大規模言語モデルにおける可塑性機構とは
近年、ChatGPTをはじめとする大規模言語モデル(LLM)は目覚ましい進化を遂げていますが、人間の脳が持つ「学びながら学ぶ」能力との間には大きなギャップが存在します。現在のLLMは学習フェーズと推論フェーズが明確に分離されており、推論中に新しい情報を長期的に記憶することができません。
この課題を解決するため、神経科学における**可塑性(Plasticity)**の概念をAIモデルに統合する研究が活発化しています。可塑性とは、脳のシナプスが経験に応じて結合強度を変化させる性質を指し、これによって私たちは日々新しいことを学び続けることができます。
本記事では、LLMに可塑性機構を統合する主要な4つのアプローチと、それぞれの利点・限界、さらにGPT系モデルへの実装可能性について解説します。
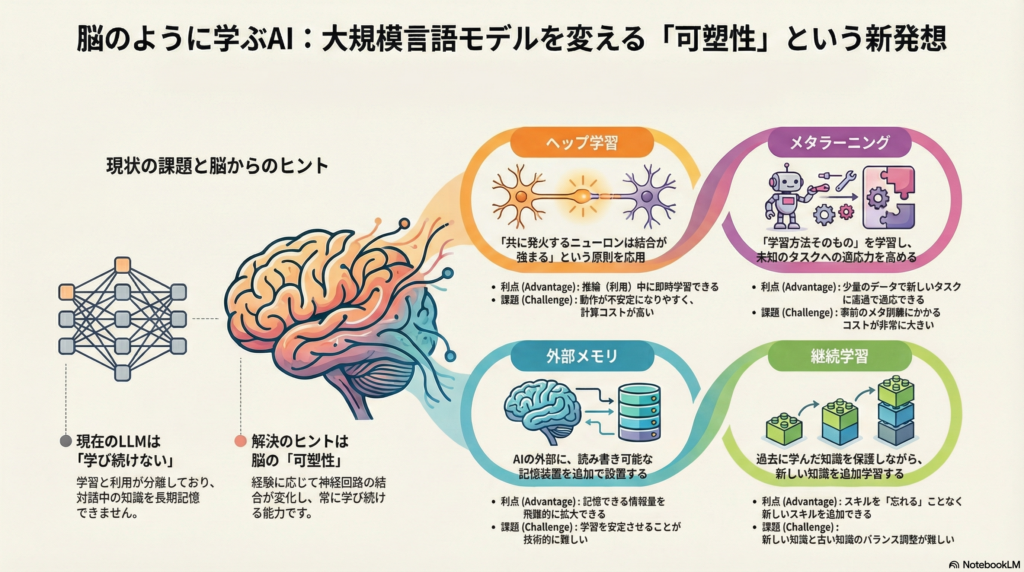
可塑性統合の主要アプローチ4選
Hebbian学習による動的重み更新
Hebb則(「一緒に発火するニューロンは結合が強まる」)に基づくアプローチでは、モデルの重みを活動に応じて動的に変化させます。Miconiらによる「Differentiable Plasticity」研究では、再帰型ネットワークに学習可能なHebbian結合を導入することで、従来の静的ネットワークでは解けなかった長期記憶タスクの解決に成功しました。
主な利点として、推論中にモデル自身が経験に応じて重みを書き換えることで、外部から勾配逆伝播を行わなくても即座に学習できる点が挙げられます。これは真のオンライン学習やライフロングラーニングに近い振る舞いを可能にし、一度きりの経験からの素早い適応能力を向上させます。
一方で限界も存在します。勾配降下で最適化されたモデル重みとHebbianによるオンライン更新が干渉し、システムが不安定になるリスクがあります。また、LLMのような超大規模モデル全体に適用するには計算コストが莫大で、現実的には全結合を可塑化することは困難です。さらに、Hebbian更新は基本的にタスク固有の報酬や誤差信号を直接使えないため、望む動作をするよう調整するには工夫が必要となります。
メタラーニング(MAML)を活用した適応力強化
**MAML(Model-Agnostic Meta-Learning)**は、様々なタスクでの訓練を通じて「微小な勾配ステップで新タスクに適応できるようなモデルパラメータ」を学習する手法です。内側のループで各タスクに対する少数ステップの勾配降下適応を行い、外側のループでその適応後の性能が良くなるよう初期重みを更新する二段階最適化を実施します。
この手法により、少量のデータや短時間の追加学習で高い性能を発揮できるようになります。LLMに適用すれば、ドメイン適応やユーザ個人化を極少の追加学習で行える可能性があり、既存知識を活かしつつ新知識を迅速に取得する手段として有望です。
ただし、メタ訓練自体のコストが非常に高い点が課題です。多数のタスクに対する内ループ・外ループの最適化は計算・データ量を要し、大規模モデルでは現実的に困難な場合があります。また、タスク間の分布シフトが大きい場合には初期重みの汎化が難しく、GPTのように極めて多様な知識を内包したモデルでは「全てに素早く適応可能」な初期状態を得るのは容易ではありません。
外部メモリ統合による記憶容量拡大
**Neural Turing Machine(NTM)**に代表される外部メモリアプローチでは、モデル内部に可微分な記憶装置を組み込み、ネットワークが読み書き操作を通じて情報を保持・想起できるようにします。NTMやその拡張であるDifferentiable Neural Computer(DNC)により、ニューラルネットはアルゴリズム的な長期記憶操作を自己学習できるようになります。
外部メモリの導入によりネットワークの記憶容量を飛躍的に拡大でき、通常のTransformerが固定長のコンテキスト内でしか過去情報を保持できないのに対し、過去の重要情報を書き留めておき必要時に参照することが可能になります。実際、NTMはLSTMだけでは困難なコピーやソートといったタスクを学習で獲得できたと報告されています。
しかし、大容量の可微分メモリは学習の安定化が難しく、勾配消失・発散や最適化の困難さが指摘されています。また、Transformerの自己注意機構が類似機能をより高速に実現してしまったため、NTM系の複雑な手法は相対的に評価が低下した面もあります。外部メモリの読み書き演算は計算コスト・メモリ帯域を圧迫し、推論遅延の増大につながる点も課題です。
継続学習で破滅的忘却を防ぐ
**Elastic Weight Consolidation(EWC)やSynaptic Intelligence(SI)**といった継続学習手法では、モデルをタスク順次学習させる際に「破滅的忘却」を防ぐ仕組みを導入します。EWCは各重みに対し過去タスクでの重要度を評価し、その重みが新タスクで大きく変化するとペナルティを課すことで、以前のタスクで培った知識を保護します。
これらの手法により、一度学んだスキルを維持したまま新たなスキルを追加学習できる可能性が広がります。正則化アプローチは追加のモデル容量を必要とせず既存重みの更新制御で忘却を防ぐため、大規模モデルにも比較的組み込みやすいという利点があります。
一方で、重み重要度の推定にはタスク毎の追加計算が必要で、出力次元が大きいLLMでは近似計算でもコストがかかります。また、正則化を強くしすぎると新タスクの学習自体が阻害され、弱すぎると忘却を防げないというジレンマがあります。LLMの知識更新は明確なタスク区切りがない連続データで行われることも多く、その場合「何を保持すべき過去知識」とみなすかの自動判定が難題となります。
神経科学から学ぶ可塑性の時間スケール
脳のシナプス可塑性には、数ミリ秒から数分程度の短期可塑性と、数分以上持続する長期可塑性という異なる時間スケールが存在します。短期可塑性は作業記憶や感度調節に関与し、長期可塑性(長期増強LTPや長期抑圧LTD)は学習と記憶の神経基盤となっています。
興味深いことに、**スパイクタイミング依存可塑性(STDP)**という機構では、プリシナプスとポストシナプスの発火タイミング差に依存してシナプス重みが調整されます。プリシナプスの発火が直前に起きてポストシナプスが直後に発火した場合、そのシナプスは強化され、逆の場合は弱化します。この短期的な活動パターンが繰り返されることで、結果的にLTP/LTDという長期変化を引き起こすのです。
最近の研究では、Transformerの自己注意機構が短期Hebbian学習と等価である可能性が示唆されています。ニューロンが発火タイミングの一致した入力を一時的に強く結合し、他の入力より優先して下流へ情報を伝達する機構で、Transformer型の動的選択が再現できるというものです。
現状のLLMは短期適応(コンテキスト依存)のみで、長期変化はオフライン学習に依存していますが、可塑性機構の統合により、推論中の短期変化が蓄積して長期学習に寄与する新たな学習スキームが期待されています。
GPTへの可塑性導入の実現可能性と課題
実装方法と既存重みとの整合性
既存の学習済みGPTモデルにも可塑性機構を後から組み込むことは可能です。現実的なアプローチとして、GPTの各Transformerブロックに「可塑性層」を増設し、その層の出力がHebb則等で一時的に変化するようにする方法が考えられます。
Duanらによる「Plastic Transformer」研究では、通常のTransformerと同程度のパラメータ数で重み可塑性機構を備え、メタ的に訓練することで推論中に重みが変化するにもかかわらず安定してタスクをこなせるよう工夫されています。
重要なのは、事前学習済みの重みとの兼ね合いです。可塑性機構を導入すると、モデルは静的知識による応答と動的更新による適応という二種類の学習動作を示すようになります。この際、元のGPTの重みで符号化された膨大な知識を壊さずに可塑性を働かせる必要があります。
アプローチの一つは、可塑性を働かせる部分と守る部分を明確に分けることです。例えば出力層付近の一部結合だけ可塑性ありにするか、追加のメモリモジュール部分だけ重みを変えてコアのTransformer重みは固定にするといった設計が考えられます。
性能向上と技術的障壁
適切に可塑性を導入できれば、GPT系モデルのタスク適応力と記憶力が向上すると期待されます。ユーザが対話中に提供した新情報を即座に覚え込み、その知識を活用して応答を改善するといったインタラクティブな学習が可能になる可能性があります。
小規模モデルでの実験では、可塑性を入れると一度見たサンプルを記憶して将来再現できるようになったり、学習時に経験しなかった新タスクに対しても少ない試行で適応できるようになることが確認されています。
ただし、計算コストと安定性が大きな課題です。Hebbian更新を各層で行う場合、順伝播毎に重み行列の更新演算が発生し、推論速度は低下します。また、推論中にモデル内部が変化するという性質上、入力系列によって内部状態が分岐し、予測不可能な振る舞いや累積誤差が発生するリスクがあります。
これらの暴走を防ぐ仕組みとして、ゲーティング制御や学習率制限、特定の条件下でのみ可塑性を適用するニューロモジュレーター的な要素が有効とされています。
まとめ:可塑性統合がもたらすAIの未来
大規模言語モデルへの可塑性機構統合は、AIに「学びながら学ぶ」能力を持たせる革新的なアプローチです。Hebbian学習による動的重み更新、メタラーニングによる適応力強化、外部メモリ統合、継続学習による忘却抑制という4つの主要手法には、それぞれ独自の利点と限界があります。
神経科学の知見を活用し、短期・長期可塑性の時間スケールをモデルに組み込むことで、より人間らしい適応的知能に近づく可能性があります。GPTへの実装は技術的課題を伴いますが、部分的な可塑化やゲーティング制御などの工夫により、実用化への道筋が見えてきています。
2025年時点では可塑性機構を備えたLLMはまだ研究段階ですが、小規模Transformerでの成功例が報告されており、今後の大規模化と安定性向上が期待されます。脳に学んだプラスチックなAIという ビジョンに向けて、着実に研究が進展しているといえるでしょう。
コメント