしれない。
文化記号論や意味論の領域では、AIが生み出す表面的には意味ありげな記号列に本当に「意味」が宿りうるのかという根源的問いが提起されている。「AIは作曲できるか」ではなく「AIは意味を創出できるのか」という問題設定へのシフトは、記号とは何かを再定義する試みとも言える。
この問いに答えるには、ソシュールやパースといった古典的理論の枠を超えて、受け手の解釈行為や文化的文脈、さらには機械学習システム内部の表現形式まで統合的に説明できる新たな理論装置が必要になる可能性がある。人間とAIが共同で意味を紡ぎ出す現代の記号環境を捉えるには、「ポストヒューマン的記号論」や「計算記号論」といった新機軸の理論を模索する動きもみられる。
まとめ:記号論的理解の深化に向けて
マルチモーダルAI時代の生成コンテンツは、ソシュールの記号論に多層的な問いを投げかけている。シニフィアン/シニフィエの枠組みはテキスト・画像・音声が横断的に結び付く現象を説明するため拡張を迫られ、視覚記号の恣意性や差異に関する従来の理解も再考を要している。
AIが自律的に生み出す視覚・聴覚記号は、人間の意図を介さないがゆえに意味の空白や文脈の喪失を招く一方、受け手側の解釈や社会的意味ネットワークに新たな層を加えつつある。記号論的モデルの改良や新理論の模索が始まっており、AIを記号作用の一部として包含した包括的なセミオティクスが模索されている。
最終的に問われるのは、「記号とは何か」「意味はいかに生成されうるか」という記号論の根本問題である。マルチモーダルAIが生成するコンテンツは、この古くて新しい問題に対し、理論と実証の双方から再挑戦する機会を提供している。記号の本質と機能をアップデートして捉え直す姿勢が、今後の記号論研究に求められている。
コメント